本期分享中科院计算所蒋树强研究员团队和美团合作发表于IEEE TPAMI2023的研究工作“Large Scale Visual Food Recognition” (Weiqing Min, Zhiling Wang, Yuxin Liu, Mengjiang Luo, Liping Kang, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang*) 。IEEE TPAMI全称为IEEE Transactions on Pattern Analysis and Machine Intelligence, 是模式识别、计算机视觉及机器学习领域的国际主流期刊,2022年公布的影响因子为24.314。


以下内容转自FoodComputing公众号
导语
本期分享中科院计算所蒋树强研究员团队和美团合作发表于IEEE TPAMI2023的研究工作“Large Scale Visual Food Recognition” (Weiqing Min, Zhiling Wang, Yuxin Liu, Mengjiang Luo, Liping Kang, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang*) 。IEEE TPAMI全称为IEEE Transactions on Pattern Analysis and Machine Intelligence, 是模式识别、计算机视觉及机器学习领域的国际主流期刊,2022年公布的影响因子为24.314。
由于食品在人们生活中的基础性地位,来自物联网、社交网、互联网等各种网络产生的海量食品多媒体数据在食品工业、膳食营养和健康管理等诸多领域蕴含着广阔应用前景和巨大社会价值,催生了“食品计算”这一新兴方向。食品图像识别作为食品计算的一项基本任务,在膳食选择、智能化的营养摄入和评估中起着重要作用。相比常规图像分类数据集,当前主流食品图像数据集规模较小,不足以建立更先进的食品图像识别模型,为此我们构建了国际上规模最大的食品图像识别数据集Food2K,包括2000类食品和超过100万的食品图像。在此基础上,进一步提出了一个面向食品图像识别的深度渐进式区域增强网络。该网络主要由渐进式局部特征学习模块和区域特征增强模块组成。前者通过改进的渐进式训练方法学习多样互补的局部细粒度判别性特征(如食材相关区域特征),后者利用自注意力机制将多尺度的丰富上下文信息融入到局部特征中,进一步增强特征表示。在Food2K上进行的大量实验证明了所提出方法的有效性,并且在Food2K上训练的网络能够改进各种食品计算视觉任务的性能,如食品图像识别、食品图像检索、跨模态菜谱-食品图像检索、食品检测和分割等。我们期待 Food2K及在Food2K上的训练模型能够支撑研究者探索更多的食品计算新任务。
论文链接:
数据集、代码和模型下载地址:
引言
食品计算[1]因能够支撑许多食品相关的应用(如膳食营养和健康管理)得到越来越广泛的关注。食品图像识别作为食品计算的一项基本任务,在人们通过辨认食物进而满足他们生活需求方面发挥着重要作用。这也是许多健康应用中的重要步骤,如食品营养理解和饮食管理。此外,食品图像识别是细粒度视觉识别的一个重要分支,具有重要的理论研究意义。
现有的工作主要是利用中小规模的图像数据集进行食品图像识别,如ETH Food-101、Vireo Food-172[6]和ISIA Food- 500。由于食品类别和图像数量的不足,不足以支撑更复杂更先进的食品计算统计模型的建立。考虑到大规模数据集已成为许多常规图像分类和理解任务发展的关键推动因素,因此食品计算领域也迫切需要一个大规模的食品图像数据集来开发先进的食品视觉表示学习算法,从而进一步支撑各种食品计算任务,如跨模态食谱检索和生成。为此,作者构建了一个新的大规模基准数据集Food2K。该数据集包含1,036,564张食品图像和2,000类食品,涉及12个超类(如蔬菜、肉类、烧烤和油炸食品等)和26个子类别。与现有的数据集(如ETH Food-101)相比,Food2K在类别和图像数量均超过其一个数量级。除了规模之外,作者还进行了严格的数据清理、迭代标注和多项专业检查,以保证其数据的质量。
基于该数据集,论文作者进一步提出了一个用于食品图像识别的深度渐进式区域增强网络,它能同时学习多样互补的局部特征。作者采用渐进式训练策略,首先训练具有较小感受野的浅层网络,以学习更精细的局部区域特征。接下来,逐渐训练更深的网络层,以扩大局部区域周围的感受野。相比于直接训练整个网络,这种训练策略能够使网络学习更精确的细粒度局部特征。同时引入KL散度来增强不同尺度的特征之间的差异性,使得网络学习更为多样丰富的细粒度特征。此外还提出了一种区域特征增强方法,对从网络中提取的多尺度特征执行非局部交互操作,以捕获局部特征之间的关系。最终融合了从网络中获得的全局特征和增强后的局部特征来进行类别预测。全面的评估表明了作者所提方法的有效性,并且在Food2K上训练的网络能够改进各种食品计算视觉任务的性能,如食品图像识别、食品图像检索、跨模态菜谱-食品图像检索、食品检测和分割等。
Food2K数据集
Food2K同时包含西方菜和东方菜,在食品专家的帮助下,作者结合现有的食品分类方法建立了一个食品拓扑体系。Food2K包括12个超类(如“面包”和“肉”),每个超类都有一些子类别(如“肉”中的“牛肉”和“猪肉”),每种食品类别包含许多菜肴(如“牛肉”中的“咖喱牛肉”和“小牛排”),如图1所示。图2展示了每个食品类别的图像数量。图3展示了Food2K与现有食品图像识别数据集的图像数量对比,可以看到Food2K在类别和图像数量上都远超过它们。除此之外,Food2K还具有以下特征:1)Food2K涵盖了更多样化的视觉外观和模式。不同食材组合、不同配饰、不同排列等都会导致同一类别的视觉差异。举例来说,新鲜水果沙拉因其不同的水果成分混合而呈现出不同的视觉外观。这些食品的独特特征导致了更高的类内差异,使大规模的食品图像识别变得困难。2)Food2K包含更细粒度的类别标注。以“Pizza”为例,一些经典的食品数据集,如Food-101,只有较粗粒度的披萨类。而Food2K中的披萨类则进一步分为更多的类别。不同披萨图像之间的细微视觉差异主要是由独特的食材或同一食材的粒度不同引起的,这也导致了识别的困难。所有这些因素使Food2K成为一个新的更具挑战性的大规模食品图像识别基准。

图1 Food2K的拓扑体系
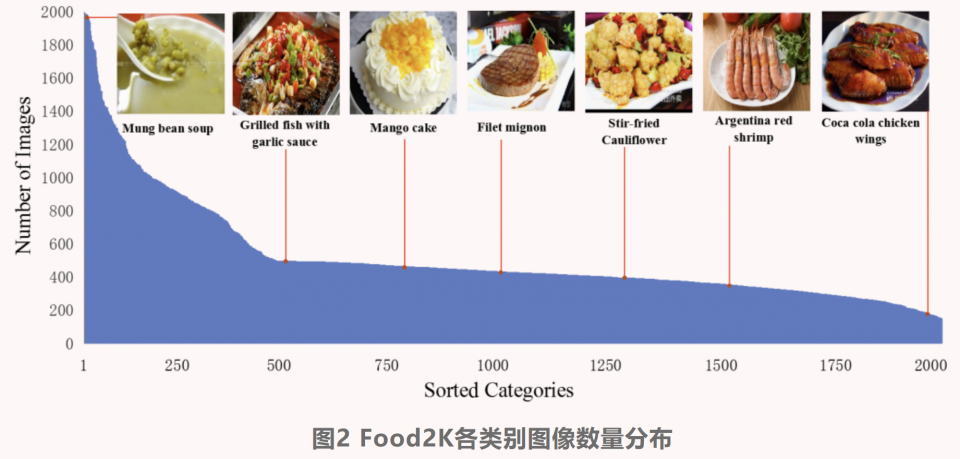
图2 Food2K各类别图像数量分布
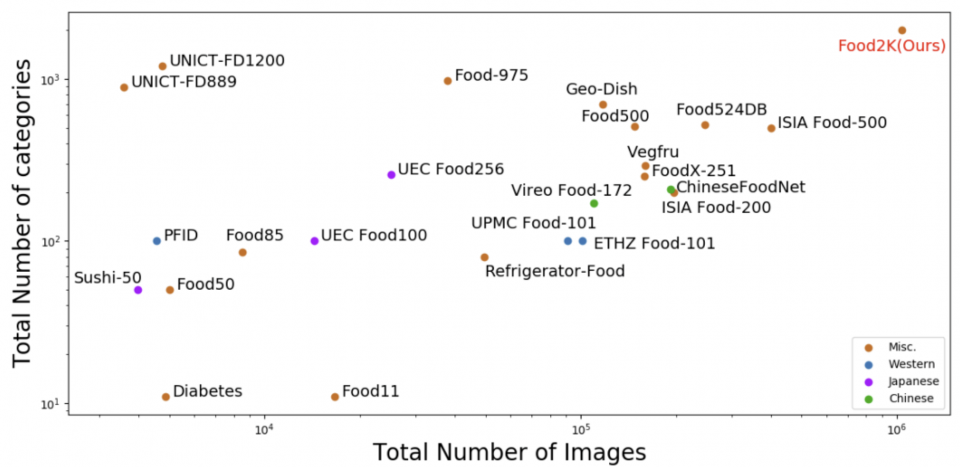
图3 Food2K与其它食品图像识别数据集比较
方法
本文提出的深度渐进式区域增强网络如图4所示,主要由三部分组成:全局特征学习模块,渐进式局部特征学习模块和区域特征增强模块。
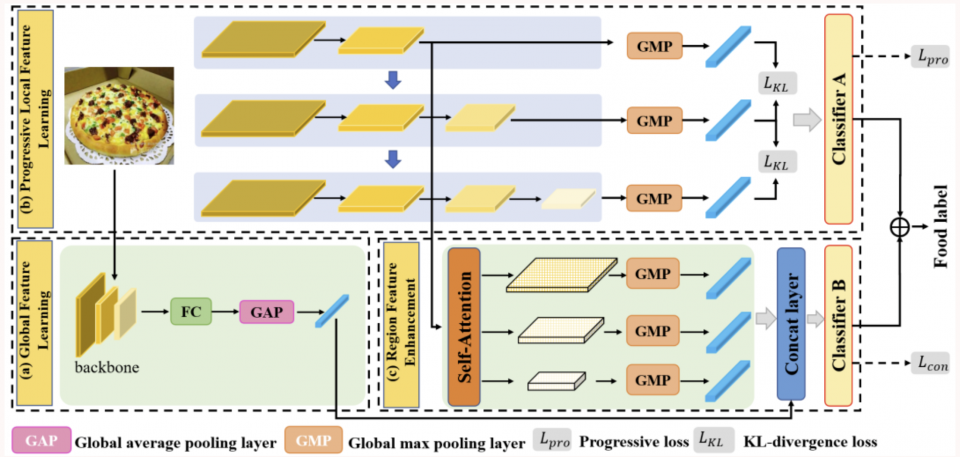
图4 深度渐进式区域增强网络框架图
结果
论文研究了Food2K在食品图像识别、食品图像检索、跨模态菜谱-食品图像检索、食品检测和食品分割五个食品计算任务上的泛化能力。具体结果详见原文。
未来工作
全面的实验证明了Food2K对于各种视觉和多模态任务具有较好的泛化能力。基于Food2K的一些潜在研究问题和方向如下。
(1)大规模鲁棒的食品图像识别 尽管一些细粒度识别方法(如PMG[12])在常规细粒度识别数据集中获得了最佳性能,但它们在Food2K上表现欠佳。虽然也有一些食品图像识别方法(如PAR-Net[13])在中小规模食品数据集上取得了较好的性能,但它们在Food2K大规模食品图像识别数据集上也并不能获得更好的性能。作者推测,随着食品数据的多样性和规模的增加,不同食材、配饰和排列等因素产生了更复杂的视觉模式,以前的方法不再适用,因此,基于Food2K有更多的方法值得进一步探究。例如,Transformers[14]在图像识别方面产生了巨大的影响,其在大规模数据集上的性能高于CNNs。Food2K可以提供足够的训练数据来开发基于Transformers的食品图像识别方法来提高性能。
(2)食品图像识别的人类视觉评价 与人类视觉对一般物体识别的研究相比,对食品图像识别进行评价可能更加困难。例如,食品具有较强的地域和文化特征,因此来自不同地区的人对食品图像识别会有不同的偏见。最近的一项研究 [15]给出了人类视觉系统和CNN在食品图像识别任务中的比较。为了避免信息负担过重,需要学习的菜肴数量被限制在16种不同类型的食物中。更有趣的问题值得进一步的探索。
(3)Cross-X迁移学习的食品图像识别 作者已经验证了Food2K在各种视觉和多模态任务中的推广。未来我们可以从更多的方面来研究迁移学习。例如,食物有独特的地理和文化属性,可以进行跨菜系的迁移学习。这意味着我们可以使用来自东方菜系的训练模型对西方菜系进行性能分析,反之亦然。经过更细粒度的场景标注,如区域级甚至餐厅级标注,我们可以进行跨场景迁移学习来进行食品图像识别。此外,我们还可以研究跨超类别迁移学习的食品图像识别。例如,我们可以使用来自海鲜超类的训练模型来对肉类超类进行性能分析。这些有趣的问题都值得深入探索。
(4)大规模小样本食品图像识别 最近,有一些基于中小型食品类别的小样本食品图像识别方法[16,17]研究。LS-FSFR[18]是一项更现实的任务,它旨在识别数百种新的类别而不忘记以前的类别,且这些数百种新的食品类别的样本数很少。Food2K提供了大规模的食品数据集测试基准来支持这项任务。
(5)更多基于Food2K的应用 本文验证了Food2K在食品图像识别、食品图像检索、跨模态菜谱-食品图像检索、食品检测和分割等各种任务中具有更好的泛化能力。Food2K还可以支持更多新颖的应用。食品图像生成是一种新颖而有趣的应用,它可以通过生成对抗网络(GANs)[19]合成与现实场景相似的新的食品图像。例如,Zhu等人[20]可以从给定的食材和指令中生成高度真实和语义一致的图像。不同的GANs,如轻量级的GAN [21],也可以用于生成基于Food2K的食物图像。
(6)面向更多任务的Food2K扩展 基于训练的Food2K模型可以应用于更多与食物计算任务中。此外考虑到一些工作[6]已经表明食材可以提高识别性能,作者计划扩展Food2K来提供更丰富的属性标注以支持不同语义级别的食品图像识别。作者还可以在Food2K上进行区域级和像素级标注使其应用范围更广。此外,作者还可以开展一些新的任务,如通过在Food2K上标注美学属性信息,对食品图像进行美学评估。
结论
在本文中,作者提出了具有更多数据量、更大类别覆盖率和更高多样性的Food2K,可以作为一个新的大规模食品图像识别基准。Food2K适用于各种视觉和多模态任务,包括食品图像识别、食品图像检索、检测、分割和跨模态菜谱-食品图像检索,具有更好的泛化能力。在此基础上,作者进一步提出了一个面向食品图像识别的深度渐进式区域增强网络。该网络主要由渐进式局部特征学习模块和区域特征增强模块组成。渐进式局部特征学习模块通过改进的渐进式训练方法学习多样互补的局部细粒度判别性特征,区域特征增强模块利用自注意力机制将多尺度的丰富上下文信息融入到局部特征中以进一步增强特征表示。在Food2K上进行的大量实验证明了所提方法的有效性。

长按关注我们
微信号|FoodAI
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/food2k.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
基于多种智能传感技术的数据融合策略及其在金华火腿品质评价中的应用
该研究针对多种智能感知技术,包括电子鼻、电子舌和计算机视觉的模式识别,提出了一种新的距离-概率分类(distance-probability classification,DPC)方法,并应用于不同老化时间下金华干腌火腿的分类评价,准确率可达到100%。同时进一步利用融合数据,建立了反向传播神经网络(BPNN)模型来预测老化时间并同时预测12种感官属性。BPNN模型在预测老化时间(R2 > 0.972)和感官属性(R2 > 0.935)方面表现出令人满意的性能。
-
基于二维相关光谱与卷积神经网络的食用油产地溯源与掺假分析
今向大家介绍一篇来自武汉轻工大学的刘言等人在SPECTROCHIM ACTA A上发表的一篇论文。该研究基于食用油的二维相关光谱并设计卷积神经网络(CNN)对食用油的同步相关谱和异步相关谱进行分析。用一组不同产地的芝麻油和另一组掺有其他植物油的橄榄油对该方法进行了评价。两个数据集的预测准确率分别为97.3%和88.5%。
-
FOOD CHEM| 安徽农业大学宛晓春团队:基于GC-MS和GC-IMS表征三种茶制成的乌龙茶的香气特征
该研究基于采用GC-IMS、GC-IMS、感官评价和OAV测定等方法,对水仙、黄玫瑰和紫玫瑰的新鲜茶叶和乌龙茶的香气特征进行了综合分析。其中,苯乙醛和3,5-二乙基-2-甲基吡嗪是黄牡丹茶的香气活性成分。与水仙相比,黄玫瑰和紫牡丹的挥发物和花香味明显更多。此外,使用GC-IMS鉴定出27种挥发物,表明该联合方法有助于更好地了解品种对茶树香气的影响。
-
可容忍传感器故障等因素的机器学习模型用于食品质量预测
今天给大家介绍土耳其坎卡亚大学计算机工程系、软件工程系,土耳其伊斯坦布尔巴赫塞希尔大学计算机工程系,荷兰瓦赫宁根大学信息技术组合作,于2020年6月3日发表于Sensors期刊上的一篇研究型文章。文章中作者提出了一种单复数投票系统(SPVS)分类方法,可以通过忽略传感器故障或其他类型的故障来提高对食品质量的评估。为了说明该方法,作者使用了牛肉切割质量评估的案例研究。
-
中国农业大学周欣团队基于宏基因组学和机器学习的蜂蜜产品溯源
今天介绍一篇来自中国农业大学昆虫学系周欣教授课题组于2022年3月发表在Food Chemistry上的文章。该文为了查询蜂蜜的地理来源,收集蜂蜜样本产生的宏基因组数据,应用机器学习方法来推断蜂蜜的地理来源。
-
海南大学姜珂副研究员:用于化学动力学/饥饿协同癌症治疗的智能异质结芬顿催化剂的开发
近日,海南大学姜珂副研究员与山东大学李春霞教授合作,采用构筑异质结的策略,联合葡萄糖氧化酶(GOx),揭示了芬顿/级联酶促反应的协同抗癌机制。相关成果以题为“Development of an Intelligent Heterojunction Fenton Catalyst for Chemodynamic/Starvation Synergistic Cancer Therapy”发表在国际学术期刊《Journal of Materials Science & Technology》(IF=10.319)。海南大学倪伟舒硕士、姜珂副研究员为该论文的共同第一作者,海南大学姜珂副研究员、张玲副教授和山东大学李春霞教授为该论文的通讯作者。
-
人体对食物的餐后反应与精准营养的潜力
今天介绍一篇由Sarah E. Berry等人前段时间发布于nature medicine的一篇文章。文中对英国(n=1002)和美国(n=100)的年轻健康成年人进行餐后代谢反应评估,并开发机器学习模型来预测人体内的甘油三酸酯(r=0.47)和血糖(r=0.77)对食物摄入的反应,这项技术有助于制定个性化的饮食策略。
-
计算机分析啤酒花衍生苦味化合物及其同源苦味受体
今天给大家介绍一篇由Andreas Dunkel等人合作,于前段时间发表在Journal of Agricultural and Food Chemistry上的一篇文章,文章中作者介绍了一个基于计算机的方法来研究啤酒花衍生苦味化合物及其同源苦味受体。
-
FOOD CHEM|海南大学云永欢课题组:高光谱成像技术结合数据融合的罗非鱼鱼片新鲜度快速检测研究
该文研究了两种波段范围的高光谱成像系统(可见-近红外光谱(Vis-NIR)和近红外光谱(NIR))在冷藏期间测定罗非鱼鱼片中挥发性盐基氮(TVB-N)含量的潜力。利用Vis-NIR和NIR数据,建立了高光谱图像中罗非鱼鱼片平均光谱与其TVB-N含量之间的校正模型,并采用数据融合和多种变量选择方法对模型进行优化。最后,采用优化的模型来实现罗非鱼鱼片中TVB-N含量的可视化分布。结果表明,高光谱成像技术结合数据融合和变量选择等化学计量学方法在罗非鱼鱼片新鲜度无损评价分析中具有可行性。
-
基于免疫层析试纸条和人工智能图像识别算法的农药多残留快速检测技术
近期,中国农业科学院农业质量标准与检测技术研究所王静教授领衔的农业化学污染物残留检测及行为研究创新团队开发了一种集成了农药残留免疫检测、图像识别、人工智能、大数据和物联网等技术的农药多残留快速检测技术。