食品掺假并非我们这个时代的现象,其历史可以追溯到食品制造的开始。关注食品欺诈问题是一个迅速发展的领域,这是由于公众对经济动机驱动的掺假的认识不断提高,而这可能会给人类带来严重的公共健康风险。化学计量学为光谱和色谱数据的校准分析提供了强大的工具,可用于有明确终点和无明确终点的方法中,以识别各种食品欺诈情况或验证其地理或生物学起源。
1 . 食品欺诈和食品认证
欺诈和掺假检测,即所谓的食品认证,是一个通过标签描述验证食品合规性的过程。这可能包括地理位置,生产方法,加工技术和食品成分。除了经济损失外,食品欺诈还威胁着人类健康,如过敏反应。在处理食品质量和消费者保护以及遵守国家立法,国际标准和准则时,出处证明是一个重要的主题。
大多数掺假物是未知的,并且使用典型的靶向筛选方法很难识别。因此我们需防止有意或无意地向产品中添加未申报的。并且需要特定的方法来检测掺假,验证质量,保证地理原产地以及食品的生产类型。我们可以使用多种技术来测试食品的真伪,包括色谱法,紫外线,近红外,中红外和拉曼光谱。
2 . 不同食品的掺假
食品掺假并非我们这个时代的现象,其历史可以追溯到食品制造的开始。关注食品欺诈问题是一个迅速发展的领域,这是由于公众对经济动机驱动的掺假的认识不断提高,而这可能会给人类带来严重的公共健康风险。在这一点上,不遵守食品法、误导消费者和意图欺诈谋取经济利益是食品欺诈的主要特征。如今,由于食品市场日益全球化,许多食品也从其他国家供应。因此,检测和追踪有意和无意污染的来源是很困难的,尤其是在高度加工的食品中。可被掺假的食物和食品成分多种多样,包括食用油,蜂蜜,牛奶和乳制品,果汁,葡萄酒和酒精饮料,肉类产品,香料,咖啡,茶,谷物食品,有机食品和一些高度加工食品。
2.1 食用油脂
食用油脂包括植物油,动物油脂,色拉和食用油,人造黄油和黄油,被列为最容易掺假的食物。用便宜的油脂代替更昂贵的油脂并将冷压机油与精制油脂混合是食用油脂中掺假的两种主要方式。
橄榄油是出于经济动机进行掺假的重要目标。初榨橄榄油通常与较低等级的橄榄油(如精制或果渣橄榄油)或其他较便宜的植物油(如榛子,棉花,向日葵或大豆油)混合。橄榄油的地理起源的鉴定是确保特级初榨橄榄油的高质量必不可少的问题。
2.2 乳制品
牛奶是七种最易被污染的食品之一,可以通过几种方式进行伪造。与不同类型的牛奶或乳清混合,并添加三聚氰胺,盐或糖。商业超高温牛奶(UHT)可以通过添加掺杂剂(例如淀粉,氯,福尔马林,过氧化氢,尿液等)来呈现。牛奶中过量使用水会导致营养成分下降,乳制品中添加非牛奶脂肪是其他常用的伪造方法。乳制品的认证是进行监控的主要关注点,以确保根据实际加工的消费品正确标记乳制品。
乳制品的可追溯性也是一个重要问题,表明存在不良化合物,如抗菌剂,霉菌毒素,有机氯农药,抗生素残留物和重金属,以保护消费者免受有害污染。
2.3 蜜糖
通过添加其他甜味成分(例如高果糖玉米糖浆)来改变蜂蜜的成分,在生产或加工的任何部分使用葡萄糖浆或蔗糖浆都是获得经济利益的有吸引力的方法。通过向蜜蜂喂食诸如糖或糖浆等人工来源来掺假蜂蜜以及关于蜂蜜地理和植物来源的错误信息会给蜂蜜生产者和消费者带来严重问题。
2.4 饮料
饮料掺假方法是用水或从较便宜的水果中获得的果汁进行简单稀释,添加糖浆,酸和着色剂。酒或其他酒精饮料的掺假通常通过用水稀释,添加酒精,染料和香气并与质量较低的饮料混合来实现。除了这种掺假之外,还可能对该酒进行关于成分,真实性或地理起源的错误标签标识。咖啡欺诈通常是通过在咖啡混合物中使用劣质咖啡豆(地理来源和劣质咖啡豆),或在咖啡混合物中添加其他物质(咖啡果壳或羊皮纸,玉米和大麦,谷物或焦糖,小麦中小食,大豆和黑麦)来进行的。茶叶掺假通常涉及添加着色剂,用其他植物(例如腰果壳)替代,与其他地理来源或质量等级较低的茶混合。
2.5 肉和肉制品
在肉类和肉类产品的认证中,应考虑四个主要类别,包括肉类,生产工艺,加工处理,地理起源和非肉类成分添加(添加剂和水)。鱼和海鲜欺诈通常涉及故意增加产品重量和在生产中使用违禁添加剂。例如,在冷冻产品中添加过量的水(通过上光)或用便宜的肉类部分替代。
2.6 化学计量学
化学计量学为光谱和色谱数据的校准分析提供了强大的工具,可用于有明确终点和无明确终点的方法中,以识别各种食品欺诈情况或验证其地理或生物学起源。最常见的食品认证多元方法和原则可分为三类:探索性数据分析;数据描述和可视化,鉴别和分类;以及回归和预测。基于多变量数据分析的分类方法可以是有监督和无监督的。使用监督方法建立适当的数学模型可以预测验证集的未知对象。
食品认证分析中最常用的无监督方法是主成分分析(PCA)和层次聚类(HC)。许多算法可用于监督学习,例如作为线性方法里面的线性判别分析(LDA),偏最小二乘(PLS)回归;以非线性分类方法人工神经网络(ANN)。
3.1 多元分类进行定性分析
多元分类方法又称为模式识别方法,分为两大类:“有监督”学习算法和“无监督”学习算法。
3.1.1 模式识别
模式的识别/分类可能包括有监督的模式识别和/或无监督的模式识别。在监督分类方法中,每个类的成员都是预定义的,因为用于将样本分组为子集的信息是已知的;而在非监督模式识别方法中,问题是要找到样本之间的异同。
尽管快速而经济的计算可以更快地处理大型数据集,但通过使用复杂多样的数据分析和分类方法也可以促进此过程。创建模式识别系统涉及三个步骤,即获取数据集及其预处理,数据表示以及最终决策。在此过程中,要解决的问题是选择适当的数据生产来源,进行预处理,表示形式的设计以及决策模型的构建。
3.1.2 无监督模式识别
无监督方法,也称为探索性数据分析方法,不需要任何有关数据类结构的先验知识,而是可以自己产生分组,即聚类。探索性的数据分析技术通常通过使用映射和显示技术来理解复杂的多元数据集的结构,对于阐明多元关系的复杂性通常很有帮助。主成分分析是化学计量学中使用最广泛的无监督模式识别技术。PCA通常是数据分析中识别或验证测量数据模式的第一步。PCA通过减少数据的维数,使它们可视化,同时保留来自原始数据的尽可能多的信息。
能够深入了解数据集结构的其他识别模式的方法(例如聚类分析(CA))也可以用于数据矩阵中信息内容的初始评估。CA还尝试使用根据数据本身开发的标准在数据中查找样本分组或聚类。聚类分析基于以下原理:测量空间中成对的点(即样本)之间的距离与其相似程度成反比。该方法的基础基于这样的思想,即相似性与样本之间的距离成反比。到目前为止,最流行的是层次聚类。该技术的结果是树状图,即数据集中样本之间关系的直观表示。结果的解释是非常直观的,这也是这些方法得以普及的主要原因。
3.1.3 监督模式识别
在有监督方法(也称为判别分析)中,类及其属性是已知的,因此将定性信息添加到分类多元分析数据中。通常,通过使用有关样本的类成员的信息来建立分类模型,可以使用监督技术对集合进行校准或分类。然后,这些模型根据其测量模式将新的未知样本分类为一个或几个已知类别。
食品分类最流行的技术包括线性判别分析(LDA),k近邻(k-NN),类比的软独立建模(SIMCA),不等散类(UNEQ),人工神经网络(ANN),小波神经网络(WNN),支持向量机(SVM),偏最小二乘判别分析(PLS-DA)和潜在结构的正交投影-判别分析(OPLS-DA)。这些方法可以分为两类:第一种分类方法也称为区分方法,着重于区分不同类别,例如LDA,kNN,PLS-DA和ANN;以及另一类模拟类别方法,例如SIMCA和UNEQ。模式识别方法的性质通常也可以使用术语分类为参数/非参数,确定性/概率或线性/非线性方法。参数化技术假设获得的数据可以用概率密度函数来描述,而概率密度函数决定了数据的分布。
3.2 多元校准用于定量分析
多元校正已广泛用于不同的食品和化学工业中,无需进行复杂的分离和预处理即可进行分析。所构建的模型应该能够识别和捕获所观察到的数据的重要特征,以便提供一个有效的框架,其准确性和精确性足以为将来的样本正确预测输出变量。多元校准方法是线性和非线性数学技术的集合,当每个样品获得多个测量值时,这些技术可以应用于化学数据分析。主成分回归(PCR),偏最小二乘(PLS)回归,非信息变量消除PLS(UVE-PLS),部分稳健M回归(PRM),无信息变量消除遗传算法PLS(UVE-GA-PLS)和潜在结构的正交投影(O-PLS)是基于统计线性模型的此类校准方法,可以通过使用线性传递函数来连接输入和输出变量来开发统计线性模型。多元线性回归(MLR)是化学中最常用的校准和回归技术之一。但是,变量的共线性可能导致回归系数不稳定,并可能影响模型预测的准确性。
PLS技术的显着优势是,潜在变量是根据输入数据矩阵X和响应向量y之间的最大协方差创建的。PLS是一种广泛使用的多元统计技术,可以用来开发回归模型以推进化学性质的预测。然而,由于与y正交的X的可变性,模型回归系数的解释可能会很复杂。O-PLS消除了与y正交的X的可变性。为了获得强大有效的PLS方法,提出了部分鲁棒M回归(PRM)。支持向量机(SVM),人工神经网络(ANN)和随机森林(RF)是相对较新的模式识别方法,也已经针对多类问题开展了相关研究。
4.色谱指纹图谱
指纹分析以非选择性的方式产生包含有关食品成分信息的分析信号,并将其作为主要目的来鉴定或识别食品。其可以为食品综合控制提供强大而有效的工具。化学计量学作为一种多元数据分析工具,通常与指纹结合使用,以评估质量并认证食品和饮料产品。此外,全面的化学指纹分析还可以检测非标签污染的化合物和未经授权的添加剂,或使用禁止的工艺流程等。
有几种可用于指纹开发的分析技术,包括光谱法(例如NMR,MIR和NIR),色谱法(GC和HPLC)和质谱法。GC的主要缺点是经常需要衍生化。综合二维(2D)色谱是一项最近得到发展的创新技术。主要是因为存在额外的色谱维,这增加了指纹识别和随后进行身份验证的可能性。
5.食品样品的色谱分析
大多数方法都是使用高效液相色谱法或气相色谱法研究碳水化合物,类胡萝卜素,氨基酸,酚类或其他有机化合物的方法。三酰基甘油(TAGs),固醇和脂肪酸的测定提供了检测油掺假和表征掺混物成分的可能性。可以使用脂肪酸甲酯(FAME)的含量来实现不同植物油的表征和区分,该脂肪酸甲酯是通过气相色谱法测定的植物油的酯交换反应而获得的。
三酰基甘油(TG)存在于各种植物油中。食用油中TG的色谱分析方法包括气相色谱法,液相色谱法(LC)和和超临界流体色谱法(SFC)。与温度升高相关的多不饱和甘油三酸酯的热不稳定性是气相色谱中的重要问题。GC和SFC无法单独分离长链TG。非水相反相HPLC已广泛用于TG的分析。HPLC无需衍生就可以直接分离TG的能力。但是,由于不溶性,无法通过HPLC分析更高分子量的TG。
HPLC可用于分离所有类型的有机化学品,无论其极性或挥发性如何。极性化学品(例如氨基酸,羟基(聚)羧酸,脂肪酸,酚类化合物)的化学衍生糖和维生素也可以通过GC进行分析。
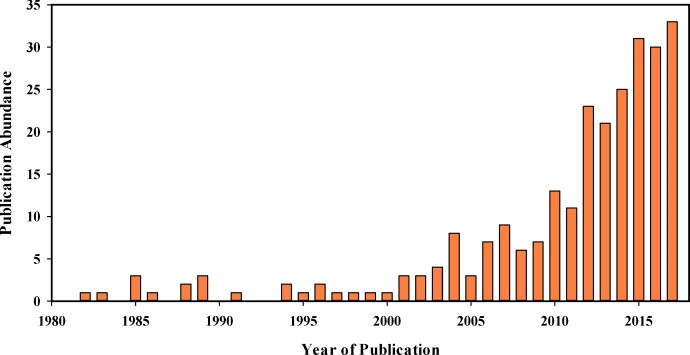
使用美国国立卫生研究院提供的免费文献搜索数据库PubMed,可以相当容易地分析食品应用中的色谱技术发展概况。图.1给出与主要食品应用类别,色谱技术和出版年份有关的PubMed数据库中的出版数量。搜索受到“色谱”,“食品”和“掺杂”术语的限制。从1980年到2017年,该领域的发表率已大大提高,这表明科学家越来越重视食品认证的重要性。

5.1.气相色谱法
开发和评估使用气相色谱法检测橄榄油样品的掺假方法的重点是脂肪酸成分的比较和化学计量分析等。有研究者提出了一种GC-MS方法,用四种类型的油来检测和鉴定初榨橄榄油的掺假,包括玉米油,花生油,菜籽油和日光油。
Mansor,Man和Rohman研究了将GC与表面声波检测器(GC-SAW系统)结合化学计量学来分析初榨椰子油中猪油的存在。将范围从1%到50%(v / v)的不同猪油和初榨椰子油混合物进行快速GC-SAW系统处理。Jabeur等2014年使用脂肪酸成分作为纯度的指标,使用亚麻酸含量作为检测大豆油含量为5%的特级初榨橄榄油欺诈的参数。他们的结果表明,在澄清橄榄油与其他较便宜的橄榄油(例如大豆油,玉米油或葵花籽油)的掺假中,甾醇的分布几乎至关重要。他们使用LDA作为快速检测初榨橄榄油掺假的工具。
Esteki等解决了通过GC脂肪酸指纹分析与化学计量学方法(包括PCA,PCA-LDA,PLS和最小二乘支持向量)结合对杏仁粉样品进行掺假检测的问题机器(LS-SVM)。混合不同比例的杏仁和杏仁样品,以得到10至90%w/w的所需比例。PCA用作探索性数据分析,而PCA-LDA则用于杏仁,杏仁及其混合物的分类。用PLS和LS-SVM作为回归方法确定杏仁的掺假率。均方根误差(RMSE)和确定系数(R 2)获得的用于LS-SVM的验证数据集分别为2.3和0.995,这表明测试杏仁掺假方法的可行性。
通过快速气相色谱电子获得的橄榄油样品的脂肪酸组成经过化学计量学方法测定其真实性和地理起源。对意大利和阿根廷橄榄油进行类似分析后,便可以根据三酰基甘油成分对其进行分类。Gutiérrez等2009年使用GC测定牛奶和非牛奶脂肪中的三酰基甘油谱。为了检测和定量乳脂中的非乳脂,对三酰基甘油谱进行了LDA分析。分析了来自墨西哥中部地区的原料乳脂肪和来自三个工厂的超巴氏灭菌乳脂肪,以及猪肉脂肪猪油,牛脂,鱼油,花生玉米油,橄榄油和豆油。将原始乳脂样品与不同比例(0-20%)的非乳脂掺假。从LDA获得的第一个功能可以对94.4%的掺假样品进行正确分类。使用LDA模型评估了超巴氏灭菌的乳脂的三酰基甘油谱,表明一家工厂向其产品中添加了非乳脂。通过对10个GC峰进行LDA分析,以95%的分类精度对来自四个意大利单品种的同一意大利地区(西西里西南)的西西里橄榄油单样品进行了区分。这项研究表明,与NMR多元数据分析相比,GC指纹图谱与多元数据分析相结合可以更好地实现品种之间的清晰分离。化学计量学方法也已成功应用于GC数据,以验证其他几种食品和饮料,例如咖啡和果汁。
Reid等将GC和化学计量学相结合,根据苹果品种和应用的热处理对苹果汁样品进行区分。对色谱数据进行PLS回归和PCA-LDA。PLS根据苹果品种和热处理对苹果汁样品进行了正确分类,准确度为92.5%,而使用PCA-LDA分别根据苹果品种和热处理对苹果汁样品进行了正确分类,分别为87.5%和80%。
Winterová等。确定了不同浓度的挥发性化合物,脂肪酸和稳定的同位素比,以通过GC与LDA结合来评估果酒的真实性。结果表明,特别是同位素比率可用于区分水果烈酒和其他烈酒,即由玉米,蔗糖,甜菜糖,谷物,马铃薯或合成酒精制成的烈酒。也可以区分从一种水果中提取的各种烈酒,例如甜樱桃白兰地,酸樱桃白兰地,苹果白兰地,杏白兰地,梨白兰地或李子白兰地。
气相色谱法测定挥发性成分也可用于检查含有挥发性有机化合物的食品的真伪。González-Arjona等对52种商业化威士忌进行了挥发性成分分析用二氯甲烷液-液萃取后,通过GC-MS进行分析。使用包括多层感知器(MLP)和概率神经网络(PNN)在内的多变量数据分析,包括LDA,k最近邻(KNN),SIMCA,过程判别分析(PDA)和人工神经网络技术。通过考虑与预测集相关的每个类别的假阳性(FP)和假阴性(FN)的数量,对构建的模型进行了验证。人工神经网络由于其固有的非线性特性而显示出最佳结果。MLP和PNN对类别均达到100%的选择性和100%的特异性。KNN作为非参数方法也提供了合理的结果。PDA通过选择9种主要成分进行类建模而产生了100%的灵敏度和100%的特异性。
Lin等在2013年开发了一种基于挥发性化合物来区分乌龙茶品种和掺假样品的分析方法。通过顶空固相微萃取(HS-SPME)结合GC-MS分析了铁观音,茅泻,金观音,本山和黄金桂这五个品种的乌龙茶样品。主要挥发性化合物的色谱指纹图谱随着品种的变化而显着变化,这表明芳香物质特征可能对起源非常近的茶树种起重要的区分作用。PCA应用于色谱指纹图谱,结果表明,品种特征比其他特征(如产地和质量)要强。通过逐步线性判别分析(S-LDA),选择了18种具有最佳辨别潜力的挥发性化合物,
Lorenzo等在2002年应用顶空进样器与质谱仪(HS-MS)的直接耦合来快速检测橄榄油掺假。将橄榄油样品与不同浓度的防晒油和橄榄果渣油混合。获得了原始样品和混合样品中的挥发性化合物图谱。LDA足以区分掺假油和非掺假油,并区分掺假类型。训练集和预测集的分类准确性为100%。
Rodríguez-Delgado等使用HPLC分析法对15种多酚浓度与PCA和LDA的组合进行了HPLC分析,正确地分类了加那利群岛(西班牙)不同产区的葡萄酒。2002年,Roberto Romero等使用样品中的8种生物胺化合物获得的RP-HPLC数据,通过PCA,聚类分析和LDA对西班牙的佐餐酒进行了正确区分。2009年,Bellomarino等结合了PCA和LDA和UV检测的HPLC也用于某些澳大利亚葡萄酒的地理分类,准确度为75%–100%。
2001年González等基于RP-HPLC分析,将咖啡样品中的绿色和烘焙咖啡豆的甘油三酸酯和生育酚成分与PCA和LDA结合使用,以区分不同的品种。在2014年,另一份报告中,Domingues等使用PCA使用HPLC-UV-Vis来检测烘焙和磨碎咖啡中的掺假。2010年,Fasciotti等使用常压化学电离界面(APCI-MS)和HPLC进行质谱分析,使用PCA对三酰基甘油进行评估,以表征大豆油对橄榄油的掺假。HPLC-MS,PCA和LDA模型获得的数据非常适合对样品进行分类。Tavares等人2016年研究了生育酚作为玉米掺假标记的有效性,基于它们检测到咖啡前壳的主要残留物-咖啡果壳的掺假的能力。在本研究中,使用烤果皮,清洁的烤果皮和烤玉米作为掺假品。通过正相HPLC(具有荧光检测)分析提取的脂质,并通过PCA,LDA和SIMCA分析发现的生育酚含量。基于生育酚谱,可检测出玉米掺假物的含量高于10%。对于重掺假,也可以区分果壳和干净的果壳。
Jabeur等2014年使用亚麻酸含量作为检测大豆油含量为5%的特级初榨橄榄油(EVOO)欺诈的参数。为此,使用气相色谱和液相色谱对脂肪酸,固醇和三酰基甘油谱进行了分析。他们研究的目的是检测大豆,玉米和葵花籽油对EVOO的掺假情况。选择特征后,使用LDA足以区分EVOO和所有掺假的特级初榨橄榄油。分类成功率为100%,预测成功率接近100%。Sabir等在2017年将HPLC指纹图谱分析与化学计量学相结合,以区分在印度尼西亚种植的红色和白色米糠。阿魏酸酯,阿魏酸酯,阿魏酸酯和阿魏酸β-谷甾醇是表征米糠的主要成分。PCA和LDA分析已成功用于区分具有良好预测能力的两个类别。
6.结论
色谱指纹图谱在食品表征和验证中的使用非常合适包括掺假,可追溯性和分类目的的检测。如预期的那样,人们主要使用色谱分离技术(HPLC或GC)以及不同的检测方法进行多种有机化合物的测定。多元定性方法是处理无法通过有限数量的变量解决的食品认证问题的有效工具,因为所需和获得的响应本质上是复杂的,而且没有任何单变量信号可作为明确的标记。色谱数据的化学计量分析为检测可疑欺诈样品提供了可靠性,并为不同食品的分类提供了适当的方法。这些方法在日常分析以及各种食品(例如食用油,饮料,蜂蜜和乳制品)中新型掺假剂的研究中具有特殊的潜力。
参考资料:
- Esteki M, Simal-Gandara J, Shahsavari Z, et al. A review on the application of chromatographic methods, coupled to chemometrics, for food authentication[J]. Food control, 2018, 93: 165-182.
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/food-fraud.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
在食物蛋白质衍生肽数据库中对胆汁酸结合肽进行机器学习筛选
今天介绍一篇近期由日本名古屋大学生物分子工程系的Kento Imai等人发表于Nature scientific reports的文章。文中使用BIOPEP-UWM和机器学习开发了一种新的生物活性肽筛选方法,有助于识别胆汁酸结合肽以及其他生物活性肽。
-
Nutrients:eBASIS数据库中的可提取和不可提取抗氧化剂成分:人类健康和疾病研究中膳食评估的关键工具
今天介绍一篇由Jenny Plumb等人于2020年11月在线发表在Nutrients(IF=6.71)上的文章。这篇文章讨论了eBASIS数据库的更新,该数据库包括可提取和不可提取的抗氧化剂,这对于评估食物基质的抗氧化性质及其与人类健康的相关性非常重要。文章还介绍了非可提取多酚的重要性、测量食物和膳食补充剂中抗氧化活性/容量的各种方法、维护和更新食物成分数据库的重要性以及相关挑战。总体而言,文章强调了需要标准化的方法和数据库来准确评估我们饮食中的生物活性化合物及其潜在的健康益处
-
基于比色条形码组合和深度卷积神经网络的便携式食品新鲜度预测平台
今天介绍一篇来自江南大学,于2020年底发表在Advanced Materials上的一篇论文。该研究将可交叉反应的比色条形码组合和深度卷积神经网络(DCNN)结合在一起,形成了一个用于监控肉类新鲜度的系统,总体准确性为98.5%。
-
FOOD CHEM| 安徽农业大学宛晓春团队:基于GC-MS和GC-IMS表征三种茶制成的乌龙茶的香气特征
该研究基于采用GC-IMS、GC-IMS、感官评价和OAV测定等方法,对水仙、黄玫瑰和紫玫瑰的新鲜茶叶和乌龙茶的香气特征进行了综合分析。其中,苯乙醛和3,5-二乙基-2-甲基吡嗪是黄牡丹茶的香气活性成分。与水仙相比,黄玫瑰和紫牡丹的挥发物和花香味明显更多。此外,使用GC-IMS鉴定出27种挥发物,表明该联合方法有助于更好地了解品种对茶树香气的影响。
-
Food Chemistry|深度学习在基于图像的中国市场食品营养估计中的应用
该研究在视觉识别任务中利用了深度学习技术,并提出了一套大数据驱动的深度学习模型,从食物图像回归到营养估计,最大限度地发挥了深度学习模型的潜力,同时为未来将人工智能引入食品领域提供了基础。
-
重磅干货:食品科学数据库资源汇总(国外篇第二部分)
书接上期,我们分享了一系列国内的食品数据库资源和一部分国外食品专业数据库。这些数据库主要对食品添加剂的安全、食品成分、食品营养和食品酶等方面进行了数据分析与平台搭建。下面继续介绍几篇相关的食品数据库文章。
-
FOOD CHEM|海南大学云永欢课题组:高光谱成像技术结合数据融合的罗非鱼鱼片新鲜度快速检测研究
该文研究了两种波段范围的高光谱成像系统(可见-近红外光谱(Vis-NIR)和近红外光谱(NIR))在冷藏期间测定罗非鱼鱼片中挥发性盐基氮(TVB-N)含量的潜力。利用Vis-NIR和NIR数据,建立了高光谱图像中罗非鱼鱼片平均光谱与其TVB-N含量之间的校正模型,并采用数据融合和多种变量选择方法对模型进行优化。最后,采用优化的模型来实现罗非鱼鱼片中TVB-N含量的可视化分布。结果表明,高光谱成像技术结合数据融合和变量选择等化学计量学方法在罗非鱼鱼片新鲜度无损评价分析中具有可行性。
-
人工智能从科学文献和媒体报道中检测未知兴奋剂推文
今天介绍一篇由Anand K. Gavai等人于2021年在Food Control上发表的文章。文中提出了一种方法用机器学习来检测在保健品中未知的兴奋剂。从两个不同的数据来源中确定了20种新的兴奋剂,分别是用单词嵌入模型从科学文献中自动发现未知兴奋剂,以及基于文本挖掘在万维网上搜索新闻报道来收集新的兴奋剂。
-
使用人工神经网络和煮熟米饭的质地特性准确预测米饭的食用和烹饪质量
今天介绍一篇由四川农业大学农学院任万军教授团队于2022年12月发表在Food Chemistry(IF=9.23)上的文章。这篇文章主要讨论了使用人工神经网络(ANN)和米饭的质地特性来预测米饭的食用和烹饪质量(ECQ)的模型开发。
-
机器学习方法表征致肥胖城市的暴露组
今天分享一篇近期由荷兰阿姆斯特丹公共卫生研究所流行病学和数据科学系的Haykanush Ohanyan等人发表在Environment International上的文章。