今天介绍一篇由Andrea Morales-Garzon等人于2021年2月在IEEE Access上发表的文章。本文提出了一种新的无监督食谱调整方法,用于根据用户偏好调整食谱成分。为了学习食物表征和关系,创建并应用一个特定领域的单词嵌入模型。将一个单词嵌入模型与一个基于模糊的文档距离相结合,以找到适应任务中最相似的成分。作者根据营养偏好、适应类似的成分和素食以及纯素饮食限制,进行了三种不同的食谱调整。结果证实了使用特定领域语义模型来处理食谱适应任务的潜力。
摘要
今天介绍一篇由Andrea Morales-Garzon等人于2021年2月在IEEE Access上发表的文章。本文提出了一种新的无监督食谱调整方法,用于根据用户偏好调整食谱成分。为了学习食物表征和关系,创建并应用一个特定领域的单词嵌入模型。将一个单词嵌入模型与一个基于模糊的文档距离相结合,以找到适应任务中最相似的成分。作者根据营养偏好、适应类似的成分和素食以及纯素饮食限制,进行了三种不同的食谱调整。结果证实了使用特定领域语义模型来处理食谱适应任务的潜力。
1. 介绍
食品计算有利于一些复杂任务的自动化,如饮食推荐并且更准确地分析数据。同样,它也导致了食品系统的发展,允许访问具有更好用户体验的食谱集,他们的数据是结构化的,用户可以查找他们感兴趣的食谱、标签和数据。考虑到在处理专业词汇时,领域特定模型获得了更好的结果,作者决定训练一个领域特定的单词嵌入模型,能够表示专门的食品信息。学习食物表征,通过特定领域的单词嵌入模型捕捉其含义。
这项工作的主要贡献如下:(1) 呈现食品的特殊领域的单词嵌入模型(2) 将食品和营养数据库与食谱中使用的成分匹配的自动化方法(3) 基于用户偏好和限制的无监督的食谱适应算法。
2. 方法论
A. 概述
本文的方法从成分层面解决了配方调整问题,也就是说,通过将配料替换为合适的替代品来调整配方。图1详细说明了建议调整任务的工作流程。该图还显示了一个特定类型的食谱调整示例,在本例中,是对素食限制的调整。
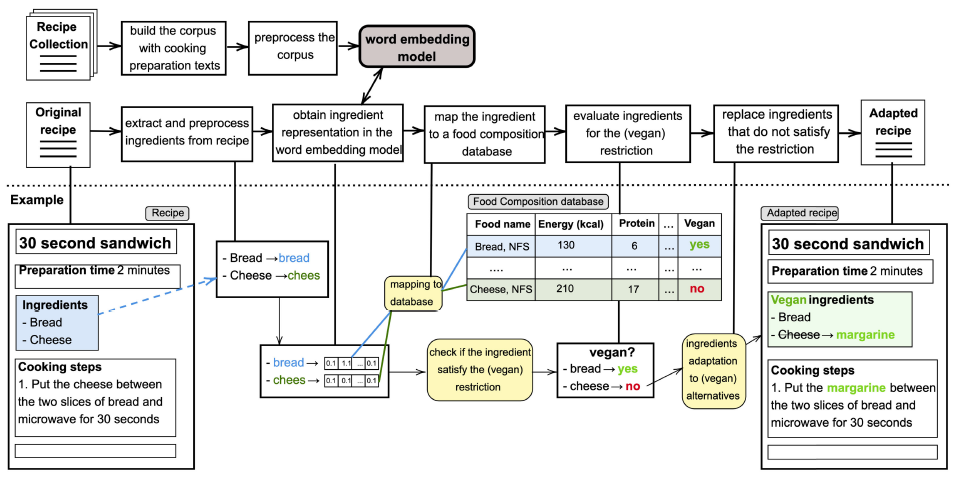

图1 本文对整个过程进行了概述
首先,作者建议使用特定领域的单词嵌入模型来表示食品。其次,为了根据用户的喜好调整配方,考虑了成分的营养特征。
B. 单词嵌入
本文使用单词嵌入模型来获得食物术语的数字表示。介绍了几种常见的单词嵌入模型。最广为人知的单词嵌入模型是word2vec,这是一种神经网络,将单词投射到潜在空间,然后根据上下文进行重建。另一种常用的单词嵌入模型是fasttext。它类似于word2vec,但它学习字符n-gram的表示,而不是单个单词的表示。GloVe中使用了一种不同的方法,它不是基于本地单词上下文,而是基于单词的全局共现。
为任务选择最佳的单词嵌入模型通常并不简单。因此,作者进行了一个类似的实验来比较这三个模型在计算食物相似性方面的输出和性能。研究得出了相同的结论:他们在文本相似性任务中表现相似。因此,作者使用word2vec,因为它很简单。
C. 成分映射
从单词嵌入模型得到的数字表示可以用于检测数据中潜在的同义词。食品描述几乎不由一个词组成,在这种情况下,嵌入向量之间的简单距离是不够的。因此,度量必须考虑整体的文本描述。为了处理语言歧义,作者考虑了距离度量的模糊实现。此度量为映射提供了更大的灵活性和健壮性。特别是,使用模糊距离度量来研究短文档之间的语义相似性。
D. 食谱调整
本文考虑了三种调整配方的主要方法:
1)基于相似性的适应:根据特定领域单词嵌入模型获得的相似关系提供了替代成分。
2)基于偏好的适应:考虑到用户的偏好,提供了配方中所给成分的替代成分。
3)基于食物限制的适应:在这种情况下,指的是那些有食物限制的用户。
E. 验证
作者开发了一项在线调查,用户可以在其中验证并评估一系列经过调整的食谱的充分性。
3. 数据
本文总共使用了三个食品数据集。特别地,使用了两种不同的配方语料库分别训练单词嵌入模型和验证配方适应任务。使用不同来源的配方使作者能够评估模型的泛化能力。第三个数据集对应于一个食品数据库,用它来获取适应过程中所涉及成分的营养价值。
4. 实验
A. 单词嵌入模型
本文使用archive.org语料库来训练单词嵌入模型。因此,确保了项目的适当领域特定表示。如前所述,作者使用“说明”字段构建了一个包含每个食谱烹饪说明的语料库。
B. 单词嵌入比较
作者对不同单词嵌入模型的行为进行了比较,以确定哪种模型最适合的问题。为此,作者决定为训练步骤设置相同的配方语料库和超参数(即30个时代,窗口大小固定为5,向量大小为300),训练不同的单词嵌入。具体来说,作者使用单词嵌入模型word2vec(CBOW实现)、fasttext和GloVe进行了实验。
研究了每一种方法得到的映射,以测试结果映射之间是否存在实质性差异。为此,作者从Food.com配方数据集中提取了1000种最常用的成分,并获得了它们与coFID数据库的映射。图6显示了应用不同距离阈值(x轴)后两个模型的重合映射数(y轴)的成对比较。每一行对应于a与b的重合映射数,仅考虑a和b获得的非常相同的结果(蓝色),a与b的前两个映射中的任何一个的重合-反之亦然-(黑色),以及a与b的前三个映射中的任何一个的重合-反之亦然-(橙色)。
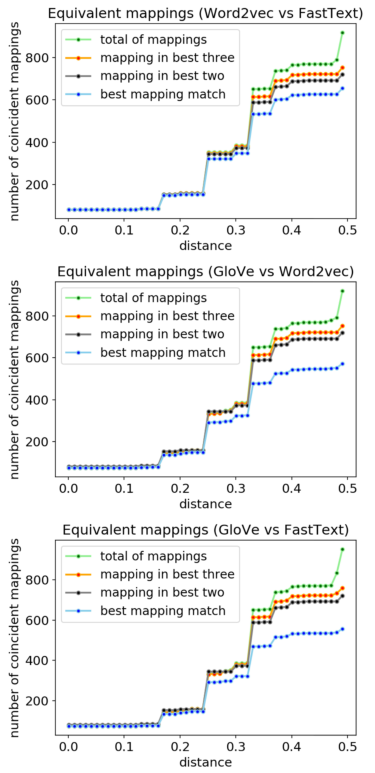
图6 用于绘制食物项目的单词嵌入算法比较的绘图可视化
结果表明,这三种模型具有非常相似的性能,因为通过模型匹配获得的映射占很大比例。具体来说,最佳匹配几乎总是包含在其他三个最佳匹配中。考虑到模型性能之间的高度相似性,作者决定继续使用word2vec。
C. 成分映射
根据Food.com数据集提供的食谱,提取了它们的成分,并在coFID食品成分数据库中进行了识别。为此,首先获得了成分的嵌入表示。因此,对它们进行了预处理,使用与单词嵌入模型中的训练语料库相同的步骤清理文本。
D. 食谱调整
作者区分了三种不同的配方调整。第一种可能是修改配方中的成分,使其他食物也适合于原来的食物。其次,对于基于偏好的自适应,加入了映射函数的顺序关系。因此,在为每种成分获得最合适的替代品时,会优先考虑给定的偏好。最后,为了使食谱适应食物限制,着重于使食谱适应素食者和素食者的饮食限制。为此,作者在食品成分数据库中添加了两个新列,以登记食品是纯素食品还是素食食品。
5. 结果
本文从Food.com数据集中随机选择了一组食谱。这个数据集包含大量的甜点、酱汁和土豆类菜肴,其中许多都使用非常相似的成分。然后,开发了一个网站,允许用户评估配方。为此,作者展示了配方的原始版本和改编版本,以便用户可以看到使用的方法获得的更改和建议。
作者通过对40名具有烹饪常识的公民进行调查,测试了经过调整的食谱。每个用户验证了随机选择的每种适应类型的五种配方。总共从40个用户那里获得了590条评论。其中,8篇评论表明对配方缺乏了解。因此,将其排除在分析之外。图7显示了每组配方中获得的平均分数。无论哪种适应,适应的配方都优于2.5满意度,置信度为95%。
图7 基于适应类型的调查结果的绘图可视化。该图显示了食谱评估的置信区间,置信水平为95%。
6. 结论和今后的工作
本文已经证明,单词嵌入模型可以获得良好的食物表示。它们可以帮助理解成分是如何组合和替代的。为了调整食谱,作者需要对它们进行分类,并找到最相似的食物成分。因此,当与适当的度量结合时,这些表示是有用的。这项工作还考虑了基于模糊的文件距离,以确定营养数据库中的食物描述。
通过40名用户参与的在线网络调查验证了自适应方法。共有80种配方,即每种20种。结果表明,这种方法是充分的,食品的语义内容是有意义的,也可以直接应用于解决实际问题。
对于未来的工作,作者计划在适应过程中考虑不同的烹饪类型来扩展这项工作。该方法将根据风格在每个食谱中找到最合适的成分。此外,还计划为系统提供用户对配方的交互,并包括专家知识来指导成分替代。
还将使用更高级的语言模型(如BERT)应用此方法,以获取食谱成分在适应任务中的作用,并微调通用嵌入,以利用现有的预训练模型。作者计划深入研究单词嵌入与映射函数的交互作用,以获得更好的结果。
参考文献
- [1] Morales-Garzon A , Gomez-Romero J , Martin-Bautista M J . A Word Embedding-Based Method for Unsupervised Adaptation of Cooking Recipes[J]. IEEE Access, 2021, 9:27389-27404.

长按关注我们
微信号|FoodAI
合作/投稿|biomed@csu.edu.cn
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/embedding-food-recipes.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
基于非靶向 HPLC-MS 的代谢组学方法揭示可可粉掺假
今天给大家介绍一篇由西班牙阿尔卡拉大学Maider Greño等人在Food Chemistry(IF=9.231)上在线发表的一篇的研究性文章。该文章提出了一种非靶向代谢组学方法,该方法基于反相液相色谱与高分辨率质谱联用来检测可可粉与一些最常用的可可掺假剂。
-
中国农业大学周欣团队基于宏基因组学和机器学习的蜂蜜产品溯源
今天介绍一篇来自中国农业大学昆虫学系周欣教授课题组于2022年3月发表在Food Chemistry上的文章。该文为了查询蜂蜜的地理来源,收集蜂蜜样本产生的宏基因组数据,应用机器学习方法来推断蜂蜜的地理来源。
-
Bioresource Technology:智能化的方法来可持续管理和利用食物废弃物
撰文:王雪洁 编辑:肖冉 介绍 今天介绍一篇由Zafar Said等人于2023年3月在线发表在Bioresource Technology(IF=11.89)上的文章。这篇文章主…
-
静态顶空-气相色谱-离子迁移谱(SHS-GC-IMS)结合机器学习技术对长相思葡萄酒的质量等级预测
该研究将静态顶空-气相色谱-离子迁移谱(SHS-GC-IMS)技术首次应用于葡萄酒香气分析,通过预测模型将香气化学与葡萄酒感官质量分级联系起来。对6种机器学习模型进行了比较,结果表明人工神经网络(ANN)的预测精度最高,达到95.4%。
-
基于图像识别的饮食评估系统
今天给大家介绍一篇由Kalliopi V. Dalakleidi等人,于2021年7月8日发表在Advances in Nutrition(IF=11.567)的一篇综述性文章。该综述描述了用于饮食评估的计算机视觉方法的最新进展,并介绍了基于图像的食物识别系统 (IBFRS) 在专业饮食实践中的最新应用。
-
使用可解释人工智能(XAI)技术解开送餐服务评论的深度学习模型
今天介绍一篇由悉尼科技大学土木与环境工程学院工程与信息技术学院高级建模和地理空间信息系统中心(CAMGIS)的Anirban Adak等人今年七月发表于Foods(IF: 5.561)的一篇文章。该研究通过比较食品配送服务(FDS)领域中的简单和混合深度学习(DL)技术(LSTM、Bi-LSTM、Bi-GRU-LSTM CNN)进行了情绪分析,并使用SHapley Additive exPlanations(SHAP)和Local Interpretable Model-Agnostic Explanations(LIME)解释了预测。DL模型在从ProductReview网站提取的客户评论数据集上进行了训练和测试。结果表明,LSTM、Bi-LSTM和Bi-GRU-LSTM-CNN模型的准确率分别为96.07%、95.85%和96.33%。LSTM模型相比其他两个DL模型实现了更低的假阴性率。可解释人工智能(XAI)技术,如SHAP和LIME,揭示了用于验证模型的单词对积极和消极情绪的特征贡献。
-
系统综述人工神经网络在食品加工过程中的建模应用
今天给大家介绍一篇由G. V. S. Bhagya Raj等人合作的,于近期发表在Critical Reviews in Food Science and Nutrition的一篇综述,文章中作者系统综述了ANN在食品加工等领域的应用进展并进行了展望。
-
人体对食物的餐后反应与精准营养的潜力
今天介绍一篇由Sarah E. Berry等人前段时间发布于nature medicine的一篇文章。文中对英国(n=1002)和美国(n=100)的年轻健康成年人进行餐后代谢反应评估,并开发机器学习模型来预测人体内的甘油三酸酯(r=0.47)和血糖(r=0.77)对食物摄入的反应,这项技术有助于制定个性化的饮食策略。
-
中国科学院蒋长龙团队:基于集成纸基传感器的便携式智能手机的无酶和快速视觉定量检测农药残留
今天介绍一篇由Qianru Zhang、蒋长龙等于2022年6月发表在Journal of Hazardous Materials上的一篇论文。该研究构建了一个简单、快速、可视化的无酶辅助的草甘膦(Gly)荧光定量检测平台。并且在设计的智能手机平台的辅助下制备了荧光试纸条,显示出作为便携式光学分析终端的潜力,用于定量跟踪真实样品中的Gly。该传感平台为Gly的定量检测提供了可靠的方法,可推广到分析科学领域的其他分析物或污染物筛选。