今天给大家介绍一篇由Kevin Lim等人近期发表在Nature Communications上的一篇研究型文章。文章提出了一种机器学习方法来发现脂肪酸的特定组成,以区分十种不同的植物油类型及其内部的变化。作者还描述了一种有监督的端到端学习方法,该方法可以推广到任何给定混合物的油组成。
摘要
今天给大家介绍一篇由Kevin Lim等人近期发表在Nature Communications上的一篇研究型文章。文章提出了一种机器学习方法来发现脂肪酸的特定组成,以区分十种不同的植物油类型及其内部的变化。作者还描述了一种有监督的端到端学习方法,该方法可以推广到任何给定混合物的油组成。
1. 介绍
现在,尽管人们了解了特定植物油类的脂肪酸谱,但在已知脂肪酸谱的情况下,还不可能准确推断和鉴定植物油的类别。而一旦两种或两种以上的植物油混合在一起,其脂肪酸组成也会发生变化。作者介绍了几种利用脂肪酸图谱来检测掺假油的化学计量学方法,这些方法通常处理的是2-3种油的简单混合物。但由于缺乏端到端的解决方法,这些模型很少在实际环境中实现。
作者研究了一种机器学习方法,该方法能够揭示油类之间具有的不同的脂肪酸谱组成。作者使用无监督模型来进一步识别较大油类中的子簇,并缩小子簇之间的特定脂肪酸差异。利用发现的特点,对油混合物进行计算机模拟,可以为有监督的端到端深度学习模型提供了大量的训练示例,以破译油的定量组成状态。为了提高模型的通用性,作者描述了一种在线机器学习方法,该方法基于未来油脂的脂肪酸谱来更新模型。
2. 结果
2.1 十种食用油的脂肪酸谱
作者从19,583个油样中提取了脂质,这些样品涵盖了十种食用油类:高芥酸菜籽油(HERSO)、低芥酸菜籽油(LERSO)、高油酸葵花籽油(HOSFO)、低油酸葵花籽油(LOSFO)、亚麻籽油(LNO)、玉米油(MZO)、米糠油(RBO)、大豆油(SBO)、花生油(GNO)和芝麻油(SSO)。不同油类的脂肪酸谱比较表明,在某些油类中存在优势脂肪酸(见图1)。此外,脂肪酸图谱中多个成分组成表明了脂肪酸组成的不均匀性,以及将每种油类分解为子类型的可能性 (见图1a)。相比之下,传统的化学计量方法不能清楚地分辨所有油簇(见图1)。
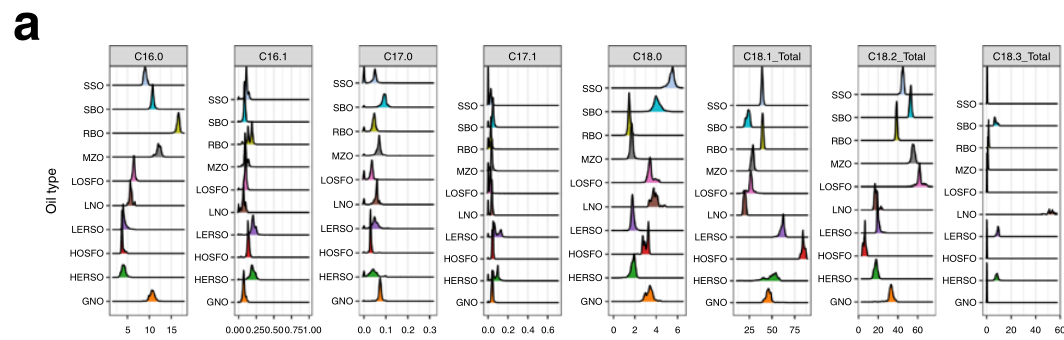

图1.a 花生油(GNO)、高芥酸油菜籽油、高油酸向日葵油、低芥酸油菜籽油、亚麻籽油(LNO)、低油酸向日葵油、玉米油(MZO)、米糠油(RBO)、大豆油(SBO)和芝麻油(SSO)等10种植物油的脂肪酸分布,在16种脂肪酸的相对丰度,从C16:0:C24:1。
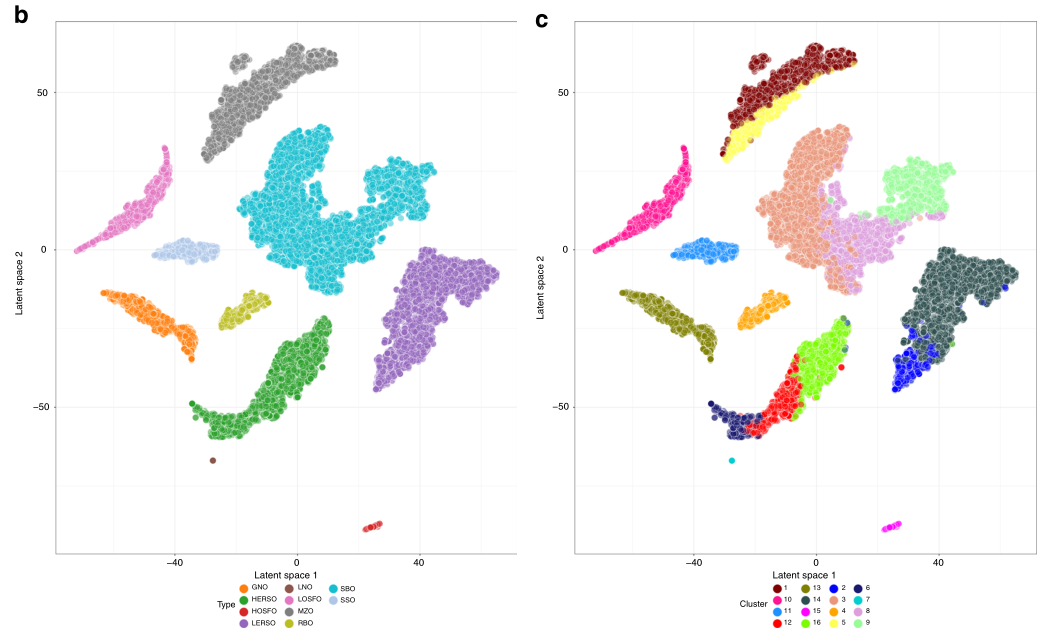
图1. b:十种植物油出现在潜伏的空间里,油簇颜色根据油的类型决定。c:在相同的潜在空间中着色的GMM油簇。
假设数据点可以从有限数量的高斯分布的混合生成,所以在数据上拟合高斯混合模型(GMM)来广泛验证该假设。同时,贝叶斯信息准则进一步优化了期望最大化算法的结果,总共产生了16个油簇(见图1c)。
作者为进一步揭示油内子簇所描述的组成,将GMM参数与子簇的经验分布进行了比较(见图1d)。研究结果表明,油在表型上随着多种脂肪酸的变化而不同。但差异是由于地理起源还是由于使用不同的加工方法,还有待研究。
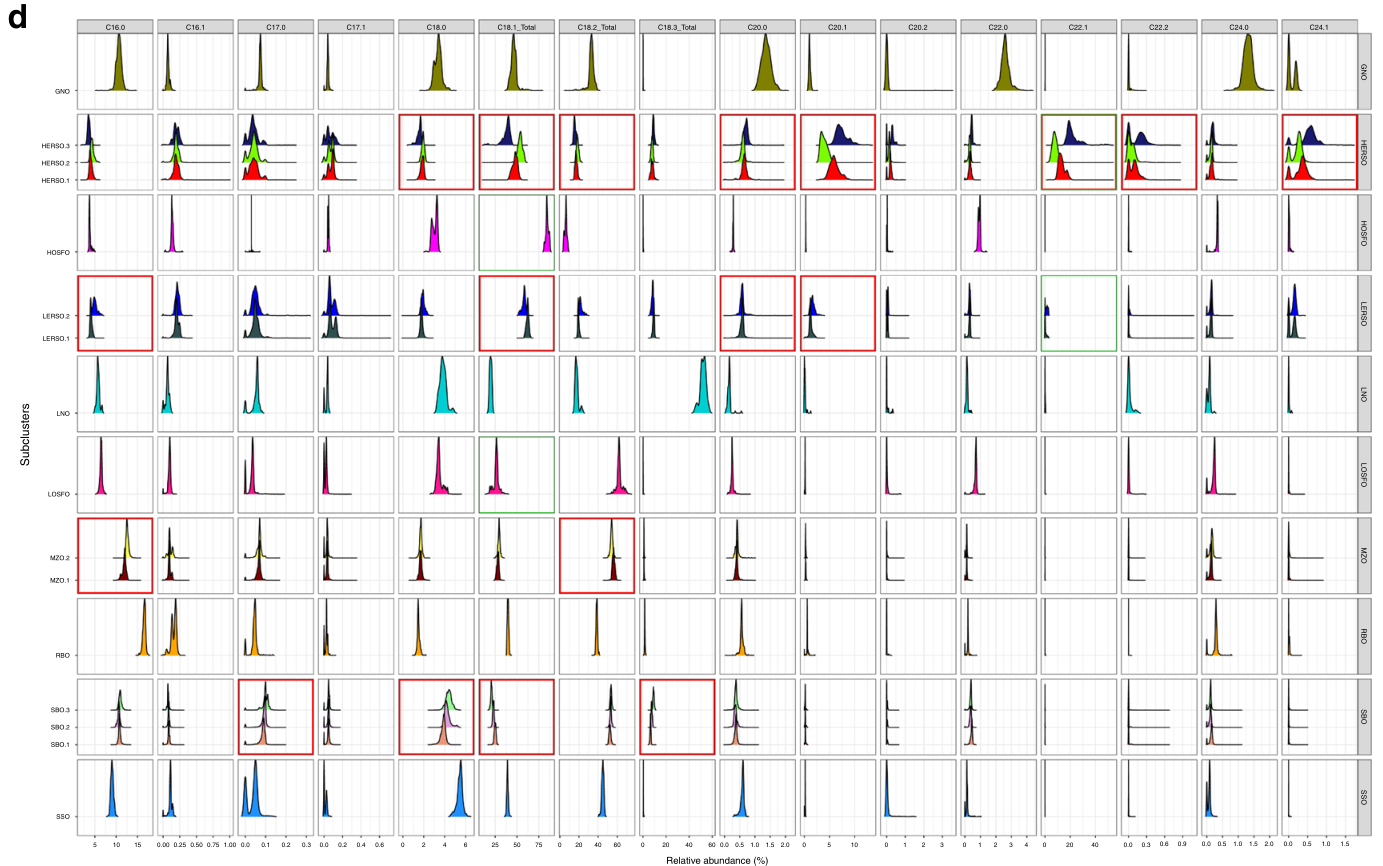
图1.d 用数字标记的子簇的经验分布,主要脂肪酸变化在红色框中突出显示。
2.2 油混合物的模拟
作者为了研究模拟油混合物的数据模式,比较了十种油类的大量模拟油混合物(见图2)。这一模拟结果表明,通过进一步的监督建模可以捕捉到广泛的混合趋势,而对于复杂的混合,预计会有较大的误差。
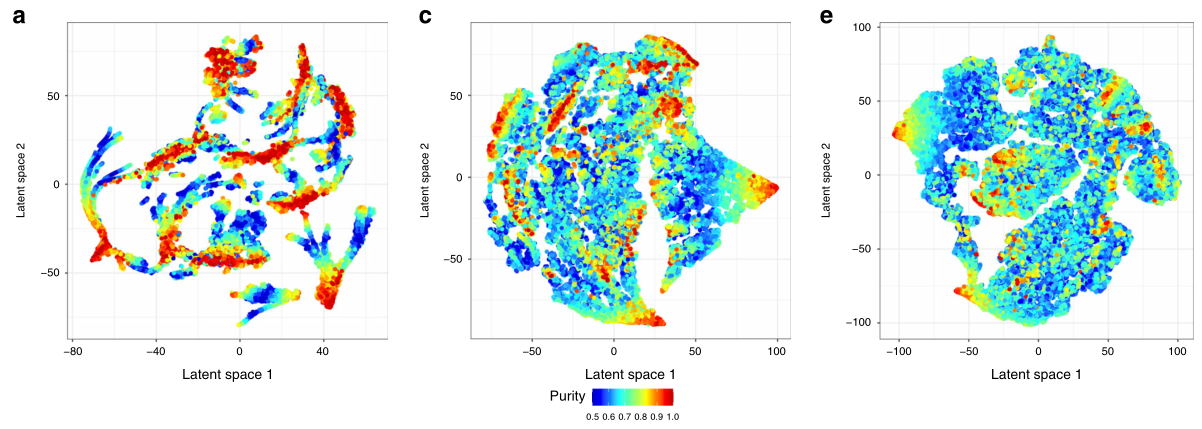
图2. 两种,三种和四种混合油的潜在空间。
(a–c)表示相对于主要油品测得的油品纯度。(d–f)使用十种颜色表示饼图中混合物的相对比例。a,b两种混合物中的十个中心描述了十种最纯净形式(红色)的食用油。如饼图所示,在另一种纯油类的中心,当两种油按等比例混合后,纯度变为50%(蓝色),然后又变回红色。尽管由于混合物的复杂性,中心变得更加模糊,但(c、d)三种和(e、f)四种混合显示出相同的组成。
2.3油成分的深度学习模型
作者总共生成了1200万个油混合物,用于构建和评价深度学习神经网络模型。描述机器学习工作流程的示意图(见图3)。结果表明,相比之下,深度学习模型对基于脂肪酸特征的未知油脂类型具有更强的归纳和区分能力。
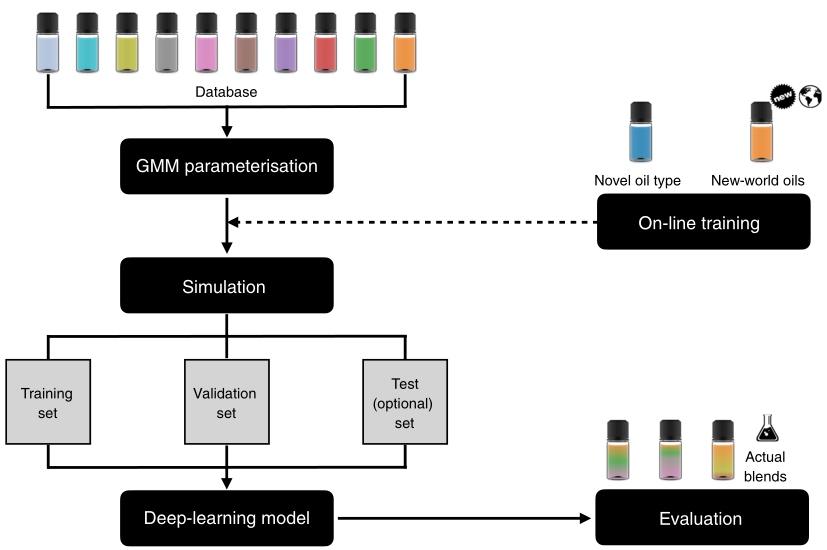
图3. 机器学习原理图
作者表明单一的模型,可以量化任何两种混合,而不需要任何先验知识的组成,可以解决简单油掺假问题。将双向模型推广到三种和其他复杂混合物也可以快速识别这些掺杂物。从两个方面进一步论证了深度学习模型的普遍适用性(见图4)。相比之下,当复杂性增加时,传统的化学计量学方法不能处理。其次,还进行了一项更真实的测试,其结果与模拟测试错误率非常接近。
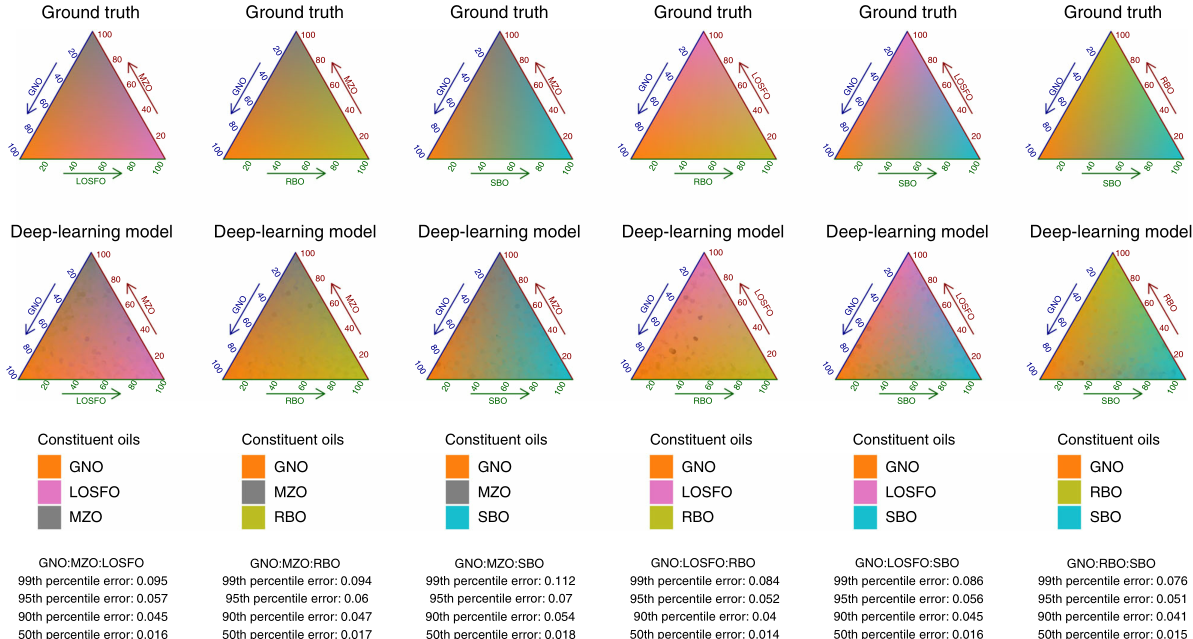
图4. 花生油掺杂常见的三种油成分深度学习结果。地面真值由Gibb三角形表示,三角形中的每个点对应三种油的精确比例,总和一致(上图)。颜色是:三角形代表纯度,颜色的变化代表另两种油的混合比例。三种油混合深度学习模型预测的结果根据相对比例进行着色。
2.4 在线学习的过程
作者为了评估由中国生产线工厂生产的油构建的模型性能,另外收集了来自中国,印度,日本,南北美洲,非洲和中东各个地区的56种纯花生油。无监督分析表明,这些56种油与初始数据集的花生油聚在一起,显示出区域共定位(见图6)。
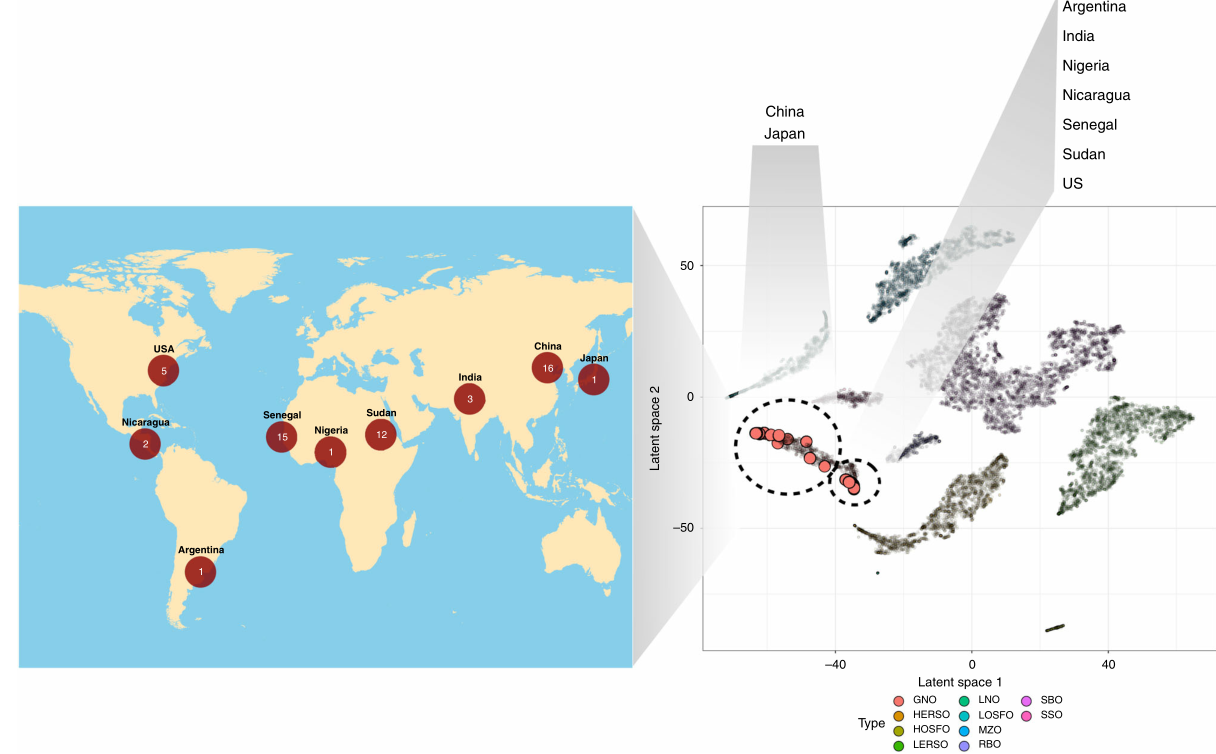
图6. 用于在线训练的花生油。56种新来源的不同花生油用于在线训练的潜在空间中。收集的样本按地图上所示的地理分布,样本数量用红色圆圈表示。
实验表明在线更新深度学习模型参数是可能的。这一过程提高了模型对真实混合物的预测精度。在线学习在新加的油类的稳健性也在盲测中进行了测试,结果证明在线训练在提高性能和将普遍适用性扩展到新油和分馏油方面的有效性。
3. 结论
作者利用从大量油样中收集的一组统一的脂肪酸图谱,进行了一项全面的研究,通过整合机器学习技术,得出推断和预测。传统的有监督化学计量学方法缺乏通用性。现有的将神经网络应用于脂肪酸数据集的方法很少,将有监督的深度学习机耦合到仿真过程有两个额外的优点:第一,仿真过程能够创建独立的混合,通过梯度下降来验证和优化深度学习模型。第二,当引入与现有油品表型不同的新油品时,该模拟过程可用于指导深度学习模型参数的更新。作者预计,在利用和扩展该模型以包括许多其他新世界油方面,将有更大的进一步研究范围。
参考文献
- Lim Kevin,Pan Kun,Yu Zhe,Xiao Rong Hui. Pattern recognition based on machine learning identifies oil adulteration and edible oil mixtures[J]. Nature Communications,2020,11(1).
关注我们

原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/fake-oil.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
中国农业科学院农业信息研究所樊景超研究员课题组:ITF-WPI 基于图像和文本的枸杞害虫识别跨模态特征融合模型
导读 2023年8月,中国农业科学院农业信息研究所樊景超研究员课题组在农业科学领域Top期刊Computers and Electronics in Agriculture(Q1,…
-
系统综述人工神经网络在食品加工过程中的建模应用
今天给大家介绍一篇由G. V. S. Bhagya Raj等人合作的,于近期发表在Critical Reviews in Food Science and Nutrition的一篇综述,文章中作者系统综述了ANN在食品加工等领域的应用进展并进行了展望。
-
食品质量和真伪分析评估的数据挖掘/机器学习方法
近年来,为了更好地鉴定食品,通过现代分析仪器所获得的数据种类和数量急剧增加。一些模式识别工具已经被开发来处理大量复杂的有效试验数据。应用最广泛的方法有主成分分析(PCA)、部分最小二乘判别分析(PLS-DA)、类模型方法(SIMCA)、k-最近邻分类算法(kNN)、平行因子分析(PARAFAC)和多元曲线分辨率-交替最小二乘分析(MCR-ALS)。然而,也有一些替代的数据处理方法,如支持向量机(SVM)、分类回归树(CART)和随机森林(RF)等,与传统的数据处理方法相比,显示出巨大的潜力和优势。在这篇文章中,作者解释了这些方法的背景,并回顾和讨论了这三种方法在食品质量和真实性领域的应用研究的报道。此外,作者声明清楚了在这一特定研究领域中使用的专业术语。
-
中国科学院上海技术物理研究所万雄课题组:基于β-胡萝卜素拉曼光谱定量检测的橄榄油鉴别
采用激光共聚焦拉曼技术与基于DFT的拉曼光谱相结合,准确分析了植物油的成分,并识别出低成本的仿制橄榄油。
-
食品设计:基于机器学习和机制的混合建模方法
当前,食品设计是通过不断试错并由品尝小组做出感官评价完成的。为了加快新食品的开发速度,提出了一种混合机器学习和机制建模的方法。用由所需食品过往数据训练的机器学习模型进行感官评价预测。该方法基于启发法、数据库等,首先确定候选食品组分和加工中的关键操作条件。与这些组分和加工条件(设计变量)有关的像颜色、松脆度和风味这样的食品特性都用到机制模型。通过改变设计变量来优化所需的食品特性,从而获得最高感官评分。使用遗传算法解决此灰箱优化问题,将设计约束(所需食品特性)处理为罚函数。提供了一个巧克力曲奇饼干的示例以说明混合建模结构的适用性和解决方案策略。
-
中国科学院蒋长龙团队:基于集成纸基传感器的便携式智能手机的无酶和快速视觉定量检测农药残留
今天介绍一篇由Qianru Zhang、蒋长龙等于2022年6月发表在Journal of Hazardous Materials上的一篇论文。该研究构建了一个简单、快速、可视化的无酶辅助的草甘膦(Gly)荧光定量检测平台。并且在设计的智能手机平台的辅助下制备了荧光试纸条,显示出作为便携式光学分析终端的潜力,用于定量跟踪真实样品中的Gly。该传感平台为Gly的定量检测提供了可靠的方法,可推广到分析科学领域的其他分析物或污染物筛选。
-
浙江农科院袁玉伟产地溯源团队:基于稳定同位素和元素剖面的中国和伊朗藏红花地理起源研究
近日,农产品质量安全危害因子与风险防控国家重点实验室的聂晶和袁玉伟等人对藏红花中的元素含量(%C和%N)和稳定同位素(δ13C、δ2H、δ18O和δ15N)进行分析检测,并结合化学计量学的溯源方法,成功区分了伊朗和中国的藏红花,并对中国国内主要产区进行了分类
-
VirtualTaste:用于预测化合物感官特性的网络服务器
今天介绍一篇来自德国柏林生理学研究所的Franziska Fritz和Priyanka Banerjee、生理和科学IT研究所的Robert Preissner于2021年4月27日发表的文章。该文章实现了用机器学习模型来预测三种不同的味道终点——甜味、苦味和酸味。开发了名为VirtualTaste的 Web服务器平台,用于预测三种不同口味的化合物。
-
Food Chem|衰减全反射-傅立叶变换红外光谱结合化学计量学快速检测椰子水掺假
该文研究了衰减全反射-傅立叶变换红外光谱(ATR-FTIR)与化学计量学相结合,作为一种快速检测椰子水中掺糖的方法。
-
基于质谱-机器学习技术的番茄分类:一个食品安全增强平台
今天介绍一篇由Arthur Noin de Oliveira等人于2022年8月发表在Food Chemistry(IF=9.231)上的文章。该研究旨在开发一个使用机器学习算法的平台,分析质谱数据,对番茄进行有机和非有机的分类。决策树算法被定制用于数据分析,该模型在确定每种水果属于哪个组时达到了92%的准确度、94%的灵敏度和90%的精确度。