近年来,为了更好地鉴定食品,通过现代分析仪器所获得的数据种类和数量急剧增加。一些模式识别工具已经被开发来处理大量复杂的有效试验数据。应用最广泛的方法有主成分分析(PCA)、部分最小二乘判别分析(PLS-DA)、类模型方法(SIMCA)、k-最近邻分类算法(kNN)、平行因子分析(PARAFAC)和多元曲线分辨率-交替最小二乘分析(MCR-ALS)。然而,也有一些替代的数据处理方法,如支持向量机(SVM)、分类回归树(CART)和随机森林(RF)等,与传统的数据处理方法相比,显示出巨大的潜力和优势。在这篇文章中,作者解释了这些方法的背景,并回顾和讨论了这三种方法在食品质量和真实性领域的应用研究的报道。此外,作者声明清楚了在这一特定研究领域中使用的专业术语。
近年来,为了更好地鉴定食品,通过现代分析仪器所获得的数据种类和数量急剧增加。一些模式识别工具已经被开发来处理大量复杂的有效试验数据。应用最广泛的方法有主成分分析(PCA)、部分最小二乘判别分析(PLS-DA)、类模型方法(SIMCA)、k-最近邻分类算法(kNN)、平行因子分析(PARAFAC)和多元曲线分辨率-交替最小二乘分析(MCR-ALS)。然而,也有一些替代的数据处理方法,如支持向量机(SVM)、分类回归树(CART)和随机森林(RF)等,与传统的数据处理方法相比,显示出巨大的潜力和优势。在这篇文章中,作者解释了这些方法的背景,并回顾和讨论了这三种方法在食品质量和真实性领域的应用研究的报道。此外,作者声明清楚了在这一特定研究领域中使用的专业术语。
1.介绍
保证食品的真伪是许多消费者和高质量产品制造商以及官方机构和当局的主要关切,为了保护消费者,我们需要发现潜在的食品欺诈行为。食品的真实性必然与合规有关;因此,真正的食品是严格遵守基因标识、自然成分、地理和类型来源、配料、生产技术、隐含的质量特征和标签上明确声明的产品。总的来说,食品欺诈是指对食品的来源、质量或数量进行欺骗,以牟取非法利润。全球化和自由贸易协定促进了世界各地食品的交流和获得。然而,这也导致了食品欺诈问题的增加。食品欺诈主要有三种:不合格、掺假和污染。不合格指食品不符合标签所列明的特性;它是通过伪造或仿造来识别的。掺假包括对原食品的内在成分的故意和未说明的改变。至少,污染涉及到非故意或偶然的外在物质的存在。
食品欺诈的严重程度取决于欺诈的种类。例如,食品掺假可能是用更便宜的原料代替原来的原料,就像橄榄油中可以掺假更便宜的植物油一样。在这种情况下,消费者为质量低劣的食品支付了更多的钱,但这并不涉及任何健康风险。然而,还有其他类型的食品欺诈可能会影响到人类健康。例如,使用受污染的商品、原料或过敏原。从这个意义上说,食物链和可能的食品欺诈由官方机构严格控制是很重要的。另一方面,控制真正食品的替代品,确保产品在地理来源方面的真实性也很重要。分析涉及多项活动,如对特定物理化学特性的分析测定,杂质和/或污染物和残留物的鉴定/定量,以及对质量差异技术要求的验证。
在此背景下,多元数据分析和模式识别技术是进行质量控制和食品认证的强大工具。
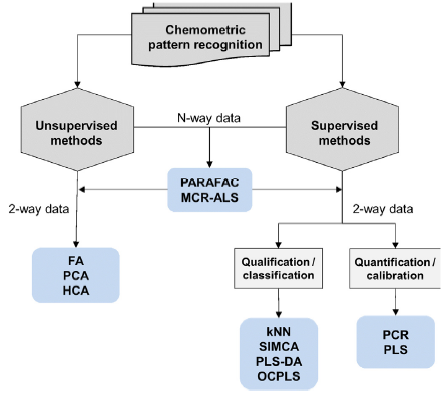

多元模式识别方法的主要目的是执行最合适的数据处理,以便对一组表现出特定特征或行为的对象或样本进行建模和表征。为此,根据光谱、色谱、元素分析、图像等的相似性,提取重要的和不明显的信息,以建立该组对象/样品之间的关系,或者该组对象/样品与一个或多个特征之间的关系。这些工具还必须能够将新样本分类到某个组中,并以快速客观的方式可靠地预测特定资产的价值。
模式识别方法主要分为两大类:无监督方法,其主要工具为主成分分析(PCA)和层次聚类分析(HCA);以及监督分析方法,如k近邻(kNN) 、部分最小二乘判别分析(PLS-DA) 和基于类模型方法(SIMCA) 等。同样,在机器学习领域中,我们也知道无监督和有监督的学习技术。图1给出了传统模式识别方法的简单流程图。
探索性分析通常用于探查数据结构,并确定数据集中是否存在趋势。主成分分析(PCA)是一个有价值的统计工具, 其目标是最大化数据中的方差信息,并以尽可能少的成分直观地显示出来。它主要用于提供关于对象/样本的自然分组的信息,并减少表示系统所需的变量数量,提供一套新的潜在变量称为“主成分”。然而,有时主成分分析(PCA)被错误地应用,并在一些研究中被用作开发和验证分类模型的分类方法。不幸的是,这种错误仍在发生。聚类分析是基于一组对象/样本之间的内在相似性。分层聚类分析的结果以树状图的形式呈现,其中对象/样本分布在分枝树中,数据按照类别和子类别(分支)组织,节点根据它们的相似性表示聚类。
受监督的分析方法分为两组:(i)分类或鉴定方法和(ii)校准或定量方法。多变量分类/鉴定方法被定义为化学计量技术,其目的是根据特定的数据集,找出能够识别每个对象/样品属于哪一类的数学模型;它们涉及使用不同的化学计量算法,这些算法具有与歧视和阶级建模方法相关的两种主要统计背景。
分类方法有很多,但最常用的是kNN、PLS-DA和SIMCA。多变量校准/定量方法实际上是多变量回归方法,目的在于确定从一组样品中获得的分析信号与这些样品的特征特征(如其组成)之间的函数关系。最广泛使用的算法是偏最小二乘回归(PLS) (Mehmood & Ahmed, 2016)。应该指出的是,虽然分类本质上是一个定性的过程,但对象或样本分配到特定类可以有定性的基础(如kNN或SIMCA)或定量的基础(如PLS-DA)。事实上,PLS-DA方法涉及执行多元回归,并首先为每个对象/样本放置一个数值,然后将它们分类到一个特定的类中(Brereton & Lloyd, 2014)。此外,在处理二阶数据时还应用了其他类型的多元方法。这意味着每个样本得到的是一个数据矩阵,而不是一个数据向量(一阶数据)。在这种情况下,最常用的方法是并行因子分析(PARAFAC)和多元曲线分辨率-交替最小二乘(MCR-ALS)。
模式识别监督模型的开发包括两个阶段。第一个阶段是使用一组对象或样本来构建模型,这些对象或样本的类或特定特性是已知的(例如。,训练集或校准集)。在这个阶段,一个内部验证或交叉验证可以应用来评估模型的拟合优度的训练集的样本/对象。然而,Crossvalidation通过自己的设计目的,无法实现所有必要的目标正确的验证。第二阶段是对前一阶段所建立的模型的性能进行评估和外部验证;这是通过使用其他对象或示例,满足相同的要求,但不属于原始训练集的一部分; 在这些方法中,假设有足够多的参考对象/样品作为分析标准,因为感兴趣的结果(即,(定性分类或一个或多个定量特征的值)是以前已知的或已被精确测量过的。对于模型开发所需的样本/对象的最低数目,并没有明确的规则,因为这取决于具体的问题;然而,将40-50%的引用样本/对象用于验证集是可取的。
分类模型的质量评价是通过几个性能特征来评价的。使用列联表来估计,列联表记录了每个类的正确和错误分配的数量,验证集的样本被安排在其中。同样,还提出了评估多元校准模型的具体价值数字。但是,对多变量模型的评估是不够的,还需要对整个分析方法进行适当的验证。
关于分类方法的有效使用,一些作者认为最好使用类建模方法,如SIMCA来进行充分的食品认证。这是因为在训练阶段,类建模方法的作用是定义一个界定良好的接受区域,其中包含目标类的所有对象/样本;因此,只有位于接受区域的新对象/样本被分配为属于目标类。
近年来,新模式识别的应用图1。常规化学计量模式识别算法的概述由于其优点和解决与食品真实性相关的复杂问题的潜力,在食品领域中正在发展。最广泛使用的是支持向量机(SVM)、分类和回归树(CART)和随机森林(RF),它们可用于分类和校准模型。令人惊讶的是,尽管它们被广泛用于代谢组学等其他领域,但它们在食品质量和真实性领域的应用仍然很少。一些作者甚至报道了它们与传统技术相比的优势。例如,有人指出“……与PLS-DA相比,SVM不受不同样本类别分布的影响,而是侧重于特定测试样本属于支持向量的哪一方。”同样,RF算法的优势已经在生态学领域得到了报道。
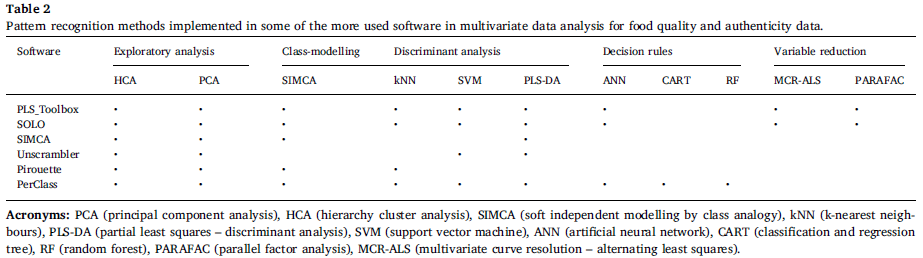
如上所述,多变量监督方法分为两组(i)资格或分类方法和(ii)量化方法。反过来,根据模型的构建方式,传统的分类方法分为判别分析方法和类建模方法。判别分析,即PLS-DA,通过建立训练对象定义的不同类之间的边界,而类建模方法,即SIMCA,定义包含每个类对象的连续封闭空间域。然而,模型生成的决策树方法(DT),CART,或RF,不建立数据在不同的类的分离如上方法但样本分为子集(或类)基于某些变量的值,重复这个过程在每个派生的样本子集。因此,分类是基于一组连接的决策,类似于人工神经网络(ANN)。图2(a)显示了用于分析评估食品质量和真实性的最常见的数据挖掘/化学计量方法的简单流程图,图2(b)显示了这些方法如何操作的简图。表1列出了它们的一些优点和缺点。
上面所提到的所有方法使用阈值自动执行分类由治疗的典型的软件建立多元数据作为PLS-Toolbox(在Matlab下)(特征向量研究、佤族、美国),个人(特征向量研究、佤族、美国),SIMCA (Umetrics、瑞典)整理机,(照片背面,挪威),脚尖旋转(美国WA Infometrix)或perClass工具箱(Matlab) (perClass BV、荷兰),只列出最清楚。然而,从业者可以通过确定分类阈值来进行更可靠的分类。表2总结了多变量数据分析软件中最常用的数据挖掘方法。这篇论文回顾和描述了这些替代的数据挖掘/机器学习方法的使用。支持向量机(SVM)、CART和RF)在食品分析领域的应用。我们提供了一些例子来说明这些技术在这一研究领域的潜力。

2.背景
2.1一些基本术语
分析实验室的自动化和电脑化带来了许多变化;其中之一是大量数据的获取,产生了一个新的科学学科,称为“大数据科学”,它已经对许多科学学科产生了强烈的影响。在化学中,“大数据”一词指的是大量复杂的数据集,其中包含有用的和不明显的化学相关信息,必须使用复杂的数据分析工具来提取(Parastar & Tauler, 2018)。然而,拥有大量数据并不意味着可以提供充分的答案,除非应用了正确的数据处理工具。收集数据并不等同于拥有信息;必须对数据进行处理和解释,以便将它们转换为对用户或分析人员有用的信息。大数据的正确使用,以及它如何满足实验室认证中的国际标准化组织/国际电工委员会17025的要求已经有所描述(Ghernaout等人,2018)。
用来指称这类工具的命名法取决于所研究的领域。分析化学是术语变化最大的领域。一些作者使用术语“模式识别方法”或“多变量分析方法”,但最常用的术语是“化学计量工具”,指的是用于处理化学相关数据的方法。化学计量学最初被定义为一种分析和测量科学的方法,它使用数学、统计和其他形式逻辑的方法来确定(通常是通过间接手段)那些很难直接测量的物质的属性(Lavine, 2000)。目前,国际纯化学与应用化学联合会(IUPAC)认为化学计量学是一门通过应用数学或统计方法将对化学系统或过程的测量与系统状态联系起来的科学(Hibbert, 2016)。在工程领域,这些处理信号或图像的技术类型通常被称为“计算智能”或“人工智能”工具。IUPAC将人工智能定义为机器能够执行类似人类的智能功能,如学习、适应、推理和自我校正。目前的主要应用领域是专家系统、计算机视觉、自然语言处理、机器人技术和语音合成与识别(Kingston & Kingston, 1994)。其他作者将这个术语定义为几种学科的相互作用,如计算机科学、控制论、信息论、心理学、语言学和神经生理学。人工智能是计算机科学的一个分支,涉及智能计算机的研究、设计和应用(Lu et al.,2012)。人工神经网络(ANN)是该领域应用最广泛的算法。它们基于网络中相互连接的一系列“节点”或“人工神经元”,试图模拟人脑中的神经元网络(Hibbert, 2016)。由于ANN的应用不同,本研究没有对其进行解释,尽管它通常也被归类为数据处理的一种替代方法(Marini, 2009;Ropodi等,2016;Yu等,2018)。
在卫生保健和生物学领域(例如,医药、制药、生物学和生物技术),“生物信息学”一词经常被使用和定义为包括开发和利用计算设备来存储、分析和解释生物数据的学科(Duffus等人,2007年;常用机器学习、统计和数据科学术语词汇,2019年。URL https://www.analyticsvidhya.com/glossary-of-common-statistics-and-machine-learning-terms /。访问25.02.2019)。
2.2 数据挖掘与机器学习
“数据挖掘”是一个通用的术语,它包含了所有这些工具,而不管它们在哪个研究领域被使用。该术语出现于20世纪60年代,但直到80年代才随着“数据库中的知识发现”(knowledge discovery in databases, KDD)的概念而得到巩固(Han et al.,2012;Mikut & Resichl, 2011)。术语“机器学习”通常也用于同样的目的(Zheng et al., 2014)。这两个术语通常可互换用于指所有这些处理数据技术,尽管严格地说,它们之间可以观察到一些差异。
数据挖掘可以用于描述性目的(即显示数据集元素之间的相似性),也可以用于预测性目的(即基于先前构建和验证的模型预测新数据的特定特征)。它基于对大量数据的收集、存储和处理,以便对特定问题做出最佳决策。这是一个跨学科的领域,其总体目标是揭示来自任何来源的数据之间的关系。为此,使用复杂的数据处理工具来检测和识别原始大数据集特有的隐藏模式、关联和结构,或者从大数据库中选择和过滤有用的信息。机器学习的概念也被称为以最智能的方式(通过开发算法)处理海量数据以获得可操作的见解的技术。在这些技术中,我们希望算法能够在没有明确编程的情况下学习。因此,数据挖掘指的是一般领域,而机器学习只指所使用的算法,它与模式识别相关联。
2006年在香港举行的IEEE国际数据挖掘会议确定了在研究界最具影响力的10大数据挖掘算法:C4.5、k-Means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、Naive Bayes和CART。一份调查论文被发表,描述的是每一个算法的基础。本文将考虑其中的SVM和CART。
此外,数据挖掘方法被分为四类机器学习:(i)基于信息的学习,(ii)基于相似度的学习,(iii)基于概率的学习,(iv)基于错误的学习。一般来说,数据挖掘方法(如CART和RF)属于基于信息的学习范畴,而SVM属于基于错误的学习范畴。我们认为这种分类是非常合适的,因为这些方法是根据它们如何为分类模型的每个对象/样本类建立不同的区域来分类的。
2.3 .食品分析中的数据挖掘
近年来,数据挖掘在食品分析领域的应用越来越频繁,将模式识别技术或方法和化学计量学工具的概念留给了用于处理数据的算法。数据挖掘和化学计量学代表了非常相似的概念。事实上,唯一的区别在于,化学计量学已经被用于参考机器学习技术的应用,以便从主要是化学或物理化学性质的数据中获得材料系统的信息,而数据挖掘被广泛用于许多其他领域,例如安全、面部识别、定制营销、医疗诊断、空中导航等。
研究人员回顾了化学计量学中使用越来越多地的一些数据挖掘方法,即探索性数据分析、人工神经网络、模式识别和数字图像处理。数据挖掘方法广泛应用于食品质量领域,以验证是否符合法规和质量差异要求,从而确保食品的真实性。除此之外,消费者越来越需要生产商提供更多关于食品的信息和知识。
食品行业具有高度的竞争性和全球性,因此食品生产商寻求在新兴的国内和国际市场中巩固地位,并使其产品与众不同。产品差异化是在该领域的全球市场上取得领先地位的关键。例如,战胜竞争对手的一个好策略是利用食物的化学成分或感官特性的差异。因此,发展快速、可靠的分析方法来鉴定食品是分析化学的一个发展趋势。这促进更强大分析仪器的发展和使用新的方法,以获得更多和更好的关于研究对象/样本的资料。这方面的一个例子是开发出了更先进的传感器,这些传感器可以以高水平的细节来监测食物,收集大量的数据。因此,需要传统数据处理技术之外的其他方法。
传统上,化学计量学用于食品分析化学领域,指的是使用众所周知的常规方法,如主成分分析法、知识网络法、SIMCA法、偏最小二乘法,以及应用于二阶数据的算法,如平行因子分析和多元曲线分辨率交替最小二乘法。尽管如此,正如导言部分所解释的,在食品分析中使用最新的数据处理方法变得越来越频繁,因为它们比以前引用的传统方法显示出优势和更大的能力。
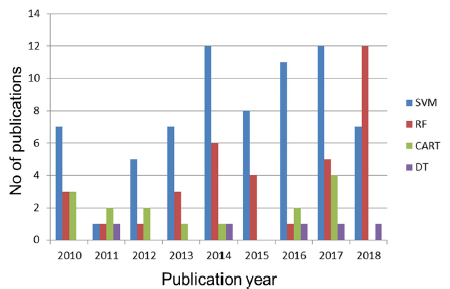
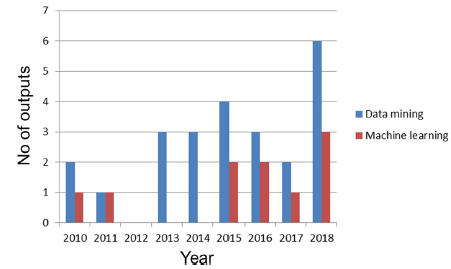
图3显示了近年来应用数据挖掘方法的食品化学出版物的趋势图。可以看出,SVM方法是使用最广泛的方法;然而,在过去的几年里,几乎没有在食品化学中使用的RF算法已经变得更加广泛,并且在2018年,使用RF算法的论文数量已经是使用SVM算法的三倍。此外,图4显示了近年来在食品分析化学领域发表的论文中“数据挖掘”一词的使用增加。
3.替代方法
在大多数情况下,报告的研究应用传统的多变量模式识别方法,主要目的是分析食品识别信号之间的相似性,根据各种标准(例如,植物或动物物种、地理来源)对食品进行分类,检测掺假和其他不符合项,并预测与食品质量相关的属性,如抗氧化能力和稳定性。几位作者回顾了已发表的关于这些方法使用的研究。
最近,一份全面而有价值的综述概述了大型分析化学数据集分析的所有阶段。然而,它只考虑了传统的数据处理方法和SVM,而忽略了新的数据挖掘方法,如CART、RF等。类似地,最近的其他评论集中在传统的化学计量学方法上,没有提及这些替代方法。这表明数据挖掘方法在分析化学领域,特别是在食品化学中的应用是相对较新的。
仅考虑SVM、CART和RF方法,第一种方法是食品分析化学中使用最广泛的方法,其研究数量比其他方法都要多(图2)。支持向量机的目标是利用最大化方法在空间中寻找最佳的超平面来区分不同类别的目标/样本。目标是最大化“边际”,它是基于从超平面到最近样本的距离的总和,也就是说,那些正确地分类到他们相应的类;支持向量机对误分类样本的数量进行惩罚。SVM算法使用一组被定义为核的数学函数。内核函数将原始数据转换为所需的格式。如果超平面建立在原始空间中,支持向量机模型采用线性核(与PLS-DA算法工作类似);如果建立在不同的空间(如高维空间),支持向量机模型是非线性的,必须使用备用核函数作为径向基函数(RBF) 。
SVM相对于PLS-DA的主要优势在于,当不同类的区域不够明显时,它会在这些区域之间产生分离。然而,由于PLS-DA只对原始数据进行偏最小二乘回归,而SVM则考虑了数据在高维空间的转换,因此使用PLS-DA进行分类要比SVM更容易、更快。支持向量机在食品分析化学领域有不同的用途:(i)根据产地对食品进行分类;(ii)进行感官评估;(iii)检测掺假;(iv)定量分析化合物;(v)进行质量控制。
DT是最流行的分类机器学习方法之一,也被广泛应用于选择特征来确定食品质量。DT是序列模型,它在逻辑上组合了输入变量的数值与阈值或名义属性与一组可能值之间的简单比较序列。DT将变量空间划分为矩形区域,并通过从树的根节点移动到叶节点来预测与特定实例相关的标签,叶节点中的每个标签对应于一个类。这些结果中的每一个都创建了额外的节点,这些节点扩展到其他可能性中。这样就创建了一个类似树的结构。节点有三种类型:概率节点、决策节点和终端节点。通过为从根到树中的叶子的每个路径创建单独的规则,可以将DT转换为一组规则。因此,对新样本的分类从树的根节点开始,然后沿着与其结果相适应的分支进行。最著名的DT方法是CART,它是一个单独的树,它显示了许多分支,其中数据集根据所选的决策被分割,并且这个过程需要经常重复。比喻地说,CART意味着通过生长和修剪来建造一棵树。
当单独使用时,DT模型可以通过使用增强或袋装来组合成整体,从而产生比任何其组成模型更好的预测结果。Boosting和bagging是指利用整个数据集的随机子集来构建一组小树,从而对单个树进行连续的改进。这些合并的DT称为“集成方法”,有时也称为“决策森林”。这背后的主要思想是结合几个单独的分类器来获得一个优于它们中的每一个的分类器。这两种集成方法的主要区别在于迭代。Boosting在每次运行时对单个实例进行迭代加权,并从分类错误的实例中学习连续的模型,而bagging则生成独立的模型,每个模型都来自不同的数据集。bagging最著名的方法之一是RF。图5显示了boosting、bagging和random forest集成过程的差异。
RF包括一组随机不同的树,每个树都是从自己的自举样本中构建的,即使用不同组随机选择的输入变量构建的决策树的组合。图6图示了RF方法的操作:六个决策树形成一个(非常小的)随机森林进行分类;树甲、树乙和树戊分配给红色类别,然而树丙和树丁分配给绿色类别,树己分配给黄色类别,因此随机森林将大多数的对象分类为红色。与其他分类方法如偏最小二乘法或SVM法相比,RF法的另一个优点是能够在单个过程中直接将一组样本/对象区分为多于两个的多个类别(即多类别分类问题)。

4.在食品认证中的应用
表3回顾了最近的论文(即自2010年以来发表的论文),其中SVM、DT、CART和RF在食品分析化学中的应用,以及其他更常规的化学计量学方法。如引言部分所述,RF几乎没有用于食品分析化学。然而,近年来一些论文显示了它在这一领域的潜力。此外,已经开发了新的软件,在食品化学中使用光谱技术应用RF。
表3 参见原文
为了保证模式识别监督模型的可靠性,最重要的一个方面是验证步骤。这是评估多元模型中获得的分类/量化率质量的基础。构成验证集或测试集的此阶段中使用的样本/对象应不同于培训阶段中使用的样本/对象。因此,建议使用外部验证集。然而,有时研究样本的总数非常有限,不可能产生外部验证,因此进行内部交叉验证。因此,不同多变量模型的质量性能特征是根据交叉验证步骤中获得的结果来计算的。从这个意义上说,表1中收集的论文中有34篇应用了内部交叉验证,41篇应用了外部验证。
接下来,对收集到的论文进行全面的描述。为此,考虑了两种方法:支持向量机方法和决策树方法。此外,所有缩写或首字母缩略词的含义都在表3的底部。
4.1 .支持向量机方法
4.1.1 .水果和果汁
水果和果汁认证的研究主要集中在农药、添加剂等成分的测定、掺假检测以及根据地域来源进行分类。如Guo et al. 开发了不同的枣质量控制模型,采用LDA、LS-SVM和BPANN构建分类模型,对四个地理区域的样本进行分类。此外,用PLS、LS-SVM和BPANN对总糖、总酚、总酸的含量和总抗氧化活性进行了定量分析,结果表明,与传统化学计量学相比,LSSVM预测模型的结果最好。
4.1.2蜂蜜和糖
蜂蜜是蜜蜂从花蜜中提取的一种甜味物质。使用支持向量机(SVM)的大多数研究都是基于不同地理区域的商业蜂蜜的分类,主要应用光谱和色谱分析技术。在这方面,Alami等人开发了一个区分法国和摩洛哥蜂蜜的模型,对所有样本进行了正确分类。另一方面,魏等人从中国不同地区采集蜂蜜样品。此外,蜂蜜样品的花的来源是用流变特性预测的。关于糖的鉴定,拉米雷斯-莫拉莱斯等人,应用近红外光谱和支持向量回归机(SVR)进行糖业白利糖度和蔗糖参数的质量控制。
4.1.3烈酒和烈性饮料
大多数论文集中于对不同的饮料进行质量控制,以检测与其他假冒饮料的掺假。值得一提的是,程等人发表的研究中,作者在应用对不同类型的中国白酒进行分类之前,测试了使用主成分分析和偏最小二乘法的两种数据约简方法。总的来说,作者得出结论,用偏最小二乘法减少数据是最好的。
4.1.4肉
关于肉的认证,报告的工作集中于使用气相色谱-质谱或电子鼻收集的挥发性化合物的分析,以进行质量控制,从而区分新鲜肉和冷藏肉。
4.1.5牛奶及乳制品
Majcher等人利用SPME-MS作为分析测量技术,开发了一种快速认证“原产地”保护的奶酪的方法。采用的分类方法有LDA、SIMCA和SVM。SVM测试集的分类准确率最高,达到97.9%。
4.1.6植物产品
本小节收集了与使用光谱分析(紫外-可见光谱、傅里叶变换红外光谱、近红外光谱、拉曼光谱和电感耦合等离子体光谱)、伏安和色谱(高效液相色谱)分析技术鉴定胡椒、茶、可可、咖啡和大米相关的研究。在这些作品中,SVM被用于对食品进行质量控制和真实性评估。其中最重要的一项工作是由Teye et al. 进行的,其中开发了用于区分可可豆样品的FDA、kNN和SVM分类模型。结果表明,SVM的分类效果优于kNN和FDA,准确率达100%。
茶叶真实性研究的重点是区分植物或地理来源。其中,刘等(刘等,2014)的研究成果最为突出,他们将伏安法作为一种分析技术,将整个分析信号用于建立分类模型
4.1.7植物油
值得注意的是,植物油的鉴定主要是应用色谱技术,而不是其他食品,其中更常见的是使用光谱技术。此外,高效液相色谱结合不同的检测系统比气相色谱更常用于鉴定橄榄油。
所有报道的研究都集中在:(ⅰ)检测掺假;(ⅱ)核实地理来源;(ⅲ)对不同种类食用油的鉴别。此外,还报告了橄榄油与其他植物油混合物的定量以及根据品种进行的分类。
4.1.8葡萄酒
食品真实性的另一个相关方面是品种认证。这通常是关于葡萄酒分析的研究结果,因为葡萄酒的化学成分除了受农艺条件影响外,还受葡萄的种类影响很大。一个吸引人的战略是利用化学成分的差异,将公认的有质量差异的食品印章标记为“受保护产地”(PDO)或“受保护地理标志”(PGI)。因此,重要的是开发快速的方法来鉴定这种受保护的食品。从这个意义上说,科斯塔等人报告了一项基于葡萄酒不同参数分析的研究,并应用当时的SVM来区分巴西葡萄酒和乌拉圭葡萄酒;分类模型的准确率达到79.97%。马泰罗-维达尔等人开发了基于多酚特征的LDA、SIMCA和SVM分类模型,以区分来自西班牙PDO的葡萄酒“Rias Baixas”和“Ribeira Sacra”。
4.1.9其他
在这一类别中,包括为确保豆腐和醋的质量和真实性而进行的研究。徐等人应用傅里叶变换红外光谱分析豆腐的货架期。对不同年龄(29-161天)的样本进行测量。在随后的统计分析中,不同的预处理方法在偏最小二乘法和SVM多元模型的发展之前被测试。对模型进行了评估,SVM是最佳选择,因为它获得了最低的预测均方根误差(RMSEP)。尽管与偏最小二乘法的差异如此之小,作者得出结论,偏最小二乘法应该被使用,因为它是低复杂度的。鲍等人开发了白醋白利糖度和酸碱度的质量控制分析方法。本研究值得注意的是在使用最小二乘SVM之前应用偏最小二乘来选择潜在变量,这些潜在变量被用作最小二乘SVM的输入来开发校准模型。通过估计相关系数(r)、校准和预测的均方根误差(RMSEC & RMSEP)和剩余预测偏差(RPD)来评估模型的预测能力。
4.2决策树方法:CART和RF
4.2.1水果和果汁
有机食品受到顾客的青睐,在过去的几年里,有机食品的销售额不断增加。已发表的有关水果和果汁认证的科学论文集中在区分生态产品和非生态产品以及检测添加剂方面。Maione等人开发了一种ICP-MS分析方法来区分有机葡萄汁和传统葡萄汁。此外,他们对不同的数据挖掘方法(SVM、CART和MLP)进行了比较,得到的结果表明,所有的方法都达到了预期的目的。
4.2.2蜂蜜
蜂蜜的质量因花和产地的不同而不同。传统的方法是基于一些物理化学参数的测量,这些参数是耗时的,并涉及到溶剂的高消耗。为此,Popek 等人提出了结合CART的不同分析方法,以减少分析的时间和复杂性。
4.2.3 酒精饮料
Martínez-Jarkuín等人开展的这项研究是基于将质谱技术与主成分分析和RF技术相结合,以区分龙舌兰和传统加工的墨西哥龙舌兰。这项工作最引人注目的是应用RF选择变量的数量,这是在新的主成分分析模型中使用的。令人惊讶的是,当主成分分析(PCA)是一种无监督的模式识别方法时,它被用作一种分类方法,该方法仅应该用于探索数据集中样本的可变性和/或当数据的维数降低时用于筛选固有的样本分组。然而,RF本身是一种多元分类方法,并不适用于这一目的
4.2.4牛奶及乳制品
Fabris等人(Fabris et al.,2010年)利用PTR-TOF-MS获得的数据开发了不同的多变量分类方法,以便在特伦汀格拉纳奶酪在不同条件下由牛奶商店生产时对其进行质量控制。为了选择最佳的数据挖掘方法,利用PDA、DPLS、SVM和RF建立了四个二元分类模型。最后,他们得出结论,所有的方法都提供了相似的性能。
4.2.5米饭
大米是许多发展中国家和最不发达国家的主食。有很多国家生产大米,中国是世界上最大的大米生产国;因此,全球市场的差异化对生产商来说很重要。在这个意义上,已报道的研究集中于根据地理来源对水稻进行分类(Kyu等,2017;(Mahdavi等人,2015;翁等,2018))。
Maione等人(Maione, Lemos Batista, Campiglia, Barbosa, & Barbosa, 2016b)开发了不同的分类方法来区分水稻样品的地理来源。为此,作者采用了SVM、RF和MLP方法。他们使用以下性能指标评估了这些多元分类方法:准确性、敏感性、特异性和接受工作曲线下的面积;在所有情况下,SVM和RF的结果都优于MLP。
4.2.6茶
利用RF根据植物源和地理来源对茶叶进行分类,并区分不同品种的茶叶。倪等建立了几个分类模型来区分中国不同地区的绿茶。他们用LDA、PLS-DA和DT比较了结果。采用DT时,可获得最佳效果。
4.2.7植物油
食用植物油在全球是一种重要的食品,许多食用植物油存在于世界不同地区的几种饮食中,如地中海饮食中的橄榄油,它是西班牙、意大利和希腊的特色,或者是亚洲的种子油。获得一些高价植物油的过程是昂贵的,因此为了降低生产成本,这些植物油容易被掺杂。为此,目前需要确保植物油的真实性,以便检测这种掺假。在这方面,已发表的论文主要集中在掺假的检测,根据植物和地理来源的食用油的鉴别。尽管有一项研究因使用RF方法非常规而引人注目,但艾等人分析了六种不同植物油(茶、橄榄、油菜籽、玉米、向日葵和芝麻油)的脂肪酸组成,并应用RF作为无监督技术进行聚类分析,以检验油样是否存在自然分组。
4.2.8葡萄酒
在葡萄酒行业中,根据地理位置和品牌来源进行的真实性评估会影响消费者的选择。Loannou-Papayianni等人就是这种情况,他们开发了一种分析方法,利用FTIR和CART鉴定塞浦路斯传统葡萄酒,并将其与其竞争对手区分开来。戈麦斯-梅雷等人将气相色谱-质谱联用技术与RF和MLP相结合,以确保加利西亚(西班牙北部的一个地区)酿造的葡萄酒得到分类;他们得出结论,机器学习方法的应用可以确保不同品种和产地的不同白葡萄酒的真实性。
5.结束语
SVM、CART和RF是另一组模式识别方法,它们在食品质量和真实性领域产生了良好的前景。仅考虑这三种方法,SVM是迄今为止使用最广泛的,在大多数情况下,据说SVM有一个更好的性能相比,其他更广为人知的传统方法,如偏最小二乘法。此外,CART和RF是目前用于食品领域的替代模式识别方法。在代谢组学等其他相关领域,一些作者已经强调了这些机器学习方法与传统技术相比的优势。然而,尽管CART和RF的价值已被广泛证明并产生了突出的结果,但将它们用于食品分析化学研究的报道仍然很少。
参考资料:
- Jiménez-Carvelo A M, González-Casado A, Bagur-González M G, et al. Alternative data mining/machine learning methods for the analytical evaluation of food quality and authenticity–A review[J]. Food research international, 2019, 122: 25-39.
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/food-quality-ai.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
FOOD CHEM| 安徽农业大学宛晓春团队:基于GC-MS和GC-IMS表征三种茶制成的乌龙茶的香气特征
该研究基于采用GC-IMS、GC-IMS、感官评价和OAV测定等方法,对水仙、黄玫瑰和紫玫瑰的新鲜茶叶和乌龙茶的香气特征进行了综合分析。其中,苯乙醛和3,5-二乙基-2-甲基吡嗪是黄牡丹茶的香气活性成分。与水仙相比,黄玫瑰和紫牡丹的挥发物和花香味明显更多。此外,使用GC-IMS鉴定出27种挥发物,表明该联合方法有助于更好地了解品种对茶树香气的影响。
-
ACS Omega:当机器学习和深度学习成为食品化学中的大数据
撰文:梁瑞 编辑:肖冉 今天给大家介绍一篇由Tseng等人,于2023年4月发表在ACS Omega上的(JCR分区:4.132/Q2)一篇综述性文章。该综述重点介绍了一些著名的食…
-
基于二维相关光谱与卷积神经网络的食用油产地溯源与掺假分析
今向大家介绍一篇来自武汉轻工大学的刘言等人在SPECTROCHIM ACTA A上发表的一篇论文。该研究基于食用油的二维相关光谱并设计卷积神经网络(CNN)对食用油的同步相关谱和异步相关谱进行分析。用一组不同产地的芝麻油和另一组掺有其他植物油的橄榄油对该方法进行了评价。两个数据集的预测准确率分别为97.3%和88.5%。
-
TRENDS FOOD SCI TECH|光谱技术结合深度学习方法在食品品质检测中的应用
浙江大学生物系统工程与食品科学学院应义斌教授课题组在食品顶级期刊《Trends in Food Science & Technology》发表综述《Food and agro-product quality evaluation based on spectroscopy and deep learning: A review》。该文讨论了传统化学计量学方法在提高模型性能、处理复杂结构的光谱噪声以及全局回归、局部回归和模型传递上的一些局限性。
-
系统综述(2013-2020年):分析技术结合化学计量学鉴别食用油地理来源
过去十年,随着消费者对来自世界各地的食品有了更多的认识,全球高质量的进口食品市场急剧增长。许多国家要求食品贴上原产地标签,以保护消费者对食品真实特征和原产地的需求。本文介绍了利用各种分析工具结合多元分析对油品地理来源的验证所作的努力。对流行的分析工具进行了讨论,并指出了强调地理认证研究趋势和用于传播的首选期刊的科学计量评估。
-
使用机器学习方法评估草莓树果实提取物在粉剂及溶剂系统中的稳定性
今天给大家介绍一篇由Astraya等人合著,于前段时间发表在Food Chemistry上的一篇研究型文章。文章中作者为了模拟酚类化合物在不同储存条件下的降解动力学,建立了3种机器学习模型。
-
中国科学院上海技术物理研究所万雄课题组:基于β-胡萝卜素拉曼光谱定量检测的橄榄油鉴别
采用激光共聚焦拉曼技术与基于DFT的拉曼光谱相结合,准确分析了植物油的成分,并识别出低成本的仿制橄榄油。
-
基于图像识别的饮食评估系统
今天给大家介绍一篇由Kalliopi V. Dalakleidi等人,于2021年7月8日发表在Advances in Nutrition(IF=11.567)的一篇综述性文章。该综述描述了用于饮食评估的计算机视觉方法的最新进展,并介绍了基于图像的食物识别系统 (IBFRS) 在专业饮食实践中的最新应用。
-
结合光谱学和机器学习改进食品分类
今天介绍一篇最近由布鲁塞尔自由大学的I. Magnus等人前段时间发表在Food Control上的一篇文章。旨在用于无损产品鉴定的传统数据分析处理技术基础上进行新型算法开发,通过结合紫外线、可见光、近红外反射光谱和荧光光谱的信息和产品流中的食品安全和质量评价,实现识别外来物体。
-
FOOD CHEM|海南大学云永欢课题组:高光谱成像技术结合数据融合的罗非鱼鱼片新鲜度快速检测研究
该文研究了两种波段范围的高光谱成像系统(可见-近红外光谱(Vis-NIR)和近红外光谱(NIR))在冷藏期间测定罗非鱼鱼片中挥发性盐基氮(TVB-N)含量的潜力。利用Vis-NIR和NIR数据,建立了高光谱图像中罗非鱼鱼片平均光谱与其TVB-N含量之间的校正模型,并采用数据融合和多种变量选择方法对模型进行优化。最后,采用优化的模型来实现罗非鱼鱼片中TVB-N含量的可视化分布。结果表明,高光谱成像技术结合数据融合和变量选择等化学计量学方法在罗非鱼鱼片新鲜度无损评价分析中具有可行性。