今天给大家介绍土耳其坎卡亚大学计算机工程系、软件工程系,土耳其伊斯坦布尔巴赫塞希尔大学计算机工程系,荷兰瓦赫宁根大学信息技术组合作,于2020年6月3日发表于Sensors期刊上的一篇研究型文章。文章中作者提出了一种单复数投票系统(SPVS)分类方法,可以通过忽略传感器故障或其他类型的故障来提高对食品质量的评估。为了说明该方法,作者使用了牛肉切割质量评估的案例研究。


今天给大家介绍土耳其坎卡亚大学计算机工程系、软件工程系,土耳其伊斯坦布尔巴赫塞希尔大学计算机工程系,荷兰瓦赫宁根大学信息技术组合作,于2020年6月3日发表于Sensors期刊上的一篇研究型文章。文章中作者提出了一种单复数投票系统(SPVS)分类方法,可以通过忽略传感器故障或其他类型的故障来提高对食品质量的评估。为了说明该方法,作者使用了牛肉切割质量评估的案例研究。
背景
对于农业食品生产部门,食品质量的控制和评估是至关重要的问题。质量特征包括外部因素,例如外观,质地和风味,或内部因素,例如化学,物理或微生物特性。食品质量的一个关键特性是产品的气味,它是对食品香气和风味感知的主要贡献。相关术语嗅觉被定义为对气味的感知,通常可以由人类专家完成。然而,一种重要的趋势是机器嗅觉,或者使用所谓的电子鼻或电子鼻自动模拟嗅觉。机器嗅觉已在多个领域用于多种目的,例如食品质量控制,肉的新鲜度评估,新鲜蔬菜冷冻时间的检测,非法物质的检测,感染的诊断和疾病的诊断。机器嗅觉涉及使用自动化系统或电子鼻来分析空气中的化学物质。使用来自气体传感器的气体识别系统,正在开发不同的电子鼻。根据应用领域,已经使用了不同的气体传感器来测量,感测和识别不同的气体。
尽管智能气体传感器和气体识别系统非常有效,但仍有许多挑战需要解决。
(1)挑战之一与气体传感原理和任务的复杂性有关。一个特定的气体传感器可能会受到其他具有共同化学特性的气体的不利影响。
(2)诸如湿度和温度之类的环境因素也会影响传感器的精度。
这种称为传感器漂移的现象很复杂,会降低传感器的稳定性。因此,电子鼻和气体识别系统的性能受到不利影响。因此,数据质量会随着时间的推移而下降。研究人员解决了传感器漂移问题的两个主要原因。
- 一阶漂移与环境和传感器之间的化学过程有关。
- 二阶漂移与传感器噪声直接相关。解决此问题的一种方法是使用弹性传感器进行漂移。
当前传感器漂移和传感器故障补偿研究的最新技术是机器学习技术的应用,该技术已在许多其他应用领域中广泛使用。这些技术的主要优点是无需重新校准传感器。该研究中,作者提出并验证了基于单复数投票系统的机器学习技术,该技术应用多数投票规则来组合各个分类器的输出以容忍传感器故障。
在该项研究中,作者旨在分析SPVS分类方法在预测牛肉切块质量中的适用性。为了验证提出的方法,作者使用11种传感器(例如硫化氢,氨气,氢传感器)对12种不同类型的牛肉块(例如牛腩,肋眼,里脊)进行了许多实验。类别标签用四个类别表示(即1-优秀、2-良好、3-可接受、4-损坏)。已基于单个分类器的结果并使用多数投票机制构建了一个组合式SPVS分类器。
相关工作
针对传感器漂移问题,De Vito等人应用半监督学习(SSL)方法;刘等人使用域自适应方法;严等人提出一种称为最大独立域自适应的方法并应用了半监督MIDA技术;薛等人提出了粒子群优化的离散二进制版本。此外,基于组件校正的方法和基于顺序最小优化的技术已成功应用于调整模型以适应传感器漂移问题。
张等人开发了一个称为领域适应极限学习机的框架;赵等人将支持向量机(SVM)与改进的LSTM(长短时记忆神经网络)算法结合在一起;Vergara等人开发了一种基于支持向量机(SVM)的集成技术,并使用了在不同时间训练的分类算法的加权组合。
针对牛肉切块质量的预测:
Wijaya分析了传感器阵列优化问题的特征选择算法的稳定性,并使用了与不同牛肉块相关的12个数据集。Sarno和Wijaya讨论了电子鼻的应用对于牛肉质量评估的挑战。Wijaya等人提出了一种用于牛肉质量监测的噪声过滤框架,并表明该框架提高了多类别分类和回归算法的性能。Wijaya等人进行了几次实验,并从牛肉质量监测中收集了时间序列数据。Wijaya等人使用K-近邻算法对2/3/4类牛肉进行分类,并表明该方法可以对新鲜和变质的牛肉进行分类。
根据文中相关工作,SPVS分类器尚未应用于肉质预测问题,因此,作者的方法具有针对此问题的独特组成和特征。作者旨在使用SPVS方法针对牛肉切块质量问题开发新的预测模型。作者的目标不是获得最高的性能,而是旨在开发一种预测模型,该模型可用于传感器丢失的情况。
方法论
图1给出了机器嗅觉中食品质量监测的概念模型。在该食品质量监测系统中,从传感器阵列获取的数据通过访问点发送到服务器。原始信号被转换为数值并用作输入,以通过机器学习模型进行分类。
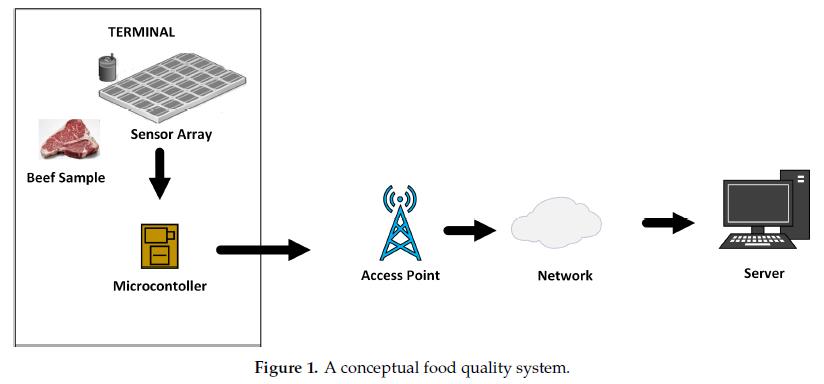
但是,传感器的精度可能会受到诸如温度之类的环境因素的不利影响。这个问题称为传感器漂移,是化学传感中最具挑战性的问题之一,可能会导致测量读数不准确,从而影响预测模型的性能。存在两种传感器问题。一阶传感器漂移与传感器和环境之间的化学过程有关,而二阶漂移与传感器噪声有关。在该项研究中,作者解决了传感器漂移问题,并提出了一种可以容忍传感器损失的新型模型。该模型的优越性是它对从传感器收集的特征损失的容忍度。
作者所提出的方法对传感器故障具有强健性。如果检测到故障情况并且忽略一个或多个传感器,则系统可以继续进行自动质量评估。图2给出了所提出预测方法的概观。集合SPVS模型是个体分类模型的组合。三种不同的机器学习方法被用作基本分类器,它们是LDA、DT和KNN方法。在预测过程中,基本模型的输出与多数投票相结合,投票数最大的标签被认为是最终的预测输出。
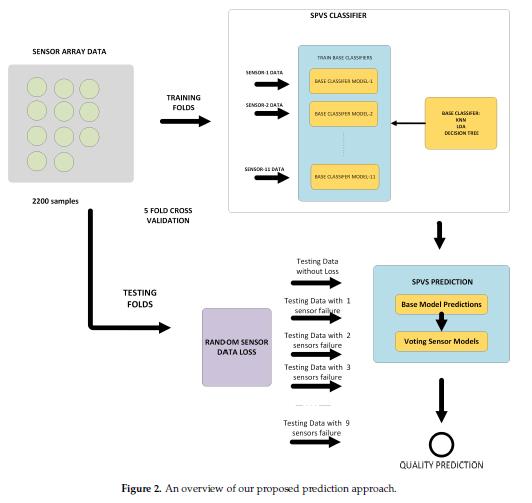
在接下来的章节中,我们将详细介绍基于SPVS的模型所采用的集成分类器技术和SVP算法(章节3.1),以及所采用的数据集(章节3.2)。
3.1 集成分类器
SPVS是用于构建集成分类器的方法之一。该方法将多个分类器或回归器组合在一起,构建一个元分类器。元分类器可以基于预测的类别标签或来自集合的概率来训练,或者可以应用多数投票来产生最终预测。SPVS分类器的算法如图3所示。在SPVS算法中(图3),X代表每个样本的特征向量,Y是样本的标号,n是训练集中的样本数。首先,用训练数据集D训练几个基本分类器。测试集中的每个样本(在算法中表示为T)由每个基本分类器单独分类,并保存结果。在最后一步中,元分类器使用结果来产生最终的分类输出。这里,可以训练以基本分类器的预测结果或概率分数作为输入的次级分类器。另一种集成技术是多数投票,这也适用于本研究。基本分类器输出中最频繁的分类结果作为最终输出值返回。

3.2数据集
作者的实验是在一个公开的时间序列数据集上进行的电子鼻,它是开发的牛肉质量监测实验。该数据集包含11种不同的金属氧化物半导体气体传感器的测量数据。以下列出了这些气体传感器及其选择性特性:
•MQ135:二氧化碳、酒精、氨、烟雾、苯
•MQ136:硫化氢
•MQ137:氨
•MQ138:甲苯、丙酮、酒精、氢
•MQ2:酒精、氢气、烟雾、液化石油气,甲烷, 异丁烷, 丙烷
•MQ3:甲烷
•MQ4:异丁烷,丙烷,液化石油气
•MQ5:丙烷、液化石油气
•MQ6:液化天然气、液化石油气,异丁烷,丙烷
•MQ8:氢
•MQ9:一氧化碳、甲烷和丙烷
从这些传感器收集的测量数据记录2220分钟。每分钟从每个传感器采样一个数据点。数据集包括从12种不同类型的牛肉块中获得的样本。数据集中的牛肉切块类型是小腿肉、上牛腰肉、里脊肉、皮瓣肉、西冷、牛胸肉、肉块、裙肉、内/外肉、肋眼、胫骨和脂肪。
实验结果
在实验中,使用了三个基本分类器(kNN、LDA和DT)的SPVS方法。选择这些方法是因为它们训练和测试速度快并且直接应用于数据集。在表格中,单分类器方法显示为“Single CL”,投票方法显示为“SPVS”。数据集中有12种牛肉切块,每种都有2200个样本。对于每种类型,得到的结果如下图所示。另外还进行了一项实验,以比较在传感器测量出现故障时两种方法的性能。在本次实验中,20%的测试样本没有故障,20%的测试样本有1个传感器故障,20%的测试样本有2个传感器故障,20%的测试样本有3个传感器故障,20%的测试样本有4个传感器故障。故障计数的顺序和传感器的选择是随机的。在表格和图表中,缺失值得到的结果用“missing”标签显示。
当传感器的测量失败时,还将进行额外的实验以比较方法的性能。在实验中,10%的测试样品有0失败,10%的测试样品有1传感器故障,10%的样品有2个,10%的有3个样品,样品有4的10%,10%的有5个样品,样品有6的10%,10%的样品有7,10%的样本8,10%的样本有9传感器故障。故障计数的顺序和传感器的选择是随机的。在表格和图表中,用“Missing”标签显示了本次实验的结果。
图4给出了牛胸肉(Brisket)数据集的分类结果。在无缺失值的数据集上,单树分类器的最佳CA值为99.2%,最佳敏感性为98.8%,最佳特异性为99.7%。基于树的SPVS方法在缺失值数据集上的分类准确率为94.1%。基于KNN的SPVS在敏感性和特异性上表现更好,分别为88.3%和96.7%。
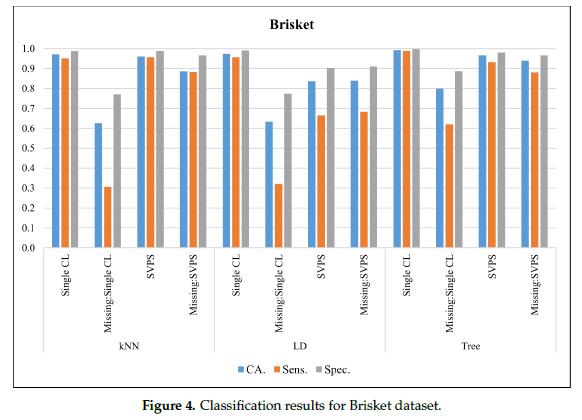
图5给出了使用脂肪(Fat)数据集的分类结果。在无缺失值的数据集上,单树分类器的最佳CA值为98.3%,最佳灵敏度为97.2%,最佳特异性为99.3%。基于树的SPVS方法在缺失值数据集上的分类准确率为82.8%。基于KNN的SPVS在敏感性和特异性上表现更好,分别为72.3%和90.1%。
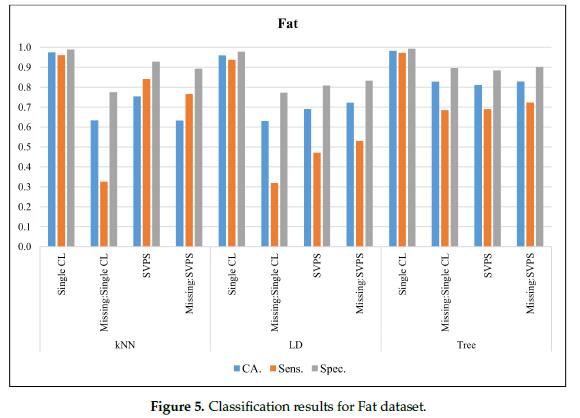
图6给出了胫骨(Shin)数据集的分类结果。单一kNN分类器在无缺失值的数据集上,最佳CA为98.1%,最佳灵敏度为97.9%,最佳特异性为99.3%。基于树的SPVS方法分类准确率最高,在有缺失值数据集上得分为90.4%。基于KNN的SPVS在敏感性和特异性上表现更好,分别为85.5%和94.1%。
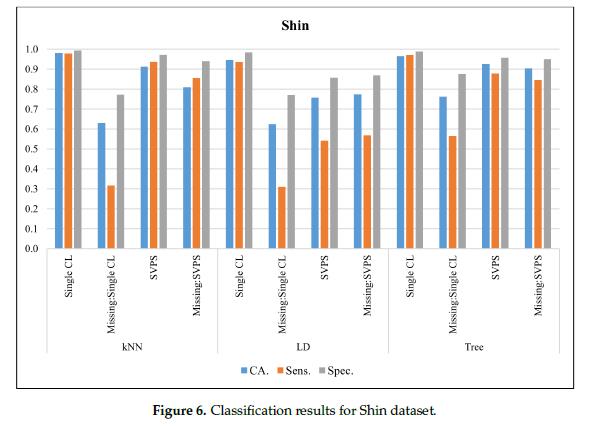
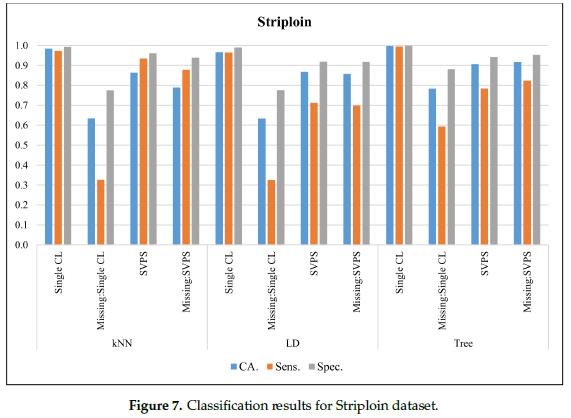
图7给出了西冷(Striploin)数据集的分类结果。在无缺失值的数据集上,单树分类器的最佳分类准确率为99.7%,最佳灵敏度为99.5%,最佳特异性为99.9%。基于树的SPVS方法提供了最好的分类准确率,在缺失值的数据集上得分为91.8%。基于KNN的SPVS在敏感性和特异性上表现更好,分别为87.8%和94.0%。
在图8中,给出了带有上牛腰肉(Tenderloin)数据集的分类结果。在无缺失值的数据集上,KNN分类器的最佳分类准确率为98.2%,最佳灵敏度为97.7%,最佳特异性为99.4%。基于KNN的SPVS方法对缺失值数据集的分类准确率为90.7%,灵敏度为88.4%,特异性为97.1%。
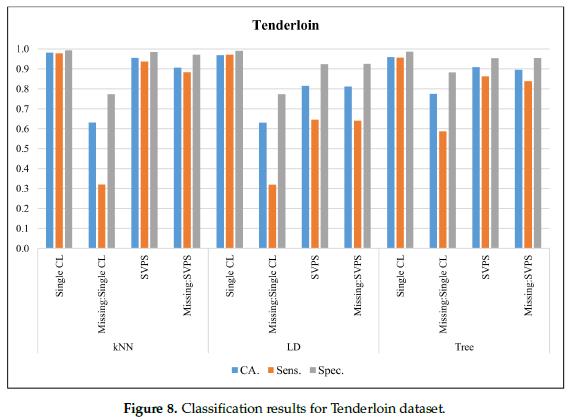
图9给出了小腿肉(Round)数据集的分类结果。在无缺失值的数据集上,树分类器的最佳分类准确率为99.3%,最佳灵敏度为98.7%,最佳特异性为99.8%。对于缺失值的数据集,基于树的SPVS方法提供了最佳的分类准确率为93.3%,最佳的特异性得分为96.3%。基于KNN的SVPS方法的灵敏度为90.3%。
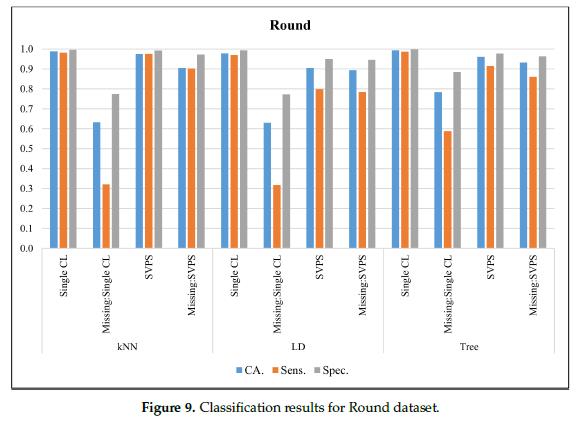
图10给出了肉块(Clod Chuck)数据集的分类结果。该线性判别分类器对无缺失值的数据,分类准确率为99.0%,灵敏度为98.8%,分类准确率为99.7%。基于树的SPVS方法对缺失值数据集的最佳分类准确率为88.5%,最佳灵敏度为78.0%,最佳特异性为94.0%。
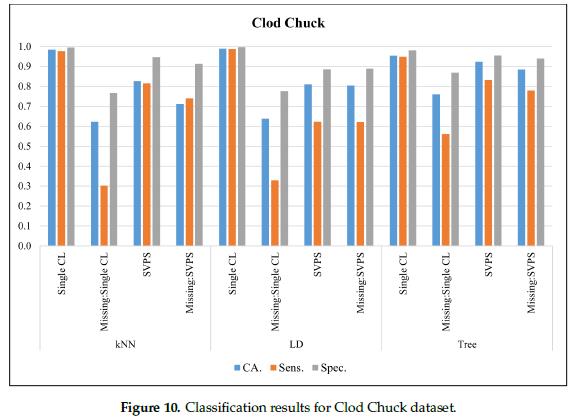
图11给出了皮瓣肉(Flap Meat)数据集的分类结果。在无缺失值的数据集上,线性判别分类器的最佳分类准确率为97.7%,最佳灵敏度为97.1%,最佳特异性得分为99.1%。基于KNN的SPVS方法提供了最好的灵敏度,在缺失值的数据集上得分为77.2%。基于树的SPVS在分类准确率和特异性上表现较好,分别为89.3%和94.1%。
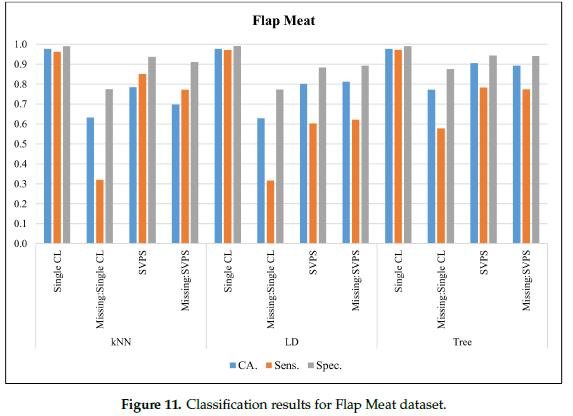
在图12中,给出了内外肉(Inside Outside)数据集外部数据集的分类结果。在无缺失值的数据集上,树分类器的最佳分类准确率为97.8%,最佳灵敏度为97.6%,最佳特异性为99.3%。基于KNN的SPVS方法提供了最好的灵敏度,在缺失值的数据集上得分为77.9%。单树分类器的分类准确率和特异性较好,分别为82.7%和90.2%。
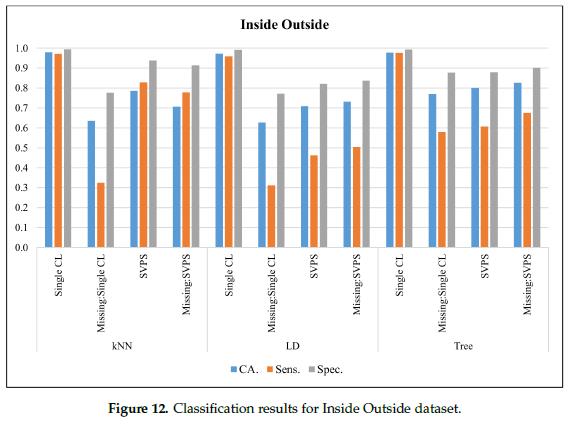
图13给出了基于肋眼(rib eye)数据集的分类结果。在无缺失值的数据集上,树分类器的最佳分类准确率为98.7%,最佳灵敏度为97.7%,最佳特异性为99.6%。基于树的SPVS方法对缺失值数据集的分类准确率为95.3%,特异性得分为97.8%。基于KNN的SPVS方法灵敏度最高,为92.4%。
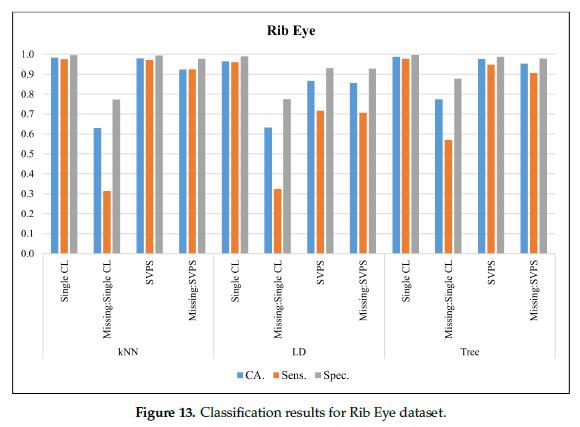
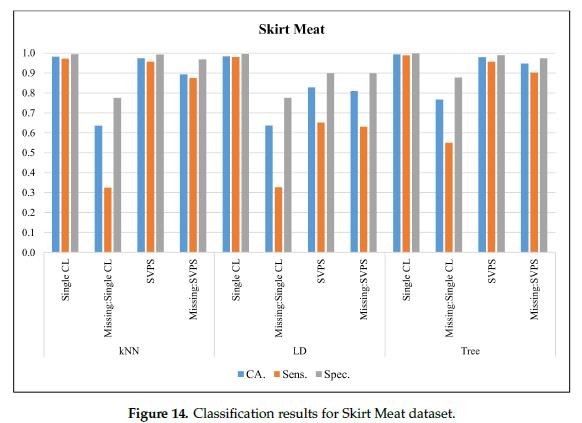
图14给出了使用裙肉(Skirt Meat)数据集的分类结果。在无缺失值的数据集上,树分类器的最佳分类准确率为99.3%,最佳灵敏度为98.8%,最佳特异性为99.8%。对于缺失值数据集,基于树的SPVS方法提供了94.8%的最佳分类准确率,90.3%的最佳灵敏度,97.5%的最佳特异性。
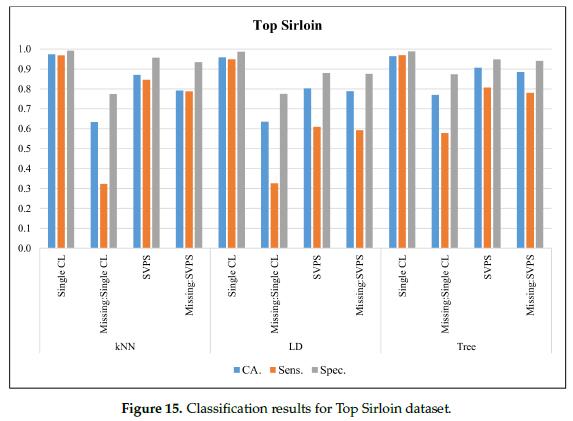
在图15中,给出了上腰肉(Sirloin)顶部数据集的分类结果。在无缺失值的数据集上,KNN分类器的最佳分类准确率为97.4%,最佳灵敏度为96.8%,最佳特异性为99.1%。基于KNN的SPVS方法提供了最好的灵敏度,在缺少值的数据集上得分为84.6%。基于树的SPVS分类器在分类准确率和特异性上有较好的表现,分别为88.5%和94.0%。
方法的平均分类分数如表1所示。在无缺失值的情况下,所有的单一分类器都比使用不同基本分类器的SPVS方法提供了更好的分类结果。然而,当对包含缺失值的数据集进行测试时,基本分类器的分类性能显著下降。在两个实验中,SPVS方法的性能更加稳定。基于树的SPVS方法在缺失值数据集上的表现优于所有分类方法。同样地,树分类器是最能抵抗缺失值的单一分类器。线性判别器和KNN分类器在缺失值情况下表现较差。
结论
结果表明,在缺失值的情况下,与其他分类器相比,SPVS分类器是最可容忍的分类器。虽然在所有特征都被用于训练的情况下,一些基本分类器可以达到更高的分类精度,但这种情况不可能一直存在,也不适合快速变化的物联网环境。传感器可能由于外部影响而停止服务,或者由于一些问题在特定时间从传感器接收到不正确的数据。作者提出的方法解决了这一问题,并证明了该方法的有效性和有效性。还有一些具有特征丢失容忍度的分类器,如随机森林;但是,这些分类器的学习和预测计算复杂度较高。
作者在该研究中的主要贡献如下:
•提出并验证了一种预测牛肉切肉质量的自动化方法,这种方法是唯一使用SPVS分类器来支持食品质量预测的方法。
•提出了一种用于食品质量预测的特征损失可容忍集成分类器。
•结合SPVS方法,利用KNN、DT、LDA等基本分类器对食品质量预测问题进行分析。
•实验表明,该方法在缺少值的情况下具有更好的性能。
虽然作者使用案例研究牛肉切肉质量,但该方法可以普遍应用于食品质量评估。在未来的工作中,作者将研究不同的集成学习方法和不同的设置来提高性能,并扩展实验结果与更多的数据集。
参考文献:
- Kaya A , Keeli A S , Catal C , et al. Sensor Failure Tolerable Machine Learning-Based Food Quality Prediction Model[J]. Sensors, 2020, 20(11):3173.
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/tolerable-ml-food-quality.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
ACS Omega:当机器学习和深度学习成为食品化学中的大数据
今天给大家介绍一篇由Tseng等人,于2023年4月发表在ACS Omega上的(JCR分区:4.132/Q2)一篇综述性文章。该综述重点介绍了一些著名的食品数据库的主要内容、接口…
-
社区食物零售业可达性、广域建成环境和家庭购买健康食品的相关性
今天介绍一篇将食品科学与建筑规划关联起来的角度新颖的论文,由彭科、Nikhil、Kaza等人发表在Public Health Nutrition上。建成环境与健康食物购买之间的联系是城乡规划领域一直被忽视的具有重大民生意义的课题。本文的目的是以分布在378个大都市的22448个美国家庭为例,利用多层次模型了解广域建成环境如何调节大超市和小便利店与人们购买新鲜蔬菜、蔬果数量多少之间的关系
-
李培武院士团队张兆威:通过Z型Cu2O/Cu3SnS4的智能手机驱动的光电化学POCT,用于检测邻苯二甲酸二丁酯
今天介绍一篇由中国农业科学科院油料作物研究所李培武院士团队于2023年8月发表在国际学术期刊Journal of Hazardous Materials(IF=13.6)上的题为“A smartphone-powered photoelectrochemical POCT via Z-scheme Cu2O / Cu3SnS4 for dibutyl phthalate in the environmental and food”的文章。中国农业科学院油料作物研究所张兆威研究员为论文通讯作者。
-
基于智能手机检测掺假牛肉糜
今天介绍一篇来自北京大学的宋惟然与王哲、海南大学的云永欢以及英国阿尔斯特大学的王晖等人于2021年2月发表在Microchemical Journal上的一篇论文。该研究基于智能手机摄像头拍摄猪肉糜与牛肉糜混合样品获得视频数据,经图像处理转换为类光谱数据,采用偏最小二乘回归(PLSR)建立模型并预测猪肉糜掺到牛肉糜的水平,测试集决定系数R2范围为0.73 ~ 0.98,均方根误差RMSEP范围为0.04 ~ 0.16。
-
系统综述人工神经网络在食品加工过程中的建模应用
今天给大家介绍一篇由G. V. S. Bhagya Raj等人合作的,于近期发表在Critical Reviews in Food Science and Nutrition的一篇综述,文章中作者系统综述了ANN在食品加工等领域的应用进展并进行了展望。
-
goFOOD:用于膳食评估的人工智能系统
作者利用深度神经网络对两个图像进行处理,实现了对食物的检测、分割和识别,以及利用3D重建算法估计食物量。作者提出的膳食评估系统goFOODTM支持319种细粒度的食品类别,并且已经在包含非标准和快餐食品的MADiMa和“Fast food”数据库中进行了验证。goFOODTM在MADiMa数据库中的表现优于经验丰富的营养师,而与“Fast food”数据库中的营养师相当。goFOODTM可为最终用户提供简单有效的膳食评估解决方案。
-
中国科学院蒋长龙团队:基于集成纸基传感器的便携式智能手机的无酶和快速视觉定量检测农药残留
今天介绍一篇由Qianru Zhang、蒋长龙等于2022年6月发表在Journal of Hazardous Materials上的一篇论文。该研究构建了一个简单、快速、可视化的无酶辅助的草甘膦(Gly)荧光定量检测平台。并且在设计的智能手机平台的辅助下制备了荧光试纸条,显示出作为便携式光学分析终端的潜力,用于定量跟踪真实样品中的Gly。该传感平台为Gly的定量检测提供了可靠的方法,可推广到分析科学领域的其他分析物或污染物筛选。
-
机器学习预测新兴污染物在植物中的吸收和转移:对食品安全的影响
今天介绍一篇由来自美国密苏里科技大学的Majid Bagheri等人发表在Science of the Total Environment上的一篇文章。文中使用神经网络和模糊逻辑,通过根部浓缩系数(RCF)和果实浓缩系数(FCF)测量植物根部和可食部位中污染物的积累。
-
基于质谱-机器学习技术的番茄分类:一个食品安全增强平台
今天介绍一篇由Arthur Noin de Oliveira等人于2022年8月发表在Food Chemistry(IF=9.231)上的文章。该研究旨在开发一个使用机器学习算法的平台,分析质谱数据,对番茄进行有机和非有机的分类。决策树算法被定制用于数据分析,该模型在确定每种水果属于哪个组时达到了92%的准确度、94%的灵敏度和90%的精确度。
-
一种基于机器视觉系统和深度学习的检测姜黄粉中掺假的新方法
今天介绍一篇最近由伊朗阿达比大学生物系统工程系Ahmad Jahanbakhshi等人发表在COMPUT BIOL MED (Q1, IF: 4.589)期刊上的文章。文章研究中,采用改进的卷积神经网络(CNN)对姜黄粉末图像进行分类,以检测参假。结果表明,计算机视觉,特别是与深度学习(DL)相结合,可以成为评价姜黄粉质量和检测参假的一种有价值的方法。