本文提出了一种基于机器学习的双层香蕉分级图像处理系统。支持向量机是根据提取的由颜色和纹理特征组成的特征向量对香蕉进行第一层分类,接着YOLOv3对香蕉进行分类,进一步定位果皮上的缺陷区域,判断输入的是中熟类还是成熟类。第一层的精度达到了98.5%,第二层的精度达到了85.7%。总体准确率为96.4%。
摘要
今天介绍一篇来自加拿大圭尔夫大学的Lili Zhu and Petros Spachos等人于2020年7月发表的一篇论文。本文提出了一种基于机器学习的双层香蕉分级图像处理系统。支持向量机是根据提取的由颜色和纹理特征组成的特征向量对香蕉进行第一层分类,接着YOLOv3对香蕉进行分类,进一步定位果皮上的缺陷区域,判断输入的是中熟类还是成熟类。第一层的精度达到了98.5%,第二层的精度达到了85.7%。总体准确率为96.4%。
1. 介绍
为了满足食品加工行业日益提高的要求和标准,食品和农产品的质量检验工作是繁重而劳动密集型的。经过多年的快速发展,机器视觉系统已经渗透到人们生活的各个方面。机器视觉系统可以通过多种陆基和机载方法获取图像数据,并可以完成多种类型的任务,如质量安全检测、农产品分级、外来物检测、作物监测。在食品加工过程中,机器视觉系统可以收集食品的大小、重量、形状、质地、颜色等一系列参数,甚至许多人眼无法观察到的细节,来监控和操作食品加工过程。这样可以避免工人因大量重复劳动而产生的疲劳和错误。
香蕉是最重要的热带水果之一,香蕉的成熟过程非常快,大量过熟的香蕉无法进入市场。因此,研究人员对开发自动监测系统来帮助香蕉管理很感兴趣。在本研究中,提出了一种实现香蕉分级和缺陷检测的双层系统。系统由第一层分类器支持向量机和第二层分类器YOLOv3组成。包含提取的颜色和纹理信息的特征向量作为第一层分类器的输入,第一层分类器的输出连接到第二层分类器。该网络可同时提供香蕉成熟度等级分类和果皮缺陷区域检测,为进一步实现物联网系统打下坚实基础。通过与其他三种常用系统的比较,表明该系统具有较高的精度。
2. 数据集和方法
2.1 数据集
在本研究中,我们拍摄了150张不同成熟度的香蕉照片,并将它们分为三组,分别是未成熟、成熟和过度成熟(每组50张)。成熟类有两个子类,半成熟类和完全成熟类。未成熟组的香蕉仍然是绿色的果皮,而成熟和过度成熟组的香蕉果皮呈黄色,并且有不同程度的棕色斑点。然而,150个样本对于机器学习方法来说并不令人满意,因为它容易导致过拟合。因此,我们采用了数据增强技术,来扩大数据集。旋转、翻转、移位等传统的数据增强方法被广泛应用于机器学习训练。我们还使用Cycle GAN生成缺陷香蕉的图像。
图1显示了原始未成熟香蕉图像与生成的成熟香蕉图像的对比。使用Cycle GAN模型生成了150张新的成熟香蕉图像。数据扩增后的总数据集如表1所示。


Fig.1 Cycle GAN基于未成熟香蕉图像生成5张成熟香蕉图像
Table 1 经过数据扩充后的总数据集
2.2 方法
提出的香蕉分级系统包括数据增强、图像分割、特征提取和分类。图2显示了系统的流程图。

Fig.2 提出的香蕉分级系统的流程图
1)图像分割:在本工作中,为了更接近实际,图像采集是在自然光下进行的,因此背景亮度和阴影不一致,很难找到合适的阈值和完整准确的边缘来分割目标。因此,使用K均值聚类算法来处理这个任务。K均值聚类算法采用距离作为相似性的评价指标。将所有数据分配到最近的聚类中心,使每个点与其对应的聚类中心之间的距离平方和最小化。在应用k均值之前,采用秩滤波和对数变换来降低噪声,提高图像对比度。图3显示了样本分割结果。

Fig.3 图像分割步骤的样本输入(上),隐藏(中)和输出(下)
2)特征提取:对于图像,每一幅图像都有自己的特征,可以区别于其他类型的图像。这些特征将以数值或向量的形式被提取出来,以便计算机能够识别图像。常见的图像特征有颜色特征、纹理特征、形状特征。
a)颜色特征:在本工作中,由于未成熟、成熟和过成熟的香蕉具有明显的颜色特征,不需要考虑颜色空间分布,因此颜色特征是训练分类器所提取的成分之一。因此,本文提出的数据集的颜色特征是在HSV颜色空间中提取的。
由于三组香蕉的颜色特征,将HTML颜色代码与不同香蕉皮的自然颜色进行类比,得到相应的H、S、V值范围。表2说明了H和V的取值范围是不同的,这是对香蕉进行分类的两个输入特征。
Table 2 两组香蕉HSV颜色空间中的H、S、V值的范围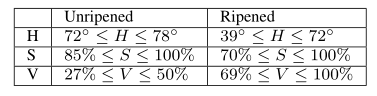
b)纹理特征:纹理是物体表面的另一种自然特征。它描述了图像像素与图像区域之间的灰度空间的分布,不会因光照的不同而发生变化。纹理特征也是一个全局特征。与颜色特征不同,纹理特征不是基于像素的特征,它们需要在包含多个像素的区域进行统计计算。
从图4可以看出,在不同成熟度的香蕉中,局部二值模式(LBP)算子可以提取出不同的纹理特征。

Fig.4 (左)分割图像;(中间)灰度图像;(右) 局部二值模式算子提取的纹理特征
3)分类:分类任务分为两个步骤。第一步是将提取的特征输入支持向量机,以分类未成熟、成熟和过度成熟的香蕉组。香蕉皮上的棕色斑点在这里不会被检测到,因为对于过度成熟的香蕉,棕色颜色应该包括在什么标准没有一致性。连接的棕色区域造成多个不规则区域的检测,将导致不准确的结果。此外,由于香蕉皮主要是棕色的,所以过熟的香蕉不需要检测棕色斑点。因此,香蕉将被分为基本组。下一步是将支持向量机输出的成熟水果图像输入到YOLOv3迁移学习模型中,检测棕色斑点,并根据棕色区域的数量将香蕉分为中熟和成熟两组。当YOLOv3模型检测到3个或更少的缺陷区域时,该样品将被视为中熟样品。另外,一个成熟的样本是由模型发现的缺陷区域是否超过三个来决定的。
4)方法评价:采用统计学中常用的评价方法准确性、灵敏度/召回率和精度对第一层分类结果进行评价。如:
为了进一步评估YOLOv3模型的性能,应用平均准确率(mean Average Precision), 交并比(Intersection over Union)和召回法来评估目标的预测位置。评估方法的定义如图6。
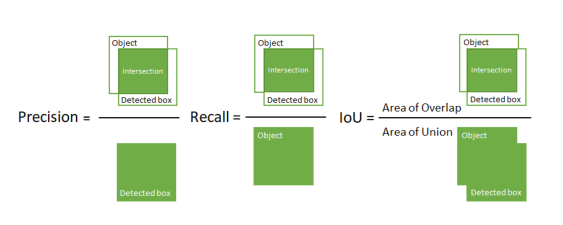
Fig.6 评价方法的定义
3. 实验结果与讨论
实验在Ubuntu 18.04.4 LTS系统上进行,使用intel coremi7-8700k CPU @3.70GHz×12处理器,32G内存,GeForce GTX 1080 Ti/PCIe/SSE2图形。
在第一分类层,使用520幅图像训练SVM分类器,使用130幅图像进行测试。将H值、V值和LBP特征组成输入特征向量A=[H V LBP]后,将所有训练图像中的A送入SVM分类器进行训练。表3为第一层分类器测试结果的混淆矩阵。由混淆矩阵可知,SVM分类器的总体预测准确率达到了98.5%(g=0.005,C=1000)。
Table 3 第一层分类器的混淆矩阵
对于第2层,“labelling”手动标记成熟组的图像中有缺陷的区域,48张被预测为成熟的图像输入到第二个预测器。图7显示了每个类的一个地面真实数据样本。

Fig.7 中熟类和成熟类的样本真实数据和预测样本
经过100,000次训练,测试结果的平均准确率为0.8137,平均交并比为76.34%,测试结果的平均查全率和准确率分别为91.32%和74.93%。预测测试图像的平均处理时间为0.051秒。高查全率和低准确度的原因是该模型检测到一些没有标注数据的数据点。根据检测区域的结果,检测区域的数量来确定该样本属于哪个子类。当检测到的区域超过5个时,这只香蕉就被归为成熟香蕉。交并比结果表明预测区域与真实值有一定程度的偏差,但这并不影响预测区域的数量。因此,表四所示的基于预测区域数量的混淆矩阵仍然有效。
Table 4 第二层分类器的混淆矩阵
4. 结论
本文提出了一种新的双层分类器来根据香蕉的成熟程度进行分级。由于原始图像中存在冗余信息,会降低分类精度,因此形成了由基本颜色和纹理信息组成的特征向量。实验结果表明,提取的特征向量辅助支持向量机分类器的准确率达到98.5%。然后YOLOv3系统检测成熟香蕉的缺陷区域,并将其分为中熟组和成熟组。该系统完成了香蕉成熟度分级任务,同时也解决了检测和输出香蕉小缺陷区域的困难。
参考文献
Zhu, Lili; Spachos, Petros Food Grading System Using Support Vector Machine and YOLOv3 Methods. 2020 IEEE SYMPOSIUM ON COMPUTERS AND COMMUNICATIONS (ISCC), 2020, 164, 106088.

原创文章,作者:FoodAI01,如若转载,请注明出处:https://www.drugfoodai.com/yolov3.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
基于数据和结构的组合建模方法筛选数据库中潜在甜味分子
今天给大家介绍一篇由Anukrati Goel等人合作的,于前段时间发表在Food Chemistry的一篇文章,文章中作者介绍了一种基于计算机驱动的方法,可以从大型天然化合物数据库中筛选出潜在的新型甜味剂。
-
浙江农科院袁玉伟产地溯源团队:基于稳定同位素和营养元素的中国稻米产地溯源研究
大米是我国重要的主食,其真实性与营养安全密切相关。今天介绍一篇来自浙江省农业科学院农产品质量安全与营养研究所和农产品质量安全危害因子与风险防控国家重点实验室李春霖和袁玉伟等人于2022年4月发表在Food Control上的一篇论文。本研究对我国粳稻和籼稻的稳定同位素和营养元素进行了比较和分析,并建立人工神经网络模型进行地理判别。建立了中国首个水稻稳定同位素和元素地理综合数据库,为中国水稻重点产区的判别提供了一种有前景的方法。
-
Bioresource Technology:智能化的方法来可持续管理和利用食物废弃物
撰文:王雪洁 编辑:肖冉 介绍 今天介绍一篇由Zafar Said等人于2023年3月在线发表在Bioresource Technology(IF=11.89)上的文章。这篇文章主…
-
基于单词嵌入的烹饪食谱无监督调整方法
今天介绍一篇由Andrea Morales-Garzon等人于2021年2月在IEEE Access上发表的文章。本文提出了一种新的无监督食谱调整方法,用于根据用户偏好调整食谱成分。为了学习食物表征和关系,创建并应用一个特定领域的单词嵌入模型。将一个单词嵌入模型与一个基于模糊的文档距离相结合,以找到适应任务中最相似的成分。作者根据营养偏好、适应类似的成分和素食以及纯素饮食限制,进行了三种不同的食谱调整。结果证实了使用特定领域语义模型来处理食谱适应任务的潜力。
-
海南大学食品科学与工程学院王露课题组:鹧鸪茶中天然α-葡萄糖苷酶和α-淀粉酶抑制剂的筛选和鉴定及分子对接分析
该研究调查了鹧鸪茶提取物对α-葡萄糖苷酶和α-淀粉酶的抑制作用,测定鹧鸪茶提取物的总酚、黄酮含量及其对α-葡萄糖苷酶和α-淀粉酶的抑制效果,并通过HPLC-ESI- qTOF-MS/MS和亲和超滤筛选鉴定其起主要抑制作用的物质及含量;利用3T3-L1细胞测定鹧鸪茶提取物对其吸收葡萄糖的影响。最后,通过分子对接分析进一步阐明了这些抑制剂对α-糖苷酶和α-淀粉酶的可能作用机制。研究表明,鹧鸪茶是一种可应用于预防和改善餐后高血糖症状的天然代用茶资源。
-
系统综述人工神经网络在食品加工过程中的建模应用
今天给大家介绍一篇由G. V. S. Bhagya Raj等人合作的,于近期发表在Critical Reviews in Food Science and Nutrition的一篇综述,文章中作者系统综述了ANN在食品加工等领域的应用进展并进行了展望。
-
FOOD CHEM| 安徽农业大学宛晓春团队:基于GC-MS和GC-IMS表征三种茶制成的乌龙茶的香气特征
该研究基于采用GC-IMS、GC-IMS、感官评价和OAV测定等方法,对水仙、黄玫瑰和紫玫瑰的新鲜茶叶和乌龙茶的香气特征进行了综合分析。其中,苯乙醛和3,5-二乙基-2-甲基吡嗪是黄牡丹茶的香气活性成分。与水仙相比,黄玫瑰和紫牡丹的挥发物和花香味明显更多。此外,使用GC-IMS鉴定出27种挥发物,表明该联合方法有助于更好地了解品种对茶树香气的影响。
-
FoodAI:基于深度学习的食品图像识别与记录系统
今天给大家介绍一篇由新加坡管理大学信息系统学院生活分析研究中心(LARC) 和Salesforce亚洲研究院合作,于前段时间在ACM SIGKDD知识发现和数据挖掘会议上汇报的一篇会议文章。文章中作者提出了一种智能食物记录系统:FoodAI,使食物记录变得便捷,帮助人们实现智能消费和健康的生活方式。
-
NutriFD:基于食物与疾病关联和治疗网络证明食物营养的药用价值
撰文:梁瑞 编辑:肖冉 今天给大家介绍一篇由Wanting Su等人,于2023年5月在Quantitative Biology上的一篇即将发表的预印本文章。本文介绍了基于食品和疾…
-
基于比色条形码组合和深度卷积神经网络的便携式食品新鲜度预测平台
今天介绍一篇来自江南大学,于2020年底发表在Advanced Materials上的一篇论文。该研究将可交叉反应的比色条形码组合和深度卷积神经网络(DCNN)结合在一起,形成了一个用于监控肉类新鲜度的系统,总体准确性为98.5%。