今天给大家介绍一篇由Kirill Veselkov、Guadalupe Gonzalez等人合作,于前段时间发表在Scientific report的一篇文章。文章中作者介绍了一个独特的基于网络的机器学习平台HyperFoods,以识别推定的基于食物的抗癌分子。
作者:梁瑞
今天给大家介绍一篇由Kirill Veselkov、Guadalupe Gonzalez等人合作,于前段时间发表在Scientific report的一篇文章。文章中作者介绍了一个独特的基于网络的机器学习平台HyperFoods,以识别推定的基于食物的抗癌分子。
1 介绍
最新数据表明,仅饮食和生活方式措施就可以预防多达30-40%的癌症。本文介绍了一个独特的基于网络的机器学习平台,以识别推定的基于食物的抗癌分子。这些已通过其分子生物学网络与临床认可的抗癌疗法的共性而得到鉴定。一种在图形上随机行走的机器学习算法(在超级计算DreamLab平台上运行)被用来模拟人类相互作用网络上的药物作用,以获得1962种批准药物的全基因组活性谱(其中199种被归类为“抗癌”药物,其主要适应症)。使用这些“学习到的”相互作用组的活性谱的一种监督方法来预测癌症分子。经过验证的模型性能预测抗癌疗法的分类准确度为84–90%。将食物中7962种生物活性分子的综合数据库输入该模型,该数据库预测了110种抗癌分子(抗癌相似度阈值被定义为> 70%),其预期能力与临床批准的抗癌药物相当,这些抗癌药物来自各种化学类别,包括黄酮、萜类和多酚。这反过来被用于构建“食物图”,每种食物的抗癌潜力由其中发现的抗癌分子的数量定义。作者们的分析为下一代癌症预防和治疗营养策略的设计奠定了基础。
随着人口迅速老龄化,世界正在经受癌症、心血管疾病、代谢疾病和神经退行性疾病等慢性疾病造成的不可持续的医疗保健和经济负担。饮食和营养因素在预防这些疾病方面发挥着重要作用,并对患者在治疗期间和治疗后的疾病结局产生重大影响。根据最新数据,高达30%-40%的癌症可以通过改变饮食和生活方式来预防。植物性食品富含抗癌分子(CBM),如多酚、类黄酮、萜类化合物和植物多糖。实验研究证据表明了多种作用机制,饮食制剂通过这些机制有助于预防或治疗各种癌症。包括调节炎症介质和生长因子的活性,抑制癌细胞的存活、增殖和侵袭,以及血管生成和转移。
能够首先确定食品成分,然后设计出富含CBM并具有促进健康或治疗影响的“超级食品”, 这是降低医疗保健成本并潜在增强诸如癌症等慢性疾病的健康成果的空前机会 。在这个设计美食的时代,消费者的眼光越来越挑剔,要求越来越高,超级食品的设计是一个多方面的优化问题,不仅要考虑对健康的益处,还要考虑各种审美(如颜色、质地)和感官(如味道、口感)特征。作者认为,通过利用人工智能(AI)技术,至少可以通过计算来执行这种设计的某些部分。正如作者最近发布的10点宣言(“计算和食品的未来”)所概述的那样,这将需要包括食品生产商、厨师、设计师、工程师、数据科学家、感官科学家和临床医生在内的多个利益相关者的合作。
人类饮食中包含成千上万的生物活性分子,这些分子调节各种代谢和信号传导过程,药物作用以及与健康和疾病中肠道菌群的相互作用。研究单一生化食品成分的影响需要数月至数年的实验研究。此外,目前识别食物中影响健康的活性成分的方法无法考虑到众多复杂因素,例如食物的来源,如何种植,储存,加工和制备,更不用说烹饪参数和成分组合的效果。考虑到广阔的分子空间,因此无法使用当前的实验研究方法对定制的营养策略进行生物活性化合物的预测性识别。然而,人工智能技术的最新进展,加上食品、药物和疾病的大规模多源(“-组学”)数据的爆炸性增长,为识别食品中的分子以潜在预防和/或对抗疾病表型提供了独特的机会。这些研究通过结构相似性或单个基因编码蛋白靶点与已批准的治疗方法的相似性来识别食物中的分子。然而,即使一个分子的化学结构发生微小的变化,也会导致截然不同的生物结果,而复杂的疾病,如癌症,不能用个体基因/蛋白质活性的失调来解释。最近的几项计算研究试图利用“组学”数据来提取关于食物、药物和疾病之间的有利和/或不利相互作用的看法。郑等人利用公开获得的细胞培养和动物模型的基因表达和交互组数据来鉴定与疾病基因表达表型反相关性的药物和饮食。由于现有饮食诱导的基因表达数据集的规模很小,因此这种相关性驱动的分析仅限于数量非常有限的食物。然而,通过这种方法发现了耐人寻味的饮食与疾病的联系。将化学信息学和文本挖掘相结合的策略应用于数百万份PubMed摘要,以确定植物性食品的分子成分和疾病表型之间促进健康或有害的联系。该策略随后被扩展到识别干扰药物代谢酶的食物成分(“药代动力学”)或与药物靶标相互作用(“药效学”)相互作用的食品成分。尽管前景广阔,基于自然语言处理(NLP)的自动关系抽取系统迄今为止在很小的子集(< 200)上测试了一些带有主观注释的摘要。正如我们最近所强调的,它们在有数百万篇文章的数据库(如PubMed)上的应用保证了对错误发现率的广泛验证和对支持证据的提取,以建立对计算机衍生关联的信任。然而,这些发展有助于编纂“组学”食品数据库和公共资料库,如食品数据库(FooDB)、风味数据库(FlavorDB)和营养数据库(NutriChem)。
癌症等复杂疾病不能用单基因缺陷来解释,而是涉及通过一系列分子相互作用(“网络”)介导的各种分子功能的分解。产生的癌症分子表型的多样性使得很难确定用于癌症预防或治疗的特定分子靶标。作者假设有效的癌症预防或治疗干预措施应针对与致癌作用有关的多种生化途径,例如炎症,细胞增殖,细胞周期,细胞凋亡和血管生成。根据这一假设,制定了一种基于机器学习的策略,该策略基于经过临床验证的抗癌疗法靶向的“学习的”分子网络来预测CBM。作者的策略包括组合使用图形上的无监督学习来模拟疗法对人类蛋白质网络(从“稀疏的”蛋白质目标数据集)的下游影响,然后使用监督学习来识别CBM的预测(子)网络。模型性能评估采用10倍交叉验证策略,证实了抗癌治疗药物的准确预测。一个包含7692个食品中生物活性分子的综合数据库被输入到模型中,以预测~110个CBM,结果是一个汇编的显示最多潜在CBM数量的超级食品清单(ACL>0.7)。此外,开发的方法可以很容易地外推到未来,以涵盖其他类型的疾病(如糖尿病)和健康问题,以提供促进健康的食品分子的全面、多方面的图景,并优化现有的烹饪食谱,以最大限度地对健康产生积极影响。作者预计,这第一份“抗癌”食品清单将成为未来美食医学基础的支柱之一,并应有助于创建个性化的“食品护照”,为人们提供有营养的、量身定做的和具有治疗功能的食品。然而,未来还需要大量的工作来验证和量化这些拟议的超级食品的治疗效果,以及优化其成分的种植、储存、加工和烹饪参数。
2 结果和讨论
2.1用于药品和食品重新定位的基于网络的机器学习策略
本文介绍的工作利用了关于分子与基因编码的蛋白质相互作用以及蛋白质-蛋白质相互作用数据的公开数据。简而言之,药物和它们的蛋白质/基因靶标之间相互作用的稀疏数据最初被绘制在大规模的相互作用网络上——一整套人类蛋白质之间的相互作用(在这里,进一步由于现有相互作用数据集的特殊性,“基因”和“蛋白质”术语可以互换使用)。大多数药物通过结合特定的蛋白质子集来发挥其生物医学和功能活性。蛋白质很少单独发挥作用,而是作为高度互连网络的一部分发挥作用。考虑到这一点,在具有重启功能的图形上定制了随机游动(由单个网络扩散参数“ c”控制),以使用目标蛋白质的汇总数据集模拟单个蛋白质在人蛋白质组网络上的扰动。最近,类似的基于网络的传播方法在预测药物-靶点相互作用和评估癌症突变引起的网络扰动方面得到了有利的比较,以改善患者分层。这种网络扩散是根据给定分子/药物靶向蛋白质的网络与靶标候选物的接近程度,将一小部分蛋白质靶向的蛋白质/药物转化为基因评分的全基因组分布图。利用药物的全基因组图谱,训练有监督的机器学习策略(在这种情况下是“最大限度标准”和支持向量机),以准确地对分子的“抗癌”(vs“其他”)属性进行分类。获得的最佳模型用于预测给定的现有批准药物显示抗癌特性的概率。在验证了模型对抗癌药物重新定位的预测能力后,应用相同的机器学习策略来预测食物中的各种抗癌分子(图1)。应当注意的是,有各种方法用于药物重新定位,例如分子结构共性、分子靶相似性以及共有的遗传或表型(例如副作用概况)影响。然而,这些方法需要额外的数据集(如基因表达数据、蛋白质组学、代谢组学或表型效应数据)来建立模型。在寻找基于食物的抗癌分子时,这些数据非常有限。
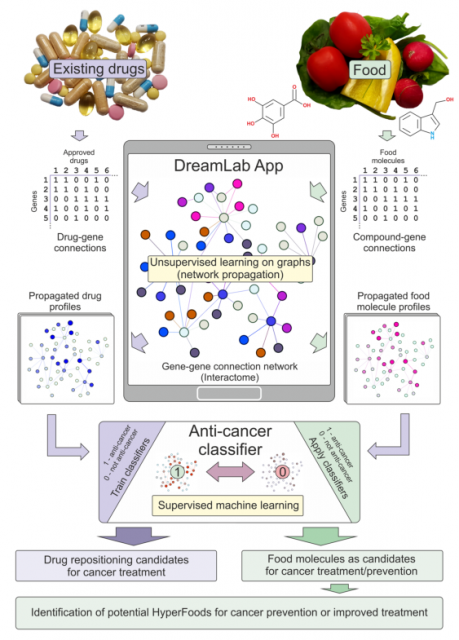

2.2 机器学习策略的基准测试和优化
在尝试的机器学习方法中,MMC和具有线性核的SVM表现出相当的性能和相对好的处理速度(包括参数优化、模型训练和10倍交叉验证的预测)。径向核SVM没有超过线性方法的性能,同时需要更长的处理时间(获得的最佳径向核SVM F1分数为0.85,而线性核SVM为0.86)。此外,径向支持向量机的最佳伽马参数趋向于非常低(~ 107),有效地使它们类似于线性核支持向量机。我们还探索了2个神经网络分类器和2个正则化LASSO/Elastic分类器,以查看它们是否带来分类精度的任何改进。对于最佳执行类型的交互作用和图形上的随机行走设置,这些更先进的方法产生了可与线性SVM和最小均方误差相比的预测精度(见国际标准化组织附录M1)。这在涉及少量例子和大量特征的基因组学研究中是众所周知的,其中线性分类器是优选的,因为它们的透明性和生物可解释性。因此,在最后一轮优化中,主要关注的是线性核SVM和最小均方误差方法。用线性核SVM可以得到的最佳f得分为0.86,抗癌预测的正确率为84%,非抗癌预测的正确率为90%。对于相同的设置,多次重新运行优化显示出一致的性能(最大差异为1-2%)。基于这些结果,决定从基于现有批准药物(国际标准数据集S2)和食物化合物(国际标准数据集S3)的线性核SVM和最小均方误差模型的模型中选择用于抗癌相似性预测的前700个模型(f得分> = 0.84)。有趣的是,系统地展示了输入传播的配置文件对数变换来提高分类器的性能。这可能是因为一些个别的孤立的基因,它们不繁殖,因此停留在非常高的扰动水平,将对对数空间的整体轮廓有较小的影响。与此同时,随机步行者的“c”参数和化合物与基因之间的不同匹配设置具有不太明显的效果。基因-基因连接阈值也没有很大的影响,除了在生物复合物相互作用的情况下。这可能是因为STRING提供的连接往往包括广泛的知识来源,提供了更具代表性和更完整的基因-基因(或蛋白质-蛋白质)相互作用的图形,连接的绝对数量可以补偿较大的“c”值和使用的较高阈值。我们还评估了单个基因对最终分类的影响,即基因重要性,通过发现基因水平和优化模型预测结果之间的相关性。SI数据集S4提供了针对前700个模型的平均重要性预测的完整表。不出所料,最受好评的基因参与细胞增殖控制,其突变通常与癌症有关。这为基于机器学习的药物抗癌特性预测提供了透明度。
2.3 途径分析和差异化交互组
使用基因集富集(国际标准化组织数据集S4)对基于网络的机器学习中产生的用于预测抗癌疗法的最有影响力的基因/蛋白质的列表进行通路分析。在受影响的前25个途径中,有细胞周期,DNA复制,凋亡,p-53信号转导,JAK-STAT信号转导和错配修复以及各种癌症特异性途径。这增加了此处使用的建模方法的生物学可行性,被确定为关键驱动因素的途径始终与癌症的发展和进程有关。在图2中,给出了相关的区分基因及其相应的受影响通路。在这里,单个结节的大小对应于给定基因编码蛋白的相对区分能力,结节的颜色说明了共享的生物学通路功能。越来越多的人认识到,癌细胞存活、扩散和治疗抗性的机制基础是多方面的,涉及多种生化途径。在作者的分析中,大多数机器学习衍生的通路被认为是癌症预防或治疗干预的目标。因此,“理想的”抗癌药应该能够破坏多种致瘤生化过程。这里提出的机器学习方法强调了受目前使用的抗癌疗法影响的生物通路,因此允许并行有针对性地搜索独特的试剂,在这种情况下,与食物的生物活性化合物,具有同时影响多种通路的潜力。
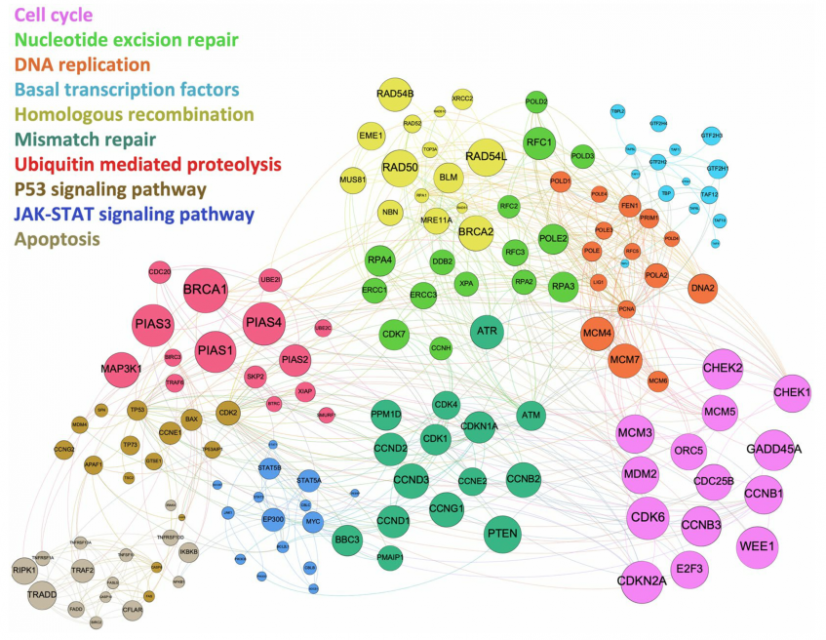
2.4 肿瘤药物重定向的相互作用组学方法
完整的预测摘要在国际标准数据集S2中给出。正如预期的那样,目前用作癌症治疗的大多数化合物显示出很强的抗癌可能性。有趣的是,几种不常用于癌症治疗的化合物显示出很高的抗癌相似性。对这些化合物的现有文献进行了进一步的调查,以了解这些药物潜在抗癌作用的机制基础。例如,喹诺酮衍生物罗沙星和基于喹啉的氯喹啉主要分别作为抗微生物剂和抗真菌剂。然而,这里提出的分析表明了这些疗法在癌症中的潜在直接作用。喹诺酮类抗生素显示出对真核拓扑异构酶-2的显著抑制作用,导致各种癌细胞类型的细胞毒性。这组化合物可以与抑制人拓扑异构酶-II的抗肿瘤药物如阿霉素和依托泊苷进行比较。氯喹啉是锌、铜和铁的螯合剂,已知它们参与致癌和血管生成。氯喹啉的抗肿瘤活性被认为是通过几种潜在的机制,包括NF-kB凋亡诱导、mTOR信号传导和溶酶体抑制。尽管前景广阔,但其在癌症治疗中的作用在临床上仍未被探索。二甲双胍和吡啶甲酸铬等抗糖尿病药物也成为本次评估中抗癌药物重新定位的潜在候选药物。导致这种联系的分子机制仍不确定,但是这两种药物都通过调节胰岛素信号级联来缓解胰岛素抵抗,许多研究表明铬特异性地改变近端胰岛素信号,并直接影响胰岛素受体磷酸化和激酶活性。二甲双胍和铬治疗的下游结果是胰岛素和胰岛素样生长因子水平的降低,这反过来被理解为抑制mTOR信号通路中的几个关键过程,MTor信号通路是多种癌症的中心分子驱动因素。相应地,二甲双胍的使用和二型糖尿病的癌症发病率之间的综合分析显示了很强的相关性。相比之下,吡啶甲酸铬可能是一把双刃剑,因为它能干扰DNA,导致结构性遗传损伤,从而促进致癌作用。这个例子强调了我们的方法在识别与相关致癌过程相互作用的分子方面的局限性,而不考虑相互作用的性质(即抑制或刺激)。识别分子相互作用的性质需要额外的数据集,如基因表达或蛋白质组学,但这些通常不适用于基于食物的分子。
2.5 食物中抗癌分子的预测
在所有获准用于抗癌治疗的小分子中,几乎一半来自天然产物。这些药物对正常细胞的耐受性一般更高,毒性更低。接下来,将上面概述的方法应用于预测各种食品类别中〜7692种生物活性化合物的抗癌相似性。这里提供了食物中类药物分子的全面视图,与迄今为止文献中的大多数研究都倾向于集中于单一化合物或单一食物类型不同。鉴定并分类了大约110种来自不同化学类别的分子(参见图3),包括萜类,异类黄酮,类黄酮,多酚和类固醇,并根据其食物来源使用多个实验数据库作图。 SI Dataset S3中提供了按> 0.1的抗癌药物相似性按代理排名的食物分子的完整列表。使用无监督学习随机行走图,作者传播了最有希望的分子对人类相互作用网络的影响,并确定了其影响的分子途径(有关详细分析,请参见仅针对ACL> 0.7的化合物参见SI Dataset S3和SI Dataset S5)。 SI附录表S1总结了本研究中确定的ACL> 0.7高的抗癌化合物及其相关食物来源的列表。此外,对现有的顶级抗癌药物样分子(ACL> 0.9)及其推定的抗癌作用分子机制进行了全面综述(SI附录表S2)。来自文献的计算分析和实验数据均表明,负责这些抗癌特性的途径和机制涵盖了作者目前对致癌多步过程的理解的广度。这些包括抗炎,促凋亡作用,有效的抗氧化活性和清除自由基。调节细胞增殖,细胞分化,癌基因和抑癌基因中的基因表达;调节解毒,氧化,调节激素代谢中酶的活性;以及抗菌和抗病毒作用。例如,在芸苔属蔬菜家族(包括卷心菜,西兰花和抱子甘蓝)的成员中大量发现的3-吲哚甲醇似乎是最强的抗癌分子之一。该生物活性化合物已显示出靶向癌细胞周期调控和存活的多个方面,包括胱天蛋白酶激活,雌激素代谢和受体信号传导以及内质网功能(参见SI附录表S2及其中的参考文献)。其他显着的例子包括dydamin(一种在柑橘类水果中发现的类黄酮糖苷)和apigenin(在香菜,香菜和莳萝中特别丰富)。两者均被理解为影响凋亡途径以及细胞周期停滞机制,并且被认为抑制癌细胞的迁移和侵袭(参见SI附录表S2及其中的参考文献)。图4提供了与强抗癌相似性相关的CBM的直观总结。图中的每个节点表示特定的食品,并且节点大小在每种情况下都与CBM的数量成比例。节点之间的联系反映了食物中CBM的成对相关性,因此图4中的食物的聚类说明了它们之间的分子共性。煤层气中表现出最大多样性的食物包括茶,葡萄,胡萝卜,香菜,甜橙,莳萝,白菜和野生芹菜。
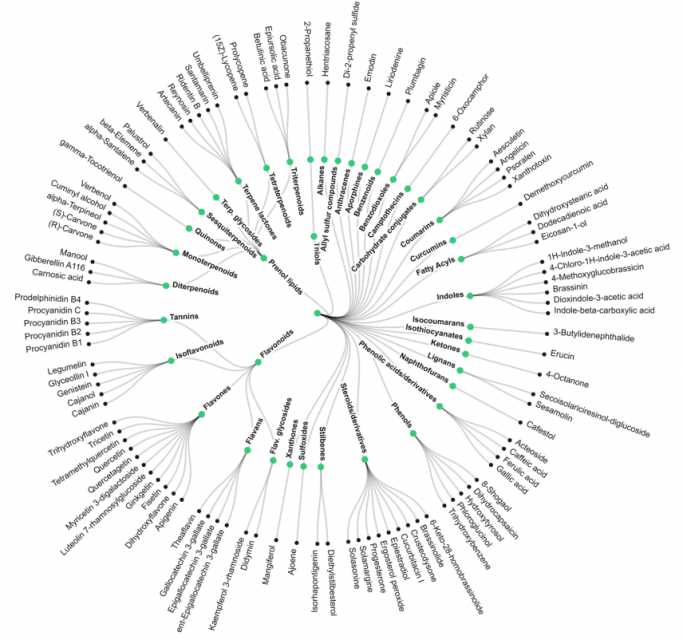
2.6 食物图和植物化学协同作用。
食物来源发挥其预防或治疗作用的潜力取决于其中所含的抗病分子化合物的生物利用度和多样性。关于基于食物的化合物的现有文献的一个关键限制是通常采用的主要是一维视图,而研究倾向于集中于分离的特定分子成分,例如抗氧化剂。公认的是,定期食用水果和蔬菜可以降低致癌的风险(42)。但是,当单独发挥作用的抗增殖药已接受临床试验评估时,它们似乎并不能始终如一地带来相同的获益水平。对于苹果,这一点很容易说明。苹果提取物含有生物活性化合物,已证明在体外能抑制肿瘤细胞的生长。然而,有趣的是,保留果皮的苹果中的植物化学物质抑制结肠癌细胞的增殖达43%,而测试不含果皮的苹果时,这种作用降低到29%。因此,从这些观察结果中可以明显看出,在对抗诸如癌症等复杂疾病的过程中,成功实施以食物为基础的方法将依靠生物活性物质(例如存在于整个水果和蔬菜中的生物活性物质)的联合体,以增加对食物的吸收。成功的机会。因此,给定食物的抗癌特性将由(1)其各个成分的加和,拮抗和协同作用以及(2)这些成分同时调节不同的细胞内致癌途径的方式决定。例如在茶的情况下,这两个条件都得到了满足,发现与其他食品成分相比,茶具有很强的抗癌药样特性。茶是儿茶素(epigallocatechingalallate),萜类化合物(lupeol)和丹宁酸(procyanidin)的丰富抗癌分子来源,其中三种具有强而互补的抗癌作用,可通过保护反应性氧化物质诱导的DNA损伤,抑制炎症来发挥作用。并分别诱导凋亡和癌细胞周期阻滞。相应地,最近的一些荟萃分析表明,食用绿茶可证明癌症发作延迟,治疗后癌症复发率降低以及长期癌症缓解率增加43,44。其他实例包括柑橘类水果,例如甜橙,其中分别含有强力抗氧化剂,促凋亡和化学增敏作用的dydimin(柑橘类黄酮),obacunone(柠檬苦素葡萄糖)和β-榄香烯。后者具有强大的作用,尤其是针对不同类型癌症中的耐药性和复杂恶性肿瘤。通过对多个病例对照研究和前瞻性观察研究的荟萃分析,证实了柑橘类水果摄入量与不同类型癌症发生率之间的负相关关系45。基于这种理解,我们已经构建了由250多种不同食物来源组成的抗癌药样分子谱(参见图4和SI附录表S1)。
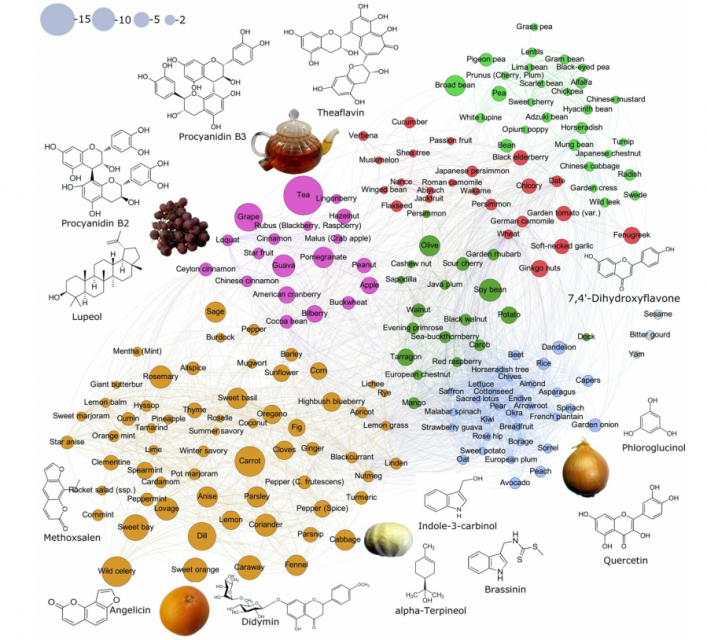
3 结论
使用基于网络的机器学习方法表明,基于植物的食物(例如茶,胡萝卜,芹菜,橙子,葡萄,香菜,卷心菜和莳萝)包含最多的具有高抗癌性的分子,这是通过对分子网络的方式与现有疗法相似。大规模计算分析进一步证明了某些食品具有更大的抗癌潜力,需要更多的定制营养策略。然而,同样重要的是要认识到所提出方法的局限性;首先,没有考虑生物活性分子的浓度,目前尚不清楚它们是否以足够的浓度存在以发挥其有益的生物活性。此外,所提出的方法仅考虑了生物活性食品化合物与癌症相关分子网络之间的相互作用,而没有明确考虑这些关系的方向性。此外,此处描述的方法未考虑特定的癌症分子表型特征。最后,尚未评估药物与食物之间的相互作用,尚不清楚它们在共同的分子网络上起作用时是否会产生协同或拮抗作用(药效学),或者这种组合是否会破坏药物代谢本身(药代动力学)。尽管如此,食物还是个人健康当中最可能改变的方面,这里描述的机器学习策略是认识到“智能”营养计划在预防和治疗癌症中的潜在作用的第一步。概述的方法不仅限于癌症,还将适用于其他健康状况。此外,它将为超级食物和美食医学的未来铺平道路,并鼓励引入个性化的“食物护照”,为每个人提供营养,量身定做和具有治疗功能的食物,以惠及更广泛的人群。
参考文献:
- Veselkov K, Gonzalez G, Aljifri S, et al. HyperFoods: Machine intelligent mapping of cancer-beating molecules in foods[J]. Scientific reports, 2019, 9(1): 1-12.
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/hyperfoods.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
机器学习技术对食品销售预测的最新进展
本文回顾了用于预测食品销售的现有机器学习方法。讨论了从事食品销售预测的数据分析师的重要设计决策,例如销售数据的时间粒度,用于预测销售的输入变量以及销售输出变量的表示形式。同时回顾了已应用于食品销售预测的机器学习算法以及评估其准确性的适当措施。
-
JCIM: 填补化学生物学空白:生物活性食品化合物靶点空间的系统分析和预测
今天介绍一篇由Andrés Sánchez-Ruiz和Gonzalo Colmenarejo于2022年8月在线发表在Journal of Chemical Information and Modeling上的文章。文章使用化学信息学统计模型 [相似性集成方法 (SEA),结合最大 Tanimoto 系数 (TC),标记为”SEA + TC”]预测与人类靶点的相互作用,并根据靶点类别和化合物类别、有利与不利的组合、丰富的支架以及与已发表的数据进行比较来分析结果。
-
基于二维相关光谱与卷积神经网络的食用油产地溯源与掺假分析
今向大家介绍一篇来自武汉轻工大学的刘言等人在SPECTROCHIM ACTA A上发表的一篇论文。该研究基于食用油的二维相关光谱并设计卷积神经网络(CNN)对食用油的同步相关谱和异步相关谱进行分析。用一组不同产地的芝麻油和另一组掺有其他植物油的橄榄油对该方法进行了评价。两个数据集的预测准确率分别为97.3%和88.5%。
-
人工智能生产的烤牛肉风味
通过与微软的合作,芬美意香料公司能够利用其整个原材料数据库,找到各种成分的完美结合,从而产生“轻度烤牛肉”的味道。该产品代表了该行业的一个里程碑,因为他们声称这是有史以来第一款由人工智能(AI)创造的口味。
-
基于输入修正卷积神经网络的电子鼻和高光谱图像融合羊肉新鲜度检测
今天介绍一篇来自安徽大学翁士状副教授课题组于2022年3月发表在Food Chemistry上的文章。该研究采用电子鼻和高光谱图像相结合的方法对羊肉总挥发性盐基氮(TVB-N)进行综合评价。为准确分析羊肉新鲜度提供了一种途径,并为其他肉类品质的研究提供了技术依据。
-
Food Chemistry|深度学习在基于图像的中国市场食品营养估计中的应用
该研究在视觉识别任务中利用了深度学习技术,并提出了一套大数据驱动的深度学习模型,从食物图像回归到营养估计,最大限度地发挥了深度学习模型的潜力,同时为未来将人工智能引入食品领域提供了基础。
-
智能食品加工:从人工神经网络到深度学习的旅程
人工神经网络在食品加工中的应用方面取得了巨大成功,如食品加工过程中分级、安全和质量检查等。今天给大家介绍一篇来自印度的一篇发表在Computer Science Review上的题为《智能食品加工:从人工神经网络到深度学习的旅程》一篇综述,该文分三个单元介绍给大家:(一)智能食品加工中的各类人工神经网络、(二)基于人工神经网络(ANN)的智能食品加工、(三)基于深度学习(DL)的智能食品加工。本文介绍综述中的第一个单元:(一)智能食品加工中的各类人工神经网络。
-
植物油中化学物质污染的安全风险评估和预警
今天介绍一篇由上海大学生命科学学院发表于Food Control的一篇文章。文中针对中国的实际情况,分析了三种食用植物油的化学危害污染状况,通过建立多种膳食暴露评价模型,对食用植物油中的苯并芘、黄曲霉毒素B1和重金属进行了风险评价。在此基础上,对食用植物油化学危害的综合风险评价进行了研究,并利用AHP-BP方法建立了食用植物油化学危害程度的预测模型。
-
机器学习在食品安全中的新兴应用
今天分享一篇最近由美国乔治亚大学的Xiangyu Deng发表在Annual Review of Food Science and Technology上的综述。文章对食品安全和公共卫生特定领域下的机器学习进行了介绍,回顾近期和显著的进展,并讨论挑战和潜在的缺陷。