目前为止,由于医学中人工智能的临床试验数量有限,因此有关方案和报告的首份指南适时出现。更好的方案设计以及一致且完整的数据表示,将极大地促进这些试验的解释和验证,并有助于该领域的发展。
作者/编辑 | 王建民


过去的十年中,人们为将深度学习算法应用于医疗保健而感到兴奋。这种人工智能(AI)的子类型具有提高解释大型数据集的准确性和速度的能力。但是,为了在患者护理中接受并实施深度学习,迫切需要随机临床试验的证据。

随机临床试验在1980年代初期变得很普遍,以提供医学实践的依据,但是直到近二十年后,1996年才制定了《综合报告标准》。相反,人工智能在医学中的使用,特别是深度神经网络的使用,仍处于早期阶段-仅在过去两年中才开始使用AI进行临床试验。本期《自然医学》新增两篇配套文章,专门介绍临床试验指南的方案(SPIRIT-AI Extension)和出版(CONSORT-AI extension)。
回顾性分析只是第一步
当前有数百篇回顾性报告属于AI的“临床试验”范畴,但它们根本不是真正的试验。尽管这是奠定基础的必要条件,但这些是对数据集进行计算评估,以确定与少数医师相比,深层神经网络执行临床任务的能力如何。此类AI报告不会模拟临床实践,而是从清洁的,相对原始的带注释的数据集中进行工作。相比之下,医学的现实世界是混乱的,缺少大量数据,许多数据是非结构化的,其重点是照顾患者而不是开发分析底物。不能过分强调临床环境与计算环境的鲜明对比,因此需要AI的临床试验。
到目前为止,有过两次系统评价和所有临床研究人工智能的荟萃分析,已经暴露出严重缺陷。在一项对82项研究的评论中,发现这些试验的关键方面报告很差,导致缺少数据、关键术语和这些术语的定义。作者还发现,模型性能和验证描述具有很大的可变性,并且缺乏外部验证。没有研究进行样本量计算来确保其具有足够的动力。最令人烦恼的是,很少将深度学习模型与算法和医疗保健专业人员对相同数据集进行评估的组合方法进行比较。另一项对81项研究的评论确认了先前的评论并发现了进一步的缺陷。这篇评论的作者发现了一个严重的问题,即透明度、数据集和评估可重复性的代码的可用性有限,用于与算法性能进行比较的临床医生人数很少以及双曲线结论。临床医生与机器的冲突是临床实践的对立面,这至少在任何重要的,严重的诊断中都会使人始终陷入困境。永远不能仅依靠神经网络来做出关于患者的关键的,可能的生死决定。
人工智能临床试验案例
代表患者护理的前瞻性试验至关重要。例如,医学界对AI进行的首批重大研究之一:对皮肤神经的深层神经网络诊断与21位经过董事会认证的皮肤科医生的比较。当皮肤科医生评估皮肤病变时,他们不是孤立地分析照片,而是在患者的病史和体格检查的背景下分析病变,这与深度神经网络的应用形成了鲜明的对比。此外,通过使用视网膜成像算法,多项回顾性研究突出了糖尿病视网膜病变诊断的近乎完美的准确性。但是,当使用这些算法进行首次前瞻性试验时,准确性虽然可以接受,并且可以自动诊断向前迈进了一步,但其准确性却不及后者。因此,必须将医疗保健中AI的回顾性研究视为假设的产生,通常是最佳情况,并且不能作为确定的证据。但是,不幸的是,目前,FDA对算法的大多数监管批准都依赖于此类初步证据。此外,私人公司用于开发其算法的回顾性数据集很少公开,因此对于打算将其所基于的算法用于患者护理的临床社区而言并不透明。
虽然这不是AI算法的目的,但临床算法也可能无意中造成损害。当一种算法嵌入了偏差或算法所开发的种群不能正确代表其所应用的偏差时,可能会导致严重的诊断或预测误差。一旦在临床护理中实施,此类软件便具有出色的可扩展性,从而可以无意间使患者受到伤害。来自临床试验的可靠证据对于识别和理解算法可能导致此类伤害的任何潜在因素至关重要。
新时代需要新准则
AI的临床实用性的最终证据将来自随机试验,理想情况下,将通过深度学习算法评估诊断的准确性,并与来自临床医生的诊断准确性进行比较,并由临床医师结合算法进行评估。目前,只有大约十二个此类试验(Table 1)和七个随机试验(Table 2)的公共信息。对于后者,有6例用于内镜息肉诊断,到目前为止,除1例以外,其他均在中国进行(Table 2)。前瞻性和随机试验的数量有限,这表明了AI替代医学时代的萌芽。
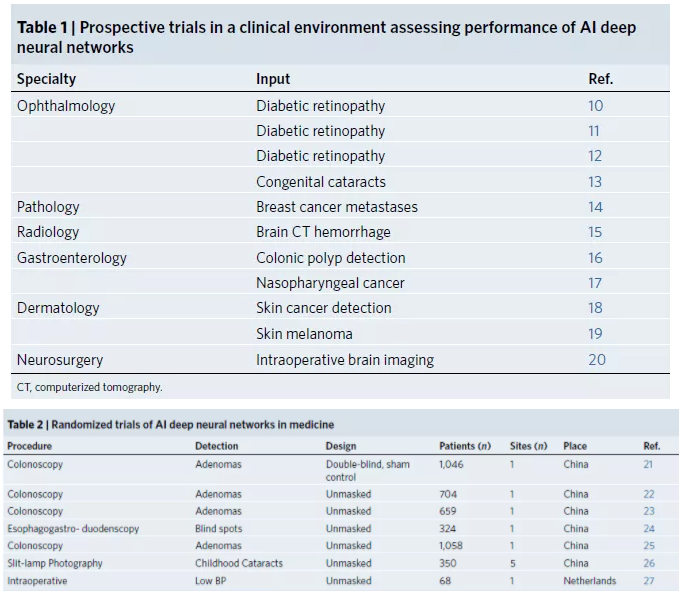
为了不浪费这个潜在的临床实践转折点,开展的医学人工智能临床试验必须以透明和不造成伤害的方式进行,这也是新指南的关键所在。值得一提的是,这些指南的产生是由一个庞大的国际跨学科团队分多个阶段进行的艰苦工作。起草之初,先是由临床试验开展和方法学方面经验丰富的学术教师组成的指导小组对300多项注册试验进行审查,然后由169名德高望重的跨学科专家进行两阶段的德尔菲研究审查和候选内容投票,最终于2020年1月在组织者所在机构(伯明翰大学)召开为期两天的共识会议。会议的产物是15个基本项目,以两个独立的检查表的形式,用于临床试验方案和报告。这些项目旨在覆盖迄今为止人工智能医学研究的关键不足。它们旨在提高试验的可复制性和独立评估的便利性。
深度学习模型由输入(数据,例如图像)和输出(解释或预测,例如胸部X光片是否表明有肺炎)组成。人工智能的临床试验中,对于输入,必须知道患者的纳入和排除数据,它们对当前临床问题的代表性如何,以及它们的数据质量和来源。对于产出,它们是如何被指定的,对决策的贡献如何,这只是几个重要的特征。指南规定了很多关于算法本身需要提供的信息,比如是哪个版本,测试和内部验证过程中发生的变化,以及模型的拟合度。需要避免医疗数据集的过度拟合–将狭隘的分析外推到更广泛、不受限制的临床环境世界。指南要求详细说明已经产生的任何错误的可检测性、可预测性和可解释性,这将有助于阐明AI应用的相对安全性。此外,这些试验的读者必须充分理解人类与人工智能的界线,作者举了一个结肠镜临床试验的例子,阐明了需要了解如何准备视频片段供胃肠病专家审查的细节。同样,监督学习依赖于基础真理,这是一个强大的术语,它传达了一些绝对准确的东西,比真理更好,但算法建立在基础真理上的基础真理可能不是实际的基础真理,建议需要详细说明这些细节这些只是两个指南组确定的一些项目,这些项目对于构建到协议和出版物很重要。
建立这些标准和透明度无疑将有助于推动这一领域的发展。但必须承认,在开展临床试验的最佳实践方面,还有更多的东西需要学习,新标准很可能需要在未来几年内进行修订。目前的标准主要是以影像为中心,还没有以有意义的方式详细说明对语音和文本数据集的建议。到目前为止,几乎所有的临床应用都使用了监督学习,这为如何解决无监督、自监督的形式留下了未知数。此外,在临床试验中的努力,除了极少数例外,都包含了只与医疗专业人员有关的人工智能,并没有承认人工智能为患者自我诊断提供自主的力量。目前已经有深度学习算法被消费者大规模使用,如智能手表静息心率应用于房颤的诊断。目前还没有任何前瞻性的实施后试验来提供另一种形式的真实世界环境下的验证。除了评估实用性外,此类研究还将记录其他挑战,从软件故障到恶意对抗性攻击。
深度神经网络的一个特殊优势是其自动学习能力,学习的数据越多,性能越好。然而目前的指南还没有解决这个问题,就像监管机构一直在努力解决这个问题一样。我们显然是想利用这种能力为医疗服务,但一旦算法进一步 “学习”,其性能是否会与发布的临床试验证据出现偏差,这存在一定的不确定性。相反,目前,当一个算法发布后,它是被冻结的,这就抑制了一个潜在的最强大的部分。
一旦在实际环境中应用,如何应对医疗人工智能的使用带来的问题,将期待CONSORT-AI和SPIRIT-AI团队未来提供的更新。目前,可以对他们在提高AI医疗研究门槛方面所做的一切努力表示深深的感谢。

参考资料
Topol, E.J. Welcoming new guidelines for AI clinical research. Nat Med 26, 1318–1320 (2020).
https://doi.org/10.1038/s41591-020-1042-x

原创文章,作者:DrugAI,如若转载,请注明出处:https://www.drugfoodai.com/ai-med-clinic.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
基于质谱-机器学习技术的番茄分类:一个食品安全增强平台
今天介绍一篇由Arthur Noin de Oliveira等人于2022年8月发表在Food Chemistry(IF=9.231)上的文章。该研究旨在开发一个使用机器学习算法的平台,分析质谱数据,对番茄进行有机和非有机的分类。决策树算法被定制用于数据分析,该模型在确定每种水果属于哪个组时达到了92%的准确度、94%的灵敏度和90%的精确度。
-
凉茶中农药及其转化产物的分析
今天介绍一篇来自国家环境保护新型污染物环境健康影响评价重点实验室卢大胜和汪国权等人于2022年2月发表在Food Chemistry(IF=7.514)上的文章。通过研究定位了来自中国两个主要产区的两种凉茶(菊花和冬青)中的农药和农药转化产品(PTPs), 揭示了凉茶中农药的概况,并为发现潜在的环境污染和食品污染物提供了新的视角。
-
PNAS | 基因调控之深度学习揭示免疫细胞分化的调节机制
1.背景 基因调控是现代分子生物学研究的中心课题之一,目前虽然探索出一些转录因子能够调控哪些特异性序列,但是对于控制免疫细胞分化的调控机理我们尚未清楚。对于免疫系统来说,每种细胞类…
-
Nat. Med. | AI和影像学的癌症筛查,准备迎接重要时刻
今天为大家介绍的是来自Jörg Kleeff的一篇短文。近年来,人工智能(AI)已成为我们生活中无处不在的元素。无论是在互联网上使用搜索引擎,发表或阅读社交媒体内容,还是使用交通工具,我们都在有意或无意地与AI技术互动。在临床医学中,AI的应用进展远比其他领域慢,诊断和治疗建议几乎完全基于人类的判断。直到最近,AI技术才开始被评估其在多种临床场景中的适用性和潜在益处,其中视频和影像应用处于领先地位。
-
Bioresource Technology:智能化的方法来可持续管理和利用食物废弃物
撰文:王雪洁 编辑:肖冉 介绍 今天介绍一篇由Zafar Said等人于2023年3月在线发表在Bioresource Technology(IF=11.89)上的文章。这篇文章主…
-
FRONT NUTR:通过化学信息学方法从蓝莓中计算筛选抗阿尔茨海默病的新神经保护成分
今天介绍一篇由中南林业科技大学张琳教授团队发表的一篇研究性论文,由肖冉等人于2022年12月发表在国际营养学TOP期刊Frontiers in Nutrition上(JCR:Q1 IF:6.59)。本文尝试设计一种基于化学信息学方法这种有效的智能筛选模式,从蓝莓中寻找抗阿尔茨海默病(AD)的新型有效成分,并通过实验验证了预期成分的生物活性。该方法集成了先进的人工智能和化学信息学方法,实现了对所有成分的逐步分析和过滤。最后,获得了预期的新化合物氯化锦葵色素-3-O-半乳糖苷(Ma-3-gal-Cl)。这篇文章采用的创新性方法为。这项工作采用的筛选策略能够为研究者从天然产物和食物中筛选活性成分提供新的参考。