大米是我国重要的主食,其真实性与营养安全密切相关。今天介绍一篇来自浙江省农业科学院农产品质量安全与营养研究所和农产品质量安全危害因子与风险防控国家重点实验室李春霖和袁玉伟等人于2022年4月发表在Food Control上的一篇论文。本研究对我国粳稻和籼稻的稳定同位素和营养元素进行了比较和分析,并建立人工神经网络模型进行地理判别。建立了中国首个水稻稳定同位素和元素地理综合数据库,为中国水稻重点产区的判别提供了一种有前景的方法。
摘要
大米是我国重要的主食,其真实性与营养安全密切相关。今天介绍一篇来自浙江省农业科学院农产品质量安全与营养研究所和农产品质量安全危害因子与风险防控国家重点实验室李春霖和袁玉伟等人于2022年4月发表在Food Control上的一篇论文。本研究对我国粳稻和籼稻的稳定同位素和营养元素进行了比较和分析,并建立人工神经网络模型进行地理判别。建立了中国首个水稻稳定同位素和元素地理综合数据库,为中国水稻重点产区的判别提供了一种有前景的方法。
1. 介绍
水稻是世界上一半以上人口广泛食用的主食。作为世界上最大的稻米生产国,我国2020年的稻米产量为21.19亿吨,占世界总产量的28.9%。粳稻和籼稻是我国生产的两个主要水稻品种,具有明显的物理和籽粒品质差异。但是对于同一品种的水稻来说,单凭外观很难将其从不同地区区分出来,这就可能导致原产地标签的错误,从而获得更多的利润,也增加了消费者被欺骗的风险。为了解决这些问题,我国粳稻和籼稻急需进行产地溯源和营养元素特征鉴定。
稳定同位素结合多元素特征分析与地理气候,生产环境有关,是农产品产地鉴别的常用工具。在中国的大多数省份,人们用各种耕作方法种植各种水稻。水稻稳定同位素和元素的组合,阐明了水稻特有的地理和营养属性,可能是一种有希望的大规模地理起源判别方法。
2. 材料及方法
2.1. 样品和预处理
2017年,在全国共采集了900份样本,覆盖4个主要水稻产区和2个品种,包括东北地区(N-E, n = 243,黑龙江省、吉林省和辽宁省,均为粳稻);长江中下游平原地区(Y- R, n = 444,江苏、浙江粳稻118株,江苏、浙江、河南、安徽、江西、湖南、湖北籼稻326株);西南地区(S-W,n = 157,贵州、四川、云南和重庆,均为籼稻品种),东南地区(S-E,n = 56,福建、广东和广西,均为籼稻品种)。总共涉及17个省份和118个城市,覆盖了96%的主产区。在4个产区中,根据区域种植面积大小确定各区域的样本数量。
在每个省选取具有代表性的城市,在每个城市均匀分布的生产区域收集大约10个样本。收割后的水稻样品按照GB/T 5491-检验粮油种子的取样和减样方法在各农场进行干燥储存。每个样品采集2公斤以上的稻谷,样品在实验室室温下保存直到分析。稻谷用脱壳机脱粒,经过100目筛(<150 μm)研磨和筛分,然后在70℃风干48小时。准备好的样品保存在干燥器中,直到分析。


Fig. 1 不同地区粳稻和籼稻的外貌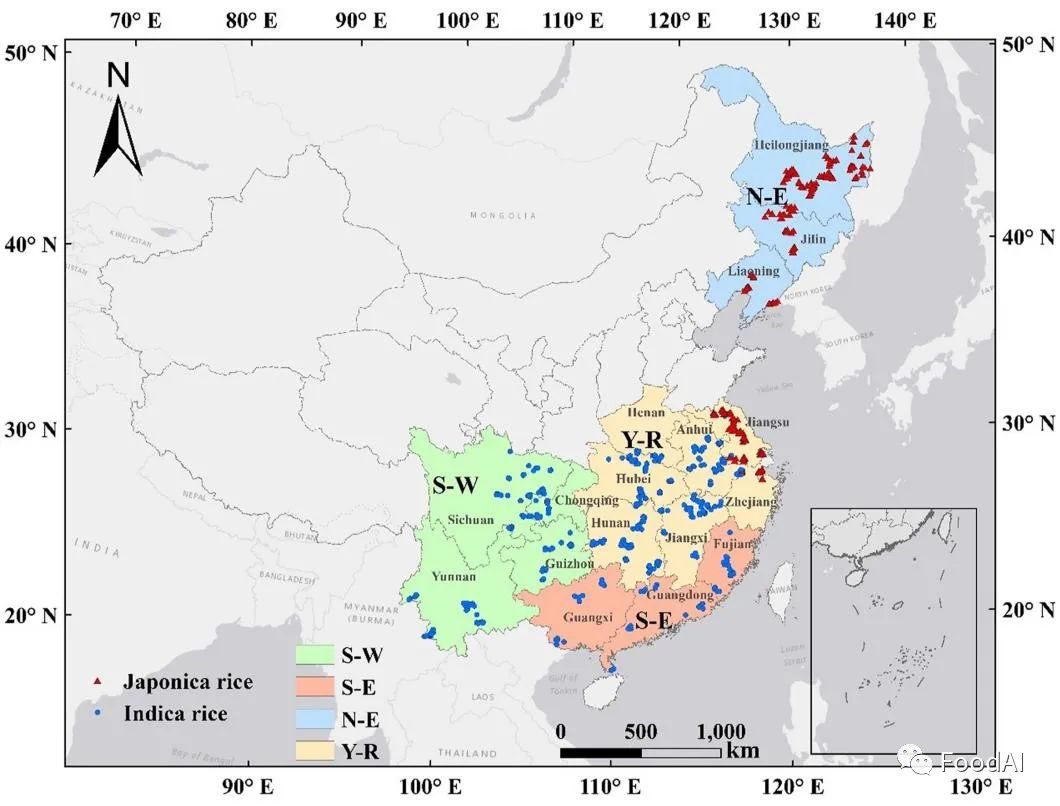
Fig. 2 样品采集地区
2.2. 稳定同位素分析和元素分析
本研究中,4种稳定同位素(δ13C,δ15N,δ13C 和 δ15N)和11种元素(包括4种常量营养元素(K、Mg、Ca、Na)和7种微量营养元素(Fe、Zn、Mn、Cu、Ni、Cr、Mo))被用于我国不同产区大米的鉴别指标。碳和氮同位素比值的分析使用元素分析仪(Elementar,德国)连接Biovision同位素比值质谱仪(Elementar,英国),氢和氧同位素比值分析使用元素分析仪(Elementar,德国)连接isprime 100同位素比值质谱仪(Elementar,英国)。采用Thermo Fisher iCAP Qc电感耦合等离子体质谱(ICP-MS, Thermo Fisher Scientific, Waltham, MA)完成大米中11种元素的测定。
2.3. 模型建立
所有模型的数据包含15个变量(4种稳定同位素和11种元素)。采用bp神经网络(BP-NN)建立定性模型。BP-NN模型是一种两层前馈网络,具有sigmoid hidden 和softmax输出神经元。在这些模型中使用了10个隐藏层。所有的样本被随机分为一个训练集(70%),一个验证集(15%)和一个测试集(15%)。该训练集通过缩放共轭梯度反向传播对网络进行误差调整。使用验证集来度量网络泛化,一旦泛化能力停止提高,就停止训练。测试集由用来理解网络性能的独立(盲)样本组成,对训练集没有影响。粳稻和籼稻模型分别重复划分10次和5次。模型性能由平均分类正确率来衡量。在Matlab R2014b版本中使用nprtool进行建模。
3. 结果与讨论
3.1. 稳定同位素和元素在粳稻和籼稻中的分布
整个数据集的粳稻和籼稻同位素和元素的平均结果如Table 1所示。粳稻δ13C、δ15N、δ2H和δ18O平均值普遍高于籼稻。粳稻δ13C值为−28.9‰~−25.1‰,略高于籼稻的δ13C值(−30.0‰~−26.6‰)。与籼稻相比,粳稻生长在更高的纬度,气候更凉爽,这降低了光合作用期间的气孔导度,并对13C有区别。籼稻的δ15N、δ2H和δ18O值的变化范围大于粳稻。因为从更广泛的产地(沿海、内陆、不同纬度)采集到的籼稻样品比粳稻多,导致不同气候和农业实践效应产生的同位素值范围更大。
2个水稻品种除Mg和Ni外,其他营养元素含量均存在显著差异(p<0.05)(Table 1)。粳稻元素含量普遍高于籼稻。所有营养元素的浓度范围大,标准差高。常量营养元素K和Na在粳稻中含量较高,微量营养元素Fe、Zn和Mn在粳稻中的含量较高,而Cr和Mo在粳稻中的含量较低。据报道,这些在粳稻和籼稻中发现的特征营养元素是通过植物土壤的生理代谢吸收过程积累的。
Table 1 粳稻和籼稻的稳定同位素和营养元素。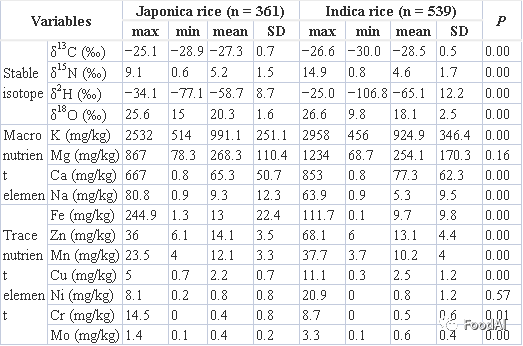
3.2. 水稻稳定同位素和营养元素的地理分布
中国四个主要产区的水稻样品具有不同的同位素和元素特征(Table 2)。与稳定同位素相比,这四个地区的水稻营养元素仅显示出微小的差异。多因素分析(MFA)用于研究同位素、元素和水稻起源之间的关系(Fig.3)。前两个因素的变异性分别为19.1%和14.0%。变量相关图(Fig.3a)显示,δ13C、δ18O和δ2H紧密聚集在第一象限,但δ15N与其他同位素分离。一般来说,δ13C、δ18O和δ2H值与气候和环境有关,δ15N与耕作方式有关。除钼外,常量营养元素和微量营养元素均远离同位素聚集。四个水稻起源分散在不同的象限中。只有N-E型水稻与稳定同位素呈正相关,并且与其他来源的水稻明显分离。N-E水稻与δ13C、δ18O和δ2H同位素高度相关,而Y-R水稻与水稻中发现的营养元素更密切相关。共有四个MFA变量类别,包括稳定同位素、常量营养元素、微量营养元素和水稻起源。这些类别的坐标(Fig.3b)表明,稳定同位素比常量营养元素和微量营养元素对起源分化的贡献更大,因为它们之间的关系更密切。观察得分图(Fig.3c)显示,MFA的前两个因素没有将来自不同来源的样本分开,四个来源之间存在相当大的重叠。
Table 2 中国四个产区大米中的稳定同位素和营养元素。
Fig. 3 (a) 所有变量的相关图;(b) 四个变量类的坐标;(c) MFA观察评分图。
3.3. BP-NN模型
BP-NN模型使用15个输入变量建立,包含稳定同位素和元素。粳稻和籼稻有各自的定性模型,因为它们可以通过外观进行区分。361份粳稻样品被分为两类,其中243份来自N-E地区,118份来自Y-R地区。
Table 3A显示了BP-NN模型的识别结果。粳稻模型分别由253(训练集)、54(验证集)和54(测试集)个水稻样本组成,经过10次重复,准确率>94%。训练集和验证集的平均准确率分别为97.1%和97.4%,测试集的准确率在94.4%到100%之间,平均为97.0%。N-E水稻样品的分类准确率为98.0%,甚至高于Y-R水稻样品(95.3%)。这表明东北粳稻最容易被正确鉴别。在中国,近50%的粳稻产自东北地区。优质东北稻以其营养成分高、支链淀粉含量高、香味浓郁、口感极佳而闻名,深受消费者青睐。该模型对东北粳稻的识别精度较高,有助于解决东北粳稻的错误标记问题,从而获得更多的利润。
Table 3A 粳稻BPNN模型的准确度(%)。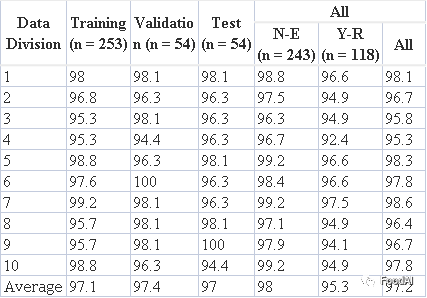
本研究籼稻主要来自Y-R、S-W和S-E地区。为了确定其来源,我们使用了4个模型,每个模型重复5次。All Regions模型(Table 3B)将籼稻划分为Y-R、S-W和S-E区域,训练集和验证集的平均准确率分别为78.1%和79.2%,每个测试集对未知样本的平均准确率为76.0%。在所有区域的模型中,S-E水稻的预测率最低,可能是因为S-E水稻样本比其他两个区域少,并且S-E水稻的鉴别特征不太明显。相比之下,籼稻模型的精度低于粳稻模型。据推测,籼稻生产区域之间的距离更近,并且比粳稻生产区域具有更相似的特征,而粳稻生产区域具有更好的区分性。
Table 3B 籼稻BPNN模型的准确度(%)。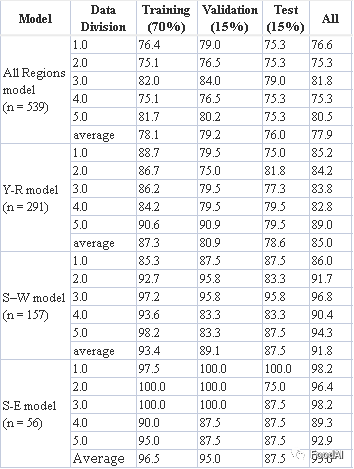
此外,分别为Y-R、S-W和S-E区域建立了另外三个籼稻模型。每个地区都有来自几个相邻省份的水稻样本。目前,中国的大米销售按行政区划划分。从物流角度来看,高价值地区的标签错误或欺诈性大米更可能来自相邻省份,因此区域可追溯性模型将特别有助于定义特定行业需求,并针对相邻生产区域的差异。三种区域模型的识别准确率均高于全区域模型。Y-R模型使用了Y-R地区四个主要生产省份(安徽、湖北、湖南和江西)的291个籼稻样本,江苏、浙江和河南的其他35个籼稻样本不参与该模型。Y-R模型的平均分类准确率在训练集为87.3%,在验证集为80.9%,在测试集为78.6%,在整个Y-R区域数据集为85.0%。S-W和S-E模型都覆盖了各自地区的所有水稻样品。S-W模型对来自四个省份(贵州、四川、云南和重庆)的籼稻进行了鉴别,测试集和整个S-W数据集的准确率分别为87.5%和91.8%。在所有的籼稻模型中,S-E籼稻模型的精确度最高,因为该模型的样本量最小。它对来自3个省份的S-E水稻样本进行分类,训练集、验证集、测试集和所有数据集的准确率分别为96.5%、95.0%、87.5%和95.0%。
4. 结论
对粳稻和籼稻的稳定同位素和元素研究表明,中国四个主要地理区域的两个水稻品种之间存在显著差异。粳稻的δ13C、δ15N、δ2H、δ18O值和元素含量均比籼稻的高。在主要生产区域中,东北地区具有独特的特征,与δ15N、δ2H和δ18O同位素密切相关,而长江中下游平原的水稻主要与营养元素(Na、K、Zn、Ca、Fe、Ni等)相关。在所有变量中,稳定同位素比营养元素对地理来源鉴别的贡献更大。BP-NN模型采用稳定同位素和元素相结合的方法,能够对不同地区的粳稻和籼稻进行高精度分类(分别为97.2%和77.9%)。尽管这项工作利用稳定同位素和元素变量建立了第一个国家水稻可追溯性数据库,但影响这些指纹的年度气候变化和环境因素仍需进一步探索。
参考文献
Li, C., Nie, J., Zhang, Y., Shao, S., Liu, Z., Rogers, K. M., Zhang, W., & Yuan, Y. (2022). Geographical origin modeling of Chinese rice using stable isotopes and trace elements. Food Control, 138, 108997.
关注公众号:FoodAI 获取更多相关资讯
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/rice-trace.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
凉茶中农药及其转化产物的分析
今天介绍一篇来自国家环境保护新型污染物环境健康影响评价重点实验室卢大胜和汪国权等人于2022年2月发表在Food Chemistry(IF=7.514)上的文章。通过研究定位了来自中国两个主要产区的两种凉茶(菊花和冬青)中的农药和农药转化产品(PTPs), 揭示了凉茶中农药的概况,并为发现潜在的环境污染和食品污染物提供了新的视角。
-
湖南大学吴海龙课题组:高效液相色谱指纹图谱结合化学计量学的白术有效成分分析及产地鉴别研究
该研究提出运用高效液相色谱-二极管阵列检测器(HPLC-DAD)结合化学计量学方法快速分析不同地区白术中12种活性成分含量并进行产地判别。首先,使用HPLC-DAD结合二阶校正算法(ATLD)对来自不同地区的白术中12种活性成分同时进行定性定量分析。利用“二阶优势”,12种化合物不仅在12.5 min内快速洗脱,而且还在色谱峰高度重叠的情况下实现了准确定性定量(平均回收率为80.8–109.9%),一系列品质因子参数均反映出所提方法的可行性。基于ATLD解析所得的12种活性成分和31种未校正成分的相对浓度值,使用偏最小二乘-判别分析法(PLS-DA)对不同地理来源的白术样本进行判别分析,三个地区的白术都有明显的聚类趋势,测试集的正确分类率可达90%。变量重要性投影(VIP)分析结果表明,紫丁香酚苷、白术内酯Ⅲ、白术内酯Ⅰ和苍术酮可作为白术产地判别的主要标志成分。一系列结果均证明了所建立模型的可靠性。该方法的建立有助于白术的临床使用和市场监管。
-
我的食物安全吗? – 基于人工智能的含有微量的麸质或坚果的小扁豆粉样品分类
今天介绍一篇由Sandra Pradana-López等人于2022年8月发表在Food Chemistry上的文章。本文提出了一种基于人工智能的实时快速检测掺杂扁豆粉的方法。将“无麸质”小扁豆粉与小麦粉或开心果粉混合,然后,拍摄纯的和受污染的小扁豆粉的数字图像,并用于训练基于转移学习的模型(即ResNet34),该模型旨在根据小麦和开心果含量对图像进行分类。本文获得的结果旨在作为概念验证,以评估数字成像与深度学习技术相结合的食物过敏原检测的真正潜力。
-
当今的机器学习策略可以减少人们对食物中纳米粒子的担忧
在《环境科学与技术》杂志在线发表的一项新研究中,德克萨斯 A&M 大学的研究人员使用机器学习来评估金属纳米粒子的显着特性,这些特性使它们更容易被植物吸收。研究人员表示,他们的算法可以表明植物在根和芽中积累了多少纳米颗粒。
-
Bioresource Technology:智能化的方法来可持续管理和利用食物废弃物
撰文:王雪洁 编辑:肖冉 介绍 今天介绍一篇由Zafar Said等人于2023年3月在线发表在Bioresource Technology(IF=11.89)上的文章。这篇文章主…
-
食品命名实体识别的BERT模型:算法开发与验证
今天介绍一篇最近由斯科普里大学计算机科学与工程学院Riste Stojanov等人发表在医学互联网研究杂志上的文章。文章研究了最近发布的基于Transformer的双向编码表示(BERT)模型,该模型在信息提取方面提供了最先进的结果,可以对食品信息提取进行微调。
-
基于人工智能的黄油品种识别作为食品掺假检测的研究范例
今天给大家介绍一篇由Gokce Iymen等人近期发表在Innovative Food Science and Emerging Technologies上的一篇文章。文章介绍了基于人工智能工具,利用简单的声音振动来识别食品中的掺假。
-
FRONT NUTR:通过化学信息学方法从蓝莓中计算筛选抗阿尔茨海默病的新神经保护成分
今天介绍一篇由中南林业科技大学张琳教授团队发表的一篇研究性论文,由肖冉等人于2022年12月发表在国际营养学TOP期刊Frontiers in Nutrition上(JCR:Q1 IF:6.59)。本文尝试设计一种基于化学信息学方法这种有效的智能筛选模式,从蓝莓中寻找抗阿尔茨海默病(AD)的新型有效成分,并通过实验验证了预期成分的生物活性。该方法集成了先进的人工智能和化学信息学方法,实现了对所有成分的逐步分析和过滤。最后,获得了预期的新化合物氯化锦葵色素-3-O-半乳糖苷(Ma-3-gal-Cl)。这篇文章采用的创新性方法为。这项工作采用的筛选策略能够为研究者从天然产物和食物中筛选活性成分提供新的参考。
-
中国农业大学周欣团队基于宏基因组学和机器学习的蜂蜜产品溯源
今天介绍一篇来自中国农业大学昆虫学系周欣教授课题组于2022年3月发表在Food Chemistry上的文章。该文为了查询蜂蜜的地理来源,收集蜂蜜样本产生的宏基因组数据,应用机器学习方法来推断蜂蜜的地理来源。