该文章综述了集成深度学习最近的关键发展,以及如何将其应用到生物信息学领域中。同时,作者还详细介绍了集成深度学习从基本序列分析到系统生物学的研究、发展和挑战。
本期给大家介绍悉尼大学Jean Yang教授课题组发表在Nature machine intelligence的文章“Ensemble deep learning in bioinformatics”。该文章综述了集成深度学习最近的关键发展,以及如何将其应用到生物信息学领域中。同时,作者还详细介绍了集成深度学习从基本序列分析到系统生物学的研究、发展和挑战。


1. 主要思想
集成和深度学习在生物信息学领域一直被视为两个独立的方法。然而,近年来这两种技术发展十分迅速,许多研究者发现,集成深度学习模型在处理小样本、高维、不平衡分布的数据的时候具有优越的性能,因此越来越多的人开始将目光转向集成深度学习领域。
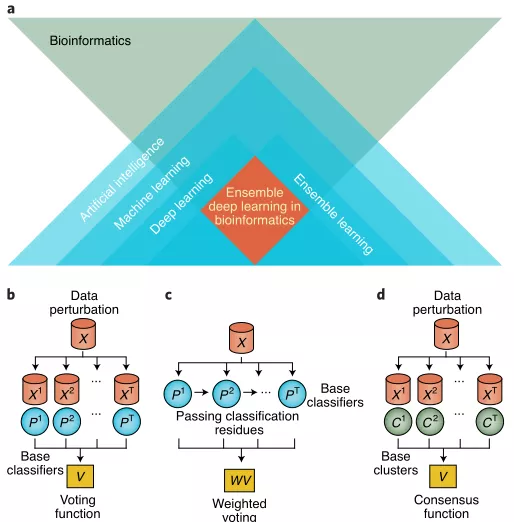
在生物信息学领域中,集成学习和深度学习方法都得到了广泛的研究和评述,但集成深度学习在生物医学领域中的应用目前还未有文献记载。这篇文章回顾了集成和深度学习的基础,并对集成深度学习的最新发展进行了总结和分类。此外,作者还对生物信息学中集成深度学习的应用进行了调查,之后讨论了这个方面的挑战和机遇,以促进未来跨多个学科的研究和开发。图1展示了这篇文章的重点和一些经典的集成学习方法。
2. 相关研究
2.1 集成和深度学习的基础
集成学习是组合多个“基础”模型来执行任务,如监督和非监督学习。经典的监督学习集成方法分为三类:基于袋装的方法、基于提升的方法和基于堆栈的方法。传统的无监督集成学习也依赖于基本模型的集成。集成方法的原则是“多个总比一个好”。
深度学习的最基本架构是密集连接神经网络(DNN),由一系列神经元组成,每一层都与上一层的所有神经元相连接。像CNN、RNN、ResNet等模型都是在基本的架构上展开的。
2.2 集成深度学习
深度学习经常会有很高的方差,且在训练过程中可能会陷入局部损失最小值,而集成多个深度学习模型的方法比单一模型具有更好的泛华能力。文章对监督和非监督集成深度学习策略进行了分类和总结。
监督集成深度学习可以大致分为三类:跨多个模型集成、单个模型集成和模型分枝集成。
跨多个模型集成通常是直接将多个独立的模型聚合在一起,来促进基础网络的多样性。训练数据互补学习可以实现更好的集成泛化,或者通过多项选择学习可以对特定的数据子集专门化。在“隐式集成”中,单个神经网络可以达到类似于集成多个网络的效果。训练单个神经网络时,用一种技术去随机激活神经元层,使得具有不同架构的网络隐式的集成。如在ResNets中随机停用ResBlocks构建块。与多个模型集成相比,单个模型集成降低了训练成本,但同时可能会降低模型多样性。因此模型分支集成是共享较低层,附加分枝层,通过共享信息,避免了从头开始搜索参数,且收敛速度更快了。
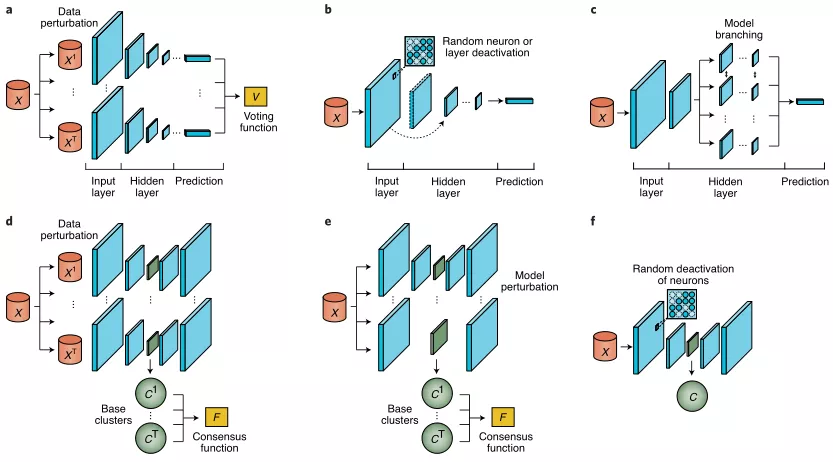
大多数无监督集成深度学习方法采用自动编码器。与有监督方法类似,无监督集成方法可以分为通过数据和模型扰动生成和组合多个模型的方法,以及在单个模型内实现隐式集成的方法。监督和非监督学习中的典型集成深度学习框架依次如图2所示:
3. 集成深度学习在生物医学领域的应用
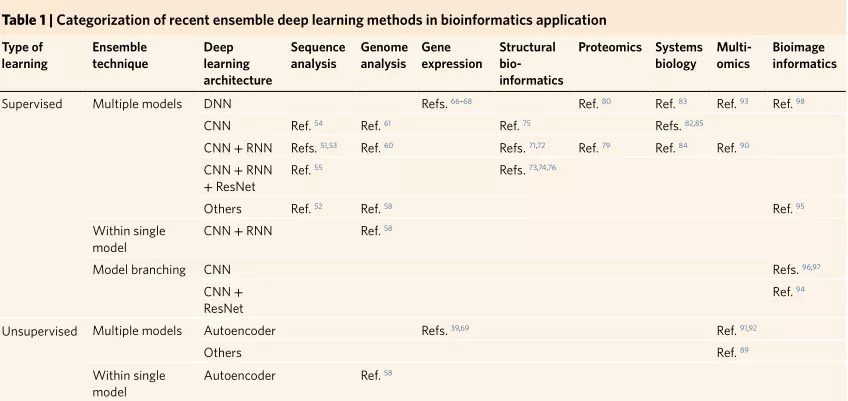
文章对生物信息学应用的不同领域的代表性工作进行了分类,并确定了它们的优点,例如提高了模型的准确性、重复性、可解释性和模型推论。文章总结结果如表1所示:
4. 挑战和机遇
集成深度学习在小样本、高维与阶层失衡、数据噪声和异构性、模型可解释性、网络架构选择和计算费用等方面表现要明显优于深度学习。在生物医学领域通常存在样本量少,数据维度过高等一系列问题,因此使用深度集成学习解决生物生物医学领域问题是一个不错的发展方向。集成深度学习的发展以新颖的体系结构和集成策略大大丰富了深度学习领域,提高了模型的准确性、可靠性和效率,对小样本、高维和数据噪声的鲁棒性在生物信息学应用的不同领域取得了显著而广泛的突破。如今,能够解释生物系统的模型的开发和应用仍处于初级阶段,集成深度学习还有很大的研究空间。
参考资料
Cao, Y., Geddes, T.A., Yang, J.Y.H. et al. Ensemble deep learning in bioinformatics. Nat Mach Intell 2, 500–508 (2020).
https://doi.org/10.1038/s42256-020-0217-y

原创文章,作者:DrugAI,如若转载,请注明出处:https://www.drugfoodai.com/edlbio.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
Science | 化学合成文献数字化自动执行通用系统
编·译作者 | 王建民 今天给大家介绍格拉斯哥大学化学系S. Hessam M. Mehr等人在Science上发表的文章“A universal system for digit…
-
Nat. Mach. Intell. | 可解释性人工智能(xAI)遇上药物发现
编·译作者 | 王建民 过去的几年里人工智能(AI)的各种概念已被成功地应用到计算辅助药物发现中。这种进步主要归功于深度学习算法,即具有多个处理层的人工神经网络,能够对复杂的非线性…
-
药物开发中基于深度学习的不平衡数据分类
利用机器学习开发药物设计相关的预测模型,经常会遇到数据不平衡的现象。数据的不平衡会导致模型过偏而失去较好的预测性能。为了解决这个问题,很多学者做出了努力。下面介绍Selçuk Korkmaz等人的一项新工作,尝试利用不同的策略处理PubChem数据集,为不平衡数据提供方法参考。
-
ADMETlab: 一个全面优秀的药物ADMET性质预测平台
药物ADMET虚拟预测评价是药物开发中的一个重要环节,近些年除了一些人工智能的模型之外,还发展了一系列的工具和软件。今天介绍中南大学曹东升课题组董界等人开发的ADMET预测平台。该平台提供目前最大最全面药物ADMET数据库和多达31种ADMET终点性质的系统评估,在国内外相关领域迅速获得广泛应用,成果短期被引用上百次。平台地址:http://admet.scbdd.com
-
ChemDes: 一个整合的基于网络的分子描述符与指纹计算平台
分子描述符的计算是基于分子结构进行建模预测的基础,多年来发展了一系列的工具和软件。今天介绍中南大学曹东升课题组董界等人开发的描述符计算平台。该平台提供目前最大最全面的描述符在线计算资源,赢得了世界各地8万多次的使用或引用。平台地址:http://www.scbdd.com/chemdes
-
ADMETlab 2.0:全面的药代动力学和毒性在线预测平台
今天给大家介绍的是中南大学曹东升教授和浙江大学侯廷军教授近日联合发表在Nucleic Acids Research上的一篇文章“ADMETlab 2.0: an integrated online platform for accurate and comprehensive predictions of ADMET properties”。
-
Nucleic. Acids. Res. | 又双叒叕升级了!ADMETlab 3.0——全面升级的药物ADMET预测平台
ADMETlab作为一个领先的ADMET预测平台,它也广受认可。截至目前,ADMETlab 2.0的文章已被引用1088次,网站访问量超过170万次。为了满足广大科研工作者更高的需求,此次将ADMETlab升级到了3.0版本。这是一个全面更新的在线ADMET预测平台,旨在为药物发现过程中的ADMET相关参数提供更广泛、更高效、更精准的评估。网站链接:https://admetlab3.scbdd.com。
-
Brief. Bioinform. | FormulationAI:人工智能驱动的新一代药物制剂计算平台
今天,我想向大家介绍一篇近期发表在国际生物信息学期刊《Briefings in Bioinformatics》上的研究论文:“FormulationAI: a novel web-based platform for drug formulation design driven by artificial intelligence”。论文的通讯作者是澳门大学的欧阳德方老师,第一作者为中南大学董界老师。该论文发布了新一代人工智能药物制剂预测平台,称为FormulationAI,旨在通过人工智能技术改变传统药物制剂设计的局限,系统推动药物制剂设计开发朝着智能化、高效率和经济性的方向发展。平台访问网址:https://formulationai.computpharm.org
-
一项震动制药行业的研究:大型制药公司AI的生产力
6月15日,一篇标题为“ The upside of being a digital pharma player” 的文章在一家受到同行好评的行业期刊《Drug Discovery Today》上被接受并悄悄上线了。一项全面的研究,对制药公司在研发方面的AI努力进行了正面对比。