今天分享一篇最近由美国乔治亚大学的Xiangyu Deng发表在Annual Review of Food Science and Technology上的综述。文章对食品安全和公共卫生特定领域下的机器学习进行了介绍,回顾近期和显著的进展,并讨论挑战和潜在的缺陷。
摘要 ABSTRACT
今天分享一篇最近由美国乔治亚大学的Xiangyu Deng发表在Annual Review of Food Science and Technology上的综述。文章对食品安全和公共卫生特定领域下的机器学习进行了介绍,回顾近期和显著的进展,并讨论挑战和潜在的缺陷。
1. 绪论
在人口增长、城市化和全球化等宏观社会趋势的推动下,粮食生产、分配和监管发生了重大转变。近年来,食品行业和供应链的巨大变化和进展产生了大量数据,在从农场到餐桌的不同阶段、食品供应链的末端也产生了大量的数据。这些新型数据流(NDS)越来越多地通过社交媒体、搜索历史、众包网站、消费者评论以及产品销售和消费记录数据库等数字平台传播和访问。挖掘这些数据以揭示食品安全和公共健康的时代即将到来。
文章表明在监测方面,数据密集型系统在追踪食源性疾病病例和病原体方面发挥着重要作用。监测和疫情调查中实施全基因组测序(WGS)推动了新系统中可公开获得的食源性病原体基因组的爆炸式增长。WGS在公共卫生微生物学中的常规使用催生了一个数据驱动的领域,称为基因组流行病学。
2. 机器学习介绍
作为人工智能的一个子领域,机器学习不同于传统的算法问题解决方法,因为它不尝试编写详尽的显式指令或规则列表。相反,机器学习系统从示例中学习并根据它们与学习示例的接近程度(基于实例的学习)推广到新案例,或者使用数据训练模型以通过优化学习其参数,并使用新的(测试)数据进行预测(基于模型学习)。
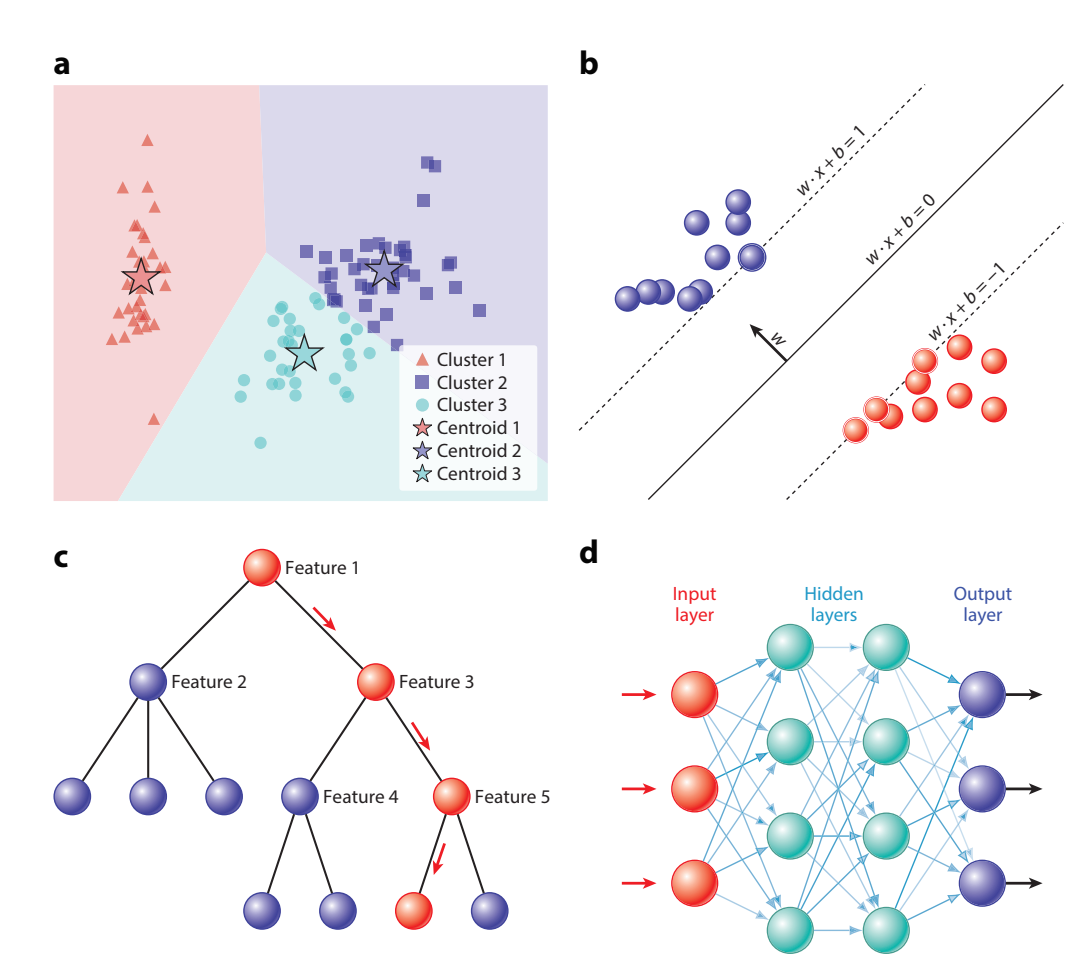

Figure 1. 机器学习模型示例。(a)具有三个聚类的K-means聚类的决策边界图,新样本根据其所在的有色区域分组到一个簇中。(b)在支持向量机中以一定余量划分两个类的线。w包含可训练参数,x代表样本的向量表示。(c)具有五个特征的决策树。一个样本按照红色箭头被分类到某个类别中。(d)具有两个隐藏层的神经网络;箭头代表单元之间的连接,透明度表示连接强度。
3 基因组数据的机器学习应用
传统的抗菌药物耐药性或敏感性的测量依赖于表型分析,即测量抗菌药物对纯培养细菌群的生长抑制。抗菌药物敏感性试验(AST)确定药物的最低抑制浓度(MIC),以使特定细菌分离物失活或抑制其生长。在临床环境中,准确、快速的AST可以及时为临床决策提供信息,提高抗生素的管理水平。利用现有的抗生素耐药性(AMR)监测基础设施和机器学习的算法过程,对食源性病原体的研究迅速展开。大多数临床医生倾向于对AST结果进行分类解释。一种使用训练基因组的k-mer表示作为输入特征的无参考集合覆盖机(SCM)模型由于学习不受现有AMR机制知识的限制,有可能识别新的AMR生物标志物。SCM模型能够在整个基因组中筛选出与AMR具有生物学相关性的关键k-mers。这可以促进领域专家对机器学习结果的解释,并将这些结果转化为常见的临床诊断。与分类法相比,MIC测量能进一步实现AMR的粒度表征和精确监测。采用基于k-mer的无参考极端梯度提升(XGBoost)模型对非伤寒沙门氏菌的MIC进行预测,在±1倍稀释步长内达到了了0.95的平均准确度。
由于大多数食源性感染的来源信息在很大程度上是未知的,很难了解食源性疾病的流行病学并制定干预措施来预防和减轻此类疾病。主要的食源性病原体,如沙门氏菌和大肠杆菌,是人畜共患肠道细菌,其主要宿主包括家畜和野生动物。使用SVM分类器来预测大肠杆菌O157的宿主特异性发现,高达85%的人类和91%的牛分离株被正确分类到各自的分离宿主中。然后将宿主特异性预测扩展到沙门氏菌。对来自人类、禽类、猪和牛的67-90%鼠伤寒沙门氏菌分离株进行了与宿主一致的预测。尽管鼠伤寒沙门氏菌以广泛的人畜共患病宿主范围而闻名,但只有一小部分分析的分离株对多个宿主具有高概率评分。大肠杆菌的结果也类似。
AST和归源代表了基因组数据中相关但不同类型的表型推断。当机器学习推理旨在识别与特定表型相关的遗传变异时,它可以被认为是微生物全基因组关联研究(mGWAS)的一个子集。由于AMR通常由单个或少数基因赋予,因此AMR生物标志物的功能确认相对简单。相比之下,源关联是由细菌、宿主和环境变量相互作用形成的更为复杂的现象。临床和公共卫生环境中的机器学习实践可能会受到标准化方法需求的挑战。基于WGS的AST部署的主要障碍是缺乏方法标准化,例如抗性基因数据库和质量控制指标。同样,训练集的设计、机器学习算法的选择以及验证策略都给标准化带来了困难。
4 基于新型数据流的机器学习应用
NDS支持被动、连续、自动的数据收集,以增强观察结果的及时性、细节、广度和可扩展性,而专门为食品安全建立的原始数据系统可能无法做到这一点。三种主要的NDS数据源包括文本数据、交易数据和贸易数据。文本数据在机器学习技术中的应用最为广泛。
文本数据以自然语言文本的形式表示松散或非结构化的信息,可为监测和应对食品安全污染事件或威胁提供实时信息。与机器学习技术一起应用于食品安全应用的NDS文本数据源可分为用户生成的公共帖子数据和基于web的数据。来自用户生成帖子的文本数据包括在社交媒体网站上发布的帖子,如Twitter和Facebook,众包消费者评论网站,如Yelp和亚马逊,以及IwasPoisen.com等参与式系统。帖子数据还可能包括专有内容,如公司消息和反馈板、用户论坛和博客,以及查询数据,如谷歌搜索历史。web数据源包括新闻媒体和学术或专业组织网站上的文章。
涉及食品安全文本数据的研究和应用集中于使用文本挖掘和自然语言处理技术,以食源性疾病或食品安全事件的报告补充传统的监测系统。可以监控社交媒体、评论、新闻和其他网络数据,有助于捕捉在社交媒体平台上人数过多但在全国食源性疾病爆发统计中人数不足的年轻用户的报告,解决食源性疾病发病率漏报的关键问题。
将高维非结构化文本内容转换为可操作的食品安全信息需要一种多步骤分析方法(图2)。工作流可以从获取数据的数据科学技术开始,然后是数据处理步骤,包括数据清理或预处理(例如拼写/语法更正、填充词移除和元数据噪声移除)和数据缩减(过滤),在机器学习算法最终应用于数据学习和预测之前。关键词识别通常是提取或过滤可能包含食品安全相关内容的数据的第一步。一组特定的关键字或短语通常是预先构造的,可能包括诸如疾病、食物中毒、呕吐和恶心等词。一个常用的机器学习任务是将帖子或网站数据分类为与食品安全事件相关或不相关。在这些上下文中使用的分类算法包括决策树、支持向量机、朴素贝叶斯和神经网络。
Figure 2. 文本数据机器学习分析方法的框架示意图
5 机器学习在食品安全领域的挑战、潜在缺陷和未来发展
NDS的被动生成和收集虽然提高了观测的及时性、细节性、广度和可扩展性,但也带来了新的挑战,包括有偏见的样本、隐私问题和安全问题。由于食源性疾病报告环境的不确定性,样本偏差和NDS生成过程中出现的相关问题更加复杂,当与自动机器学习任务相结合时,尤其是对于众包监控等应用,这种情况会带来独特的挑战和陷阱。虽然研究人员已经意识到这些问题,但解决这些问题是一个活跃的研究领域,这里回顾的大多数方法和应用仍处于研究和开发阶段。
尽管如此,当NDS与用于模型开发和特征选择的机器学习技术相结合时,它在提供改进健康和实践的创新方面仍有很大的希望。其中包括对数据的实时或近实时访问;使用基于访谈的客观数据衍生测量方法;增加数据的空间和时间维度的广度和/或分辨率;可扩展性和增加的人口样本量或集水区;以及得到现有数据流没有的度量。
5.1 新兴数据流和数据访问、偏差、隐私和安全
文章表明来自用户生成的NDS源的文本数据有需要注意的关键偏差。鉴于食源性病原体的潜伏期、食用食品的多样性和召回的不精确性,将食源性疾病归源于特定食品或消费地点是非常困难的。专有平台或网站可能为研究人员提供有限的数据访问,或仅以高成本访问。如果样本量不足或不平衡,这可能会导致样本有偏差,而且对于规模较小、预算较低的公共卫生机构来说,这可能是不可行的。在分析可在网络或公众上自由访问的数据时,通常存在有限的隐私或安全问题,例如在社交媒体平台上发布的自愿报告的潜在食源性疾病病例。一个共同的挑战是,在特定研究协议下共享的数据可能不会与公众或发表文章的期刊共享,从而妨碍验证或再现性研究。
5.2 机器学习在新型数据流数据分析中的缺陷和局限性
文章表示涉及文本数据的一个共同挑战是食源性疾病相关关键词缺乏特异性,例如恶心、或腹泻等词可用于许多疾病,导致高假阳性率;另外,一个相关的挑战是如何处理帖子中的俚语、讽刺和反讽。基于情感分析和模式识别的机器学习方法在这些问题上的应用前景广阔。文章回顾的许多方法需要机器学习与原则性的数学或预测性的机械建模相结合,后者将结构或逻辑引入到问题方法中。在许多情况下,不需要高级分析,但需要有效的信息技术系统来实时识别、捕获和吸收数据的技术,在疫情监测和应对环境中更为实用。文章表示尽管NDS和本文回顾的技术可以补充和/或补充现有的数据和分析技术,以应对食品安全挑战,但它们并不能取代调查工作。大多数应用尚未在预期应用中进行严格评估,以确保内部和外部验证并防止过度拟合。
5.3 展望与未来发展
文章表示机器学习在食品安全领域的许多应用还没有被发现,但可以仿效相关领域的应用。会员卡、餐厅销售和在线杂货店或配送数据集已用于消费者行为和营养应用,可用于识别可能爆发疫情的食品载体来源。可通过合并额外数据来改进预测任务,例如产品特定特征(保质期、可能的消费日期、特定产品含有特定病原体的可能性)或影响购买特定物品的因素(天气、假日或体育赛事),零售消费需求预测模型中常用的特征。累计信用卡交易已被用于开发消费者购物轨迹的机器学习模型,可用于确定购买受污染产品的地点(如市场、餐厅)。手机通话数据记录或智能手机应用程序记录的GPS定位数据在研究人与人之间传染病传播方面发现了许多应用,但迄今为止涉及食源性疾病的例子很少。在社交媒体和搜索查询上操作的方法可以从食源性疾病监测扩展到食品安全的其他领域,包括产品召回、过敏原或食品安全法规。
文章表明将NDS与原始食品安全数据库结合起来还有很多很有前途的机会。环境数据,包括天气报告或卫星图像,这是尚未提及的NDS来源,可以与农业数据相结合,预测农业中的食品安全事件或危害。跨数据源的整合,例如谷歌利用位置和网络搜索文本数据开发的算法,并训练餐厅检查数据,或基因组和供应数据之间的整合。从长远的角度来看,可以想象将这些数据源(NDS和原始食品安全数据库)结合在一起,形成大规模的端到端预测建模系统。
参考文献
Deng X, Cao S, Horn A L.Emerging Applications of Machine Learning in Food Safety[J].Annual Review of Food Science and Technology,2021, 12 (1): 513-538.
关注我们
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/ml-application-in-food.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
当今的机器学习策略可以减少人们对食物中纳米粒子的担忧
在《环境科学与技术》杂志在线发表的一项新研究中,德克萨斯 A&M 大学的研究人员使用机器学习来评估金属纳米粒子的显着特性,这些特性使它们更容易被植物吸收。研究人员表示,他们的算法可以表明植物在根和芽中积累了多少纳米颗粒。
-
基于质谱-机器学习技术的番茄分类:一个食品安全增强平台
今天介绍一篇由Arthur Noin de Oliveira等人于2022年8月发表在Food Chemistry(IF=9.231)上的文章。该研究旨在开发一个使用机器学习算法的平台,分析质谱数据,对番茄进行有机和非有机的分类。决策树算法被定制用于数据分析,该模型在确定每种水果属于哪个组时达到了92%的准确度、94%的灵敏度和90%的精确度。
-
Food Chem|衰减全反射-傅立叶变换红外光谱结合化学计量学快速检测椰子水掺假
该文研究了衰减全反射-傅立叶变换红外光谱(ATR-FTIR)与化学计量学相结合,作为一种快速检测椰子水中掺糖的方法。
-
中国农业大学周欣团队基于宏基因组学和机器学习的蜂蜜产品溯源
今天介绍一篇来自中国农业大学昆虫学系周欣教授课题组于2022年3月发表在Food Chemistry上的文章。该文为了查询蜂蜜的地理来源,收集蜂蜜样本产生的宏基因组数据,应用机器学习方法来推断蜂蜜的地理来源。
-
人工智能生产的烤牛肉风味
通过与微软的合作,芬美意香料公司能够利用其整个原材料数据库,找到各种成分的完美结合,从而产生“轻度烤牛肉”的味道。该产品代表了该行业的一个里程碑,因为他们声称这是有史以来第一款由人工智能(AI)创造的口味。
-
农业-食品系统中的人工智能:新冠肺炎情景下可持续商业模式的重新思考
今天给大家介绍一篇由Assunta Di Vaio等人近期发表在sustainability上的一篇综述型文章。文章目的是研究人工智能(AI)在农业食品行业中的作用,以及利益相关者在其供应链中的作用,特别是在考虑到COVID-19大流行等充满不确定性的经济场景下,他们间不同的作用。
-
海南大学姜珂副研究员:用于化学动力学/饥饿协同癌症治疗的智能异质结芬顿催化剂的开发
近日,海南大学姜珂副研究员与山东大学李春霞教授合作,采用构筑异质结的策略,联合葡萄糖氧化酶(GOx),揭示了芬顿/级联酶促反应的协同抗癌机制。相关成果以题为“Development of an Intelligent Heterojunction Fenton Catalyst for Chemodynamic/Starvation Synergistic Cancer Therapy”发表在国际学术期刊《Journal of Materials Science & Technology》(IF=10.319)。海南大学倪伟舒硕士、姜珂副研究员为该论文的共同第一作者,海南大学姜珂副研究员、张玲副教授和山东大学李春霞教授为该论文的通讯作者。
-
FRONT NUTR:通过化学信息学方法从蓝莓中计算筛选抗阿尔茨海默病的新神经保护成分
今天介绍一篇由中南林业科技大学张琳教授团队发表的一篇研究性论文,由肖冉等人于2022年12月发表在国际营养学TOP期刊Frontiers in Nutrition上(JCR:Q1 IF:6.59)。本文尝试设计一种基于化学信息学方法这种有效的智能筛选模式,从蓝莓中寻找抗阿尔茨海默病(AD)的新型有效成分,并通过实验验证了预期成分的生物活性。该方法集成了先进的人工智能和化学信息学方法,实现了对所有成分的逐步分析和过滤。最后,获得了预期的新化合物氯化锦葵色素-3-O-半乳糖苷(Ma-3-gal-Cl)。这篇文章采用的创新性方法为。这项工作采用的筛选策略能够为研究者从天然产物和食物中筛选活性成分提供新的参考。
-
【佳作速递】北京工商大学宋焕禄课题组:基于感官组学表征亳州白芷煮沸前后的关键香气活性化合物
本研究旨在通过分子感官方法研究煮沸对亳白芷风味的影响,共鉴定和分析了55种挥发性化合物(VOCs)和38种香气活性化合物。亳白芷中的关键香气活性化合物是α-gurjunene、prenol和α-copaene,芳樟醇和(E)-2-壬烯醛是亳白芷煮液中主要的关键香气活性化合物。