今天介绍一篇由中国肉类食品综合研究中心的Jing Qi等人发表于Food Chemistry的一篇研究型文章。作者对中国七个地区的猪肉样品进行矿物元素分析,并引入机器学习方法,得到了一个高性能的产地可追溯性模型(前馈神经网络,95.71%的整体准确率和曲线下面积接近1),证明了通过矿物元素指纹分析可追溯一个国家内不同猪肉产地的可行性。
今天介绍一篇由中国肉类食品综合研究中心的Jing Qi等人发表于Food Chemistry的一篇研究型文章。作者对中国七个地区的猪肉样品进行矿物元素分析,并引入机器学习方法,得到了一个高性能的产地可追溯性模型(前馈神经网络,95.71%的整体准确率和曲线下面积接近1),证明了通过矿物元素指纹分析可追溯一个国家内不同猪肉产地的可行性。
1. 简介
消费者对优质肉的需求与日俱增,而优质肉可能与其原产地或生产系统有一定关联的特定价值,如肉类食品上的产地标注。中国市场上目前已出现了许多具有产地标注的猪肉,而猪肉追溯体系尚未完善,这不仅对食品安全和质量有潜在的风险,还可能会限制猪肉出口贸易。肉源认证现已采用了多种分析方法,包括稳定同位素比分析,微量和稀土元素,光谱技术,核磁共振和有机成分指纹分析。但由于生物中元素的组成直接受到区域气候条件、生物环境相互作用和生物代谢的影响,所以多元素分析被认为是追踪食物来源的最可靠的技术方法之一。作者研究证实机器学习可以从数据本身中挖掘信息,并更好地反映数据的自然机制,多元数据分析和机器学习技术是进行食品鉴伪的有力工具。
2. 材料和方法
2.1 样品信息
作者研究的猪肉样品采集自中国七个地区:北京,广东,福建,辽宁,山西,河南和湖南。每个产地收集了10个样品,总共70个样品,所有猪的样品均在传统的饲喂系统下饲养,屠宰后在采样地直接收集后腿肌肉并保持在-20°C直至处理。
2.2 样品准备和分析
作者将样品切成小块后用搅拌机切成均匀混合物,使用微波消解仪进行酸解。0.50g 样品,6 mL 65%硝酸和2mL 30%过氧化氢溶液倒入微波消解罐,样品消解为澄清溶液。后转移至塑料样品管中,并用超纯水稀释至15mL。使用ICP-MS测定矿物元素(Na, K, Mg, Ca, B, Ti, Al, Mn, Fe, Co, Cu, Zn, As, Se, Rb, Li, Be, V, Cr, Ni, Mo, Ag, Cd, Sr, Sn, Sb, Ba, La, Ce, Pb, U, Tl和Bi)的浓度,最佳操作条件为:射频功率1550 W,氦气流量4.35 mL / min,动能歧视消除模式(KED),石英玻璃同心雾化器,采样时间0.1 s,重复两次。Rh, Re, In和Ge的内标物10 µg / L用于消除基质效应和仪器偏差。采用外标法进行定量分析,标准曲线的测定系数大于0.99。所有结果均表示为两次测试结果的平均值。在与猪肉样品相同的步骤下,对试剂空白进行11次重复测量以计算检出限。
2.3 数据分析
从元素分析获得的数据报告为平均值±标准误差。变异系数(CV)用于评估数据的分散性。检测限计算如下:
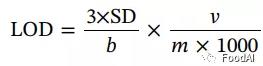

其中SD是11次重复的试剂空白的CPS(每秒计数)值的标准偏差,b是分析曲线的斜率,v是样品溶液的体积(v = 15 mL),m是测试部分的质量(m = 0.5g)。
使用Statistical Package for Social Sciences software (version 22.0, IBM, USA)进行统计分析。进行了方差分析(ANOVA),PCA,CA,Duncan多重比较分析和CDA,以确定来自不同产地的样本中元素数据的不同表现。这些方法需要对数据进行归一化预处理(9个元素×7个产地,每个产地10个样本)。为了从数据集中消除系统性偏差,将方差分析用作所有参数的显著性分析的非参数比较。当F值在方差分析中显著时,进行Duncan多重比较以确定各个产地之间的显著差异。CA用于衡量对象之间的相似性。距离和相似性的度量基于欧氏距离的平方。使用PCA进行降维,并通过向前逐步分析选择最重要的变量。 CDA计算了不同的独立判别函数。通过绘制第一函数和第二函数来检查判别空间中各组之间的间隔。为了验证模型的功能和稳定性,执行了“留一法”交叉验证判别分析。预测分类模型(RF, SVM, FNN)是基于R语言建立的。混淆矩阵和接收器工作特征(ROC)曲线(AUC)下的面积用作机器学习算法的性能指标。
3. 结果与讨论
3.1 猪肉中的矿物元素含量
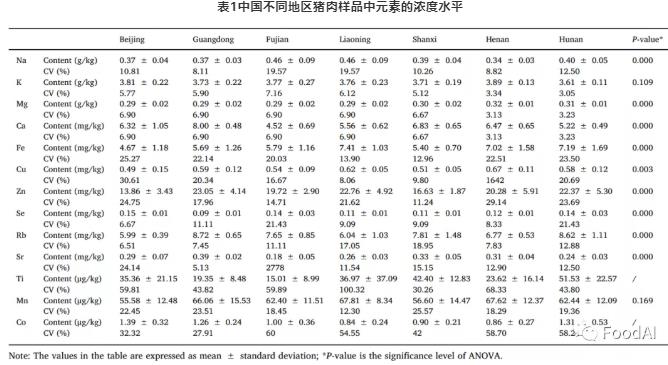
排除含量低于或接近检出限的元素后,共选择了13种元素进行统计分析(见表1)。显然,猪肉中的K含量最高,超过3000 mg / kg ,Na其次。Mg的含量为255至330mg / kg。Rb和Sr体现了地球化学行为,它们的含量随地表地质而变化,从而提供了更好的产地判别指标。通过来自同一产地的10个样品的相对SD来得出CV,从而评估样品分散度。Co和Ti的CV高意味着来自同一产地的猪肉样品中Co和Ti的含量不同,因此不适合用作可追溯性元素。选择K,Na,Mg,Fe,Ca,Cu,Zn,Mn,Se,Rb和Sr进行后续统计分析。
3.2 分析猪肉样品种矿物元素的地域性差异
方差分析的结果表明,样品中Na,Mg,Zn,Fe,Ca,Rb,Cu,Se和Sr的p值均小于0.05,这表明这9种元素在不同产地之间具有显著差异。进一步进行Duncan多重比较分析以寻找差异来源,发现每个产地都有一个特征性的元素含量分布(见图1)。结果表明与其他产地的样本相比,北京样本的特征是Fe, Cu, Zn和Rb的含量最低,而Se的含量最高;广东样品中Se含量最低,而Ca, Zn, Rb和Sr含量最高;福建省样品中的Ca和Sr含量明显低于其他地区,而Na含量较高;辽宁样品较独特,Mg含量最低,而Na和Fe含量最高;山西样品中的Fe和Cu含量低;湖南样品中的Mg,Fe和Zn含量高。
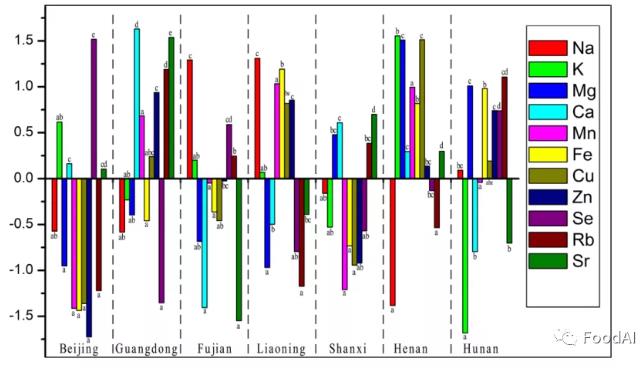
图1.每个区域的特征元素含量(Z分数标准化)的概况
注意:根据Duncan的多重比较,用相同的小写字母标记的列表示没有显着差异(p> 0.05)的子集
通过PCA降维功能,所有信息都可以用几个综合变量来描述,产地之间特征元素的差异可以更直观,更容易理解。使用ANOVA选择的具有明显产地差异的九种元素进行PCA。前四个主成分(PC)的方差贡献为29.9%、26.1%、14.4%和11.8%,累积方差贡献为82.2%,可以完全解释原始数据信息。PC1中的主要元素为Zn、Fe和Cu;PC2中为Sr、Ca和Na;PC3中为镁;PC4中为Rb。
为了更好地可视化来自不同地区的猪肉样品的相对分布,将前四个PC标准化得分用于CA。根据距离5.3的树状图切割,将来自不同区域的样本分为7个簇(见图2)。第一簇:河南7个,山西4个,湖北1个,北京1个;第二簇:北京7个;第三簇:北京10个,山西4个;第四簇:福建6个,湖南2个,北京2个;第五簇:湖南5个,福建3个,山西2个,辽宁一个;第六簇:河南2个,湖南2个,辽宁1个;第七簇:辽宁8个,河南1个,福建1个。很明显,猪肉样品中矿质元素的含量存在地区差异,这在追踪其产地方面具有潜在的应用前景。
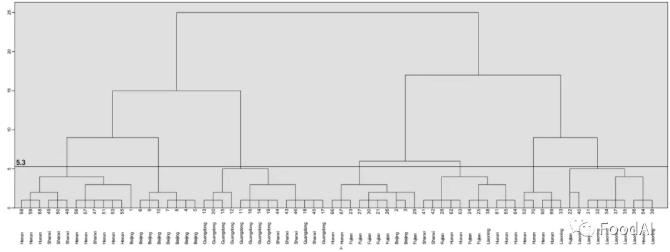
图2 聚类分析
用11种元素(K,Na,Mg,Fe,Ca,Cu,Zn,Mn,Se,Rb和Sr)进行CDA。进行留一法交叉验证以验证判别模型的效果和稳定性。在标准判别函数图中绘制了来自不同区域的样本(见图3)。得到的分类结果的总体准确度为85.7%,交叉验证的准确度为72.9%。可见,广东样品完全被分离出来,只有1个被鉴定为山西样品。正确识别了湖南的8个样本,2个分别被识别为福建和山西样本。北京,辽宁,河南和山西这四个地区相对较近,因此存在数据点交集,但他们都有7个正确分类的样本。福建的样本相对分散,只有6个样本被正确分类。这些结果与先前的CA结果一致。尽管证实了矿物质元素分析对猪肉产地可追溯性的可行性,但分类性能却不理想。这可能是由于某些产地非常接近。因此,有必要提高分类模型的性能。
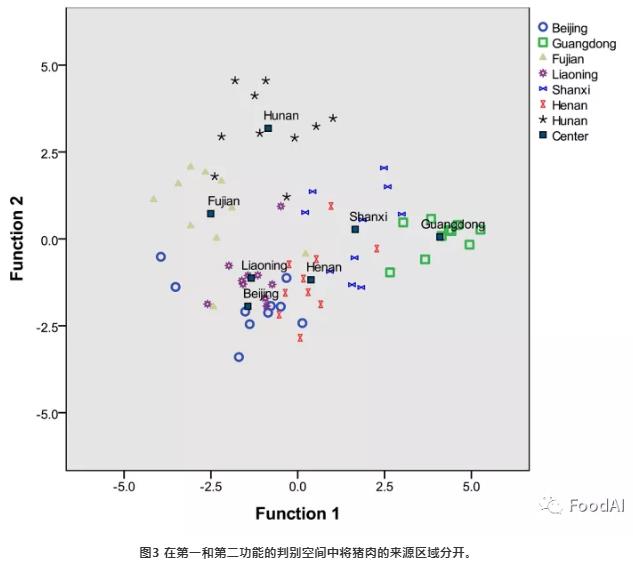
3.3 机器学习用于产地评估
机器学习在食物产地追溯领域中具有潜在的应用。此研究对三种不同的分类算法(FNN,SVM和RF)进行了评估,以根据矿质元素的含量对不同产地的猪肉进行分类。在没有真实测试集的情况下,交叉验证是避免出现偏差的有效方法。除了计算出的评价标准外,ROC和AUC作为机器学习算法的性能度量标准,优先于总体精度。图4显示了不同分类模型的ROC和AUC值。表2显示了样本不同分类模型的整体准确性,这三种算法的分类准确率存在显著差异,FNN为94.3%,SVM为98.57%,RF为78.57%。
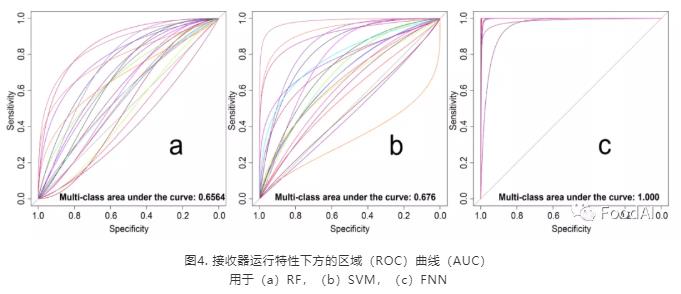
图4. 接收器运行特性下方的区域(ROC)曲线(AUC)
用于(a)RF,(b)SVM,(c)FNN
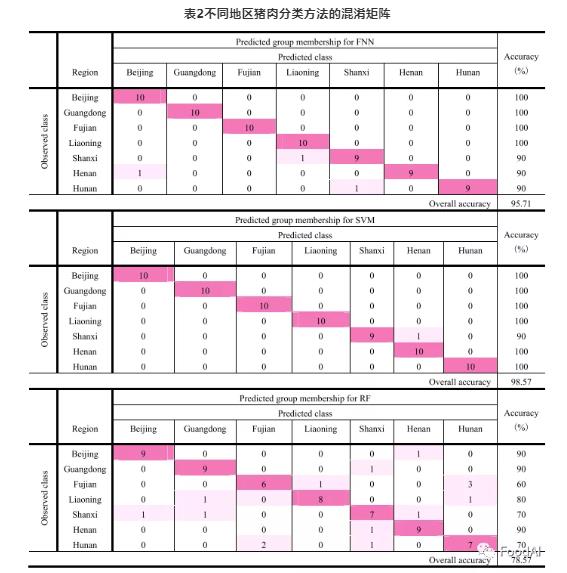
神经网络是一种用于信息处理的数学模型,其使用的结构类似于大脑的突触连接,具有非线性动态特性。神经网络在食品来源可追溯性方面的出色表现已得到多次验证。作者使用了Sigmoid激活函数的FNN,隐藏层节点数为8。FNN模型获得了最佳的精度,从ROC图表中可以看出,AUC接近于1。FNN比SVM更好,这是因为FNN是找到有效映射的一种主动方式,而SVM是一种被动的方式。
4. 结果与讨论
作者使用矿物元素分析的方法来区分中国不同地区的猪肉样品,并结合机器学习算法的多元统计分析,使用有限的样本数据获得了优秀性能的分类模型。未来需要更大的数据集来构建系统性的可追溯性数据模型,这方面将会有更广泛的应用。
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/pork-identify.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
食品安全中的人工智能技术: 基于行为数据的方法
今天介绍一篇由加拿大圭尔夫大学Arrell食品研究所Katya Kudashkina等人于2022年5月发表于 Trends in Food Science & Technology (IF:12.56)的一篇文章。文中所述,食品安全管理系统(FSMSs)提供了一个包括程序、培训和监控的综合策略,以防止食品安全危害,并将风险和召回降至最低。FSMSs的有效性和效率通过对滞后指标和领先指标的加强而提高。本篇文章展示了AI如何利用行为数据来开发食品安全的领先指标。
-
拉曼光谱结合机器学习对食用油的评价
今天介绍一篇来自罗马尼亚国家同位素和分子技术研究与发展研究所的Camelia Berghian-Grosan和Dana Alina Magdas于2020年5月21日在Talanta发表的文章。该文章是基于拉曼光谱结合机器学习算法建立食用油快速检测方法,不仅实现了掺假的定性检测,而且对掺假量也进行了初步估计。
-
利用温控近红外光谱研究限制环境下蛋白质的热稳定性及水的作用
文章中利用反胶束模拟限制环境,采集了不同温度下蛋白质溶液及反胶束溶液的近红外光谱。通过化学计量学方法对光谱进行解析,发现限制环境下蛋白质的热稳定性显著提高,并且发现了特殊桥连水结构的存在可能是其热稳定性提高的原因之一。
-
食品质量和真伪分析评估的数据挖掘/机器学习方法
近年来,为了更好地鉴定食品,通过现代分析仪器所获得的数据种类和数量急剧增加。一些模式识别工具已经被开发来处理大量复杂的有效试验数据。应用最广泛的方法有主成分分析(PCA)、部分最小二乘判别分析(PLS-DA)、类模型方法(SIMCA)、k-最近邻分类算法(kNN)、平行因子分析(PARAFAC)和多元曲线分辨率-交替最小二乘分析(MCR-ALS)。然而,也有一些替代的数据处理方法,如支持向量机(SVM)、分类回归树(CART)和随机森林(RF)等,与传统的数据处理方法相比,显示出巨大的潜力和优势。在这篇文章中,作者解释了这些方法的背景,并回顾和讨论了这三种方法在食品质量和真实性领域的应用研究的报道。此外,作者声明清楚了在这一特定研究领域中使用的专业术语。
-
色谱与化学计量学相结合在食品鉴定中的应用
食品掺假并非我们这个时代的现象,其历史可以追溯到食品制造的开始。关注食品欺诈问题是一个迅速发展的领域,这是由于公众对经济动机驱动的掺假的认识不断提高,而这可能会给人类带来严重的公共健康风险。化学计量学为光谱和色谱数据的校准分析提供了强大的工具,可用于有明确终点和无明确终点的方法中,以识别各种食品欺诈情况或验证其地理或生物学起源。
-
可容忍传感器故障等因素的机器学习模型用于食品质量预测
今天给大家介绍土耳其坎卡亚大学计算机工程系、软件工程系,土耳其伊斯坦布尔巴赫塞希尔大学计算机工程系,荷兰瓦赫宁根大学信息技术组合作,于2020年6月3日发表于Sensors期刊上的一篇研究型文章。文章中作者提出了一种单复数投票系统(SPVS)分类方法,可以通过忽略传感器故障或其他类型的故障来提高对食品质量的评估。为了说明该方法,作者使用了牛肉切割质量评估的案例研究。
-
机器学习技术在食物摄入量评估中的应用
天给大家介绍一篇由Larissa Oliveira Chaves等人,于2021年7月29日上发表在Food Science and Nutrition(IF=11.171)的一篇综述性文章。该综述使用5个计算机数据库进行文献搜索,旨在确定使用ML算法评估不同人群食物摄入量的研究。
-
食品设计:基于机器学习和机制的混合建模方法
当前,食品设计是通过不断试错并由品尝小组做出感官评价完成的。为了加快新食品的开发速度,提出了一种混合机器学习和机制建模的方法。用由所需食品过往数据训练的机器学习模型进行感官评价预测。该方法基于启发法、数据库等,首先确定候选食品组分和加工中的关键操作条件。与这些组分和加工条件(设计变量)有关的像颜色、松脆度和风味这样的食品特性都用到机制模型。通过改变设计变量来优化所需的食品特性,从而获得最高感官评分。使用遗传算法解决此灰箱优化问题,将设计约束(所需食品特性)处理为罚函数。提供了一个巧克力曲奇饼干的示例以说明混合建模结构的适用性和解决方案策略。
-
海南大学食品科学与工程学院王露课题组:鹧鸪茶中天然α-葡萄糖苷酶和α-淀粉酶抑制剂的筛选和鉴定及分子对接分析
该研究调查了鹧鸪茶提取物对α-葡萄糖苷酶和α-淀粉酶的抑制作用,测定鹧鸪茶提取物的总酚、黄酮含量及其对α-葡萄糖苷酶和α-淀粉酶的抑制效果,并通过HPLC-ESI- qTOF-MS/MS和亲和超滤筛选鉴定其起主要抑制作用的物质及含量;利用3T3-L1细胞测定鹧鸪茶提取物对其吸收葡萄糖的影响。最后,通过分子对接分析进一步阐明了这些抑制剂对α-糖苷酶和α-淀粉酶的可能作用机制。研究表明,鹧鸪茶是一种可应用于预防和改善餐后高血糖症状的天然代用茶资源。