今天介绍一篇不久前由巴西戈亚斯联邦大学的Nattane Luíza da Costa发表于Artificial Intelligence in Agriculture的一篇文章。文中使用支持向量机(SVM)结合两种特征选择方法对南美洲4种葡萄酒进行分类,根据挥发物、半挥发物和酚类化合物的组成对收集的 83 个样品进行了分析。识别出九种化学品定义的变量子集对葡萄酒样品进行分类的性能最优,其准确率达93.97%。
摘要
今天介绍一篇不久前由巴西戈亚斯联邦大学的Nattane Luíza da Costa发表于Artificial Intelligence in Agriculture的一篇文章。文中使用支持向量机(SVM)结合两种特征选择方法对南美洲4种葡萄酒进行分类,根据挥发物、半挥发物和酚类化合物的组成对收集的 83 个样品进行了分析。识别出九种化学品定义的变量子集对葡萄酒样品进行分类的性能最优,其准确率达93.97%。
1. 介绍
仪器分析与机器学习相结合,可以根据地理来源、品种和农业系统类型(传统或有机)成功地对各种产品和食品进行分类。辨别食品的主要原因是质量控制和认证,以避免不公平竞争造成市场不稳定,扰乱区域经济甚至国民经济。葡萄酒是一种容易掺假的产品,根据品种和地区对葡萄酒进行分类是一个重要问题。诸如高效液相色谱 (HPLC)、耦合质谱检测 (MS)、傅立叶变换红外 (FTIR) 等分析技术能够用化学化合物描述葡萄酒,从而揭示有关每种葡萄酒身份的有用信息。
已有对南美葡萄酒的地理来源和品种进行分类的研究主要通过使用主成分分析 (PCA) 和线性判别分析 (LDA)。线性方法易于理解且足以获得较好的结果。然而对于一些非线性的复杂数据,判别分析等经典线性方法无法对其进行建模,需要非线性方法。支持向量机 (SVM) 是最流行和最复杂的机器学习技术之一,已成功用于许多不同的领域,例如:食品科学、医学、法医学等。
在之前的研究中,使用特征选择和支持向量机基于其抗氧化活性、酚类物质、花青素和颜色,通过机器学习对葡萄酒进行了分析。特征选择的使用能识别表征葡萄酒地理起源的最重要的化学描述符。诸如可以对通过特征选择方法获得的食物样本进行分类的简化化学描述符集之类的信息可以降低与不相关化合物的化学分析相关的成本,减少分析数据所需的计算时间,可以提高准确性并提供有用的信息,以预防和识别食品欺诈。
研究的目的是基于支持向量机 (SVM),并结合基于相关的特征选择 (CFS) 和随机森林重要性 (RFI)的特征选择方法,表征能够区分南美葡萄酒的四种“商业类别”: “Argentinean Malbec (AM)”、“Brazilian Merlot (BM)”、“Uruguayan Tannat (UT)”和“Chilean Carménère (CC)” 的主要酚类、半挥发性和挥发性化合物。
2.材料及方法
葡萄酒样品由葡萄酒专家从当地商店购买2008-2015年,每瓶 750 mL的价格从 12 美元到 135 美元不等的83 款葡萄酒,包括14 UT、26 MA、33 CC 和 10 BM。开瓶后即刻将酒分装并于-80 °C存放。使用仪器分析方法对半挥发性化合物、挥发物、酚类化合物和抗氧化活性进行分析。发现的化合物分布如下:21 种酚类成分、29 种挥发物和 140 种半挥发物。
支持向量机是最著名和最常用的分类算法之一,旨在找到具有最大边距的超平面来分离数据类别。在线性情况下,具有两类数据的数据库很容易被超平面分成两组。当没有线性决策边界时,原始数据集 (x) 被核函数转换为新的空间 f(x)。 在新的空间 f(x) 中,有一个线性决策边界将样本分类。特征选择(变量消除)有助于理解数据、减少高维的影响、减少计算时间并提高分类器性能。使用基于相关性的特征选择 (CFS) 来选择最重要变量的子集,并使用随机森林重要性 (RFI) 对所选变量进行排序。使用10倍交叉验证来评估支持向量机的性能。所有机器学习任务和图表均使用R软件执行。
3. 结果
Fig. 1显示了本研究中执行的步骤。选择葡萄酒后,根据酚类、挥发物和半挥发物的成分对其进行分析。从600个峰中选择了能够识别分子式的峰(169个峰)。数据集有83个样本(26个AM样本、10个BM样本、33个CC样本和14个UT样本),描述了169个挥发性和半挥发性化合物峰,另外还有21个与抗氧化活性和酚类化合物相关的变量。

Fig. 1研究路线。
3.1. 全数据集的分类和分析
分类算法SVM首先考虑了最初的190个变量(169个挥发性和半挥发性化合物峰和21个与抗氧化活性和酚类化合物相关的变量)作为参考。使用190个变量的SVM模型获得了39.76%的准确率。所有样本均被归类为CC。该模型中获得的精度值由CC样本数解释。数据库中有33个CC样本,所有样本均归类为CC。只有33个CC样本分类正确,占总样本的39.76%。
通过主成分分析(PCA)进行探索性分析,将特征数量从190个原始变量减少到两个主成分(Fig. 2)。类别之间没有自然的分离。可以确定三个集群,但是,每个集群都由所有类的样本组成。可见所有酚类和挥发性化合物不能区分四种葡萄酒。考虑到数据集中可能存在噪声或无关变量,可以解释低分类率的原因。因此,应用特征选择方法从输入中选择一个变量子集,它可以有效地描述输入数据并区分类别。
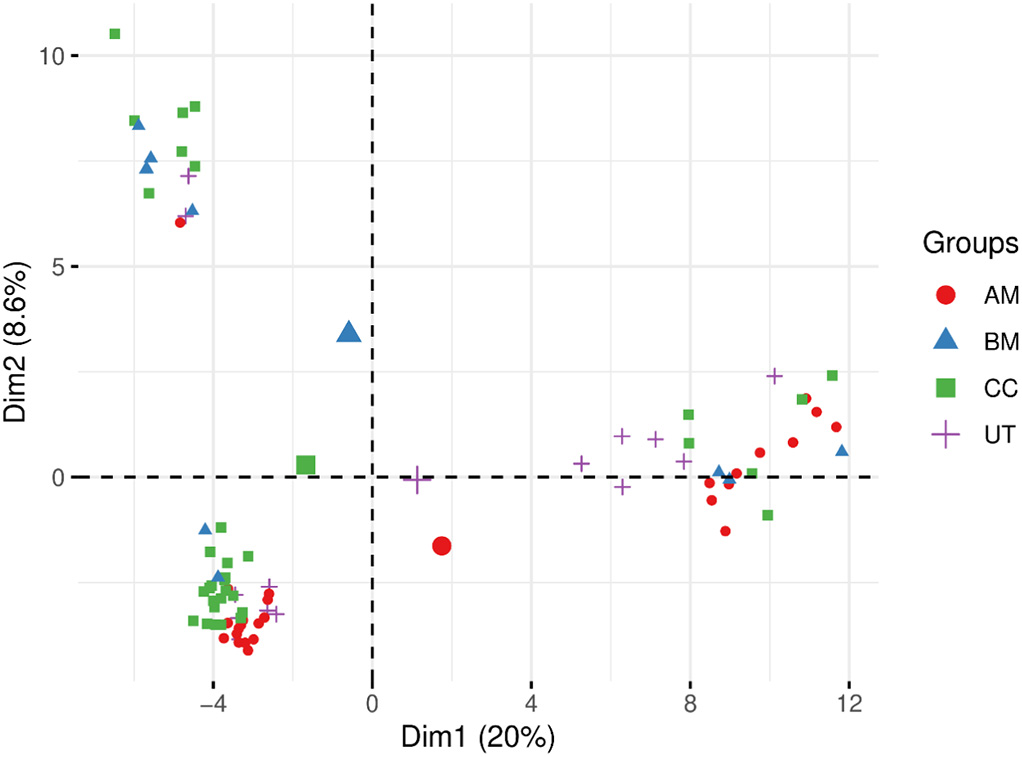
Fig. 2全数据集的 PCA 得分图。
3.2. 特征选择
CFS对全数据集进行CFS,返回13个变量。对四种葡萄酒变量浓度数据进行了描述性统计分析。发现四种葡萄酒中变量浓度的统计差异没有规律。需要进一步分析,以根据该化学成分区分类别。对所选变量进行PCA分析。Fig. 3显示了前两个主成分的得分图。可以观察到BM和CC之间的自然分离。AM和UT的样本与BM和CC分离,但这些类别之间存在重叠。在分析样本之间的距离时,CFS选择的变量比所有酚类和挥发性化合物显示出更强的辨别力。CFS返回的13个变量被提交到特征选择的过滤方法RFI。Fig. 4显示了根据RFI的每个变量的重要性。
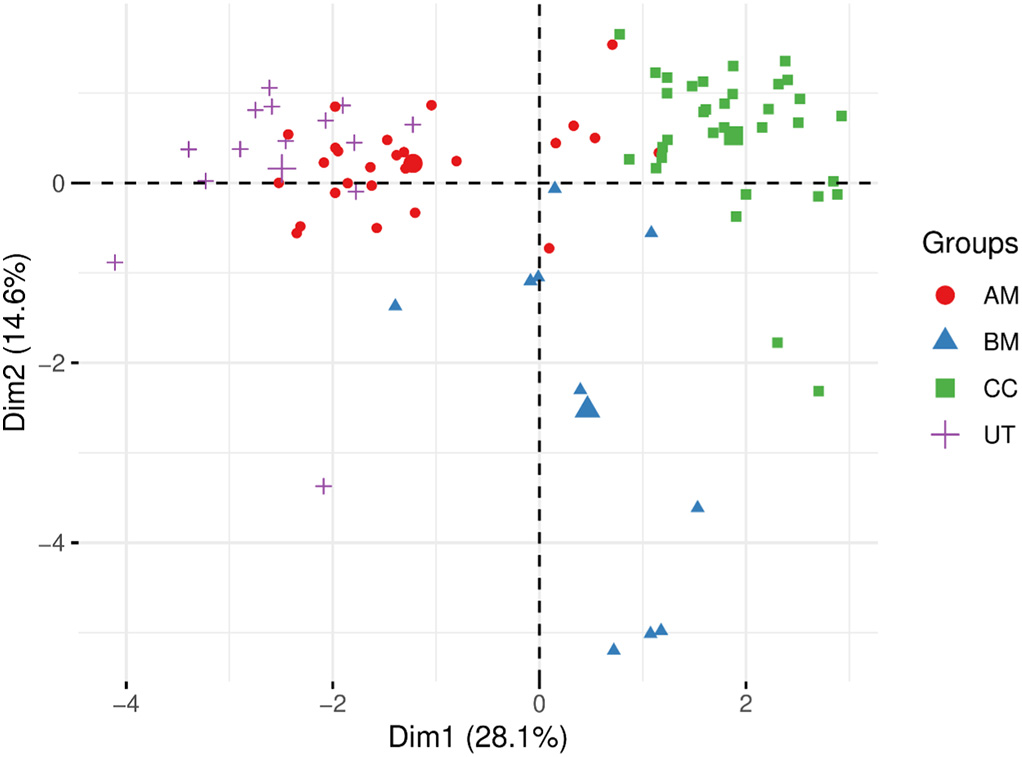
Fig. 3 CFS 选择的13个变量的 PCA 得分图。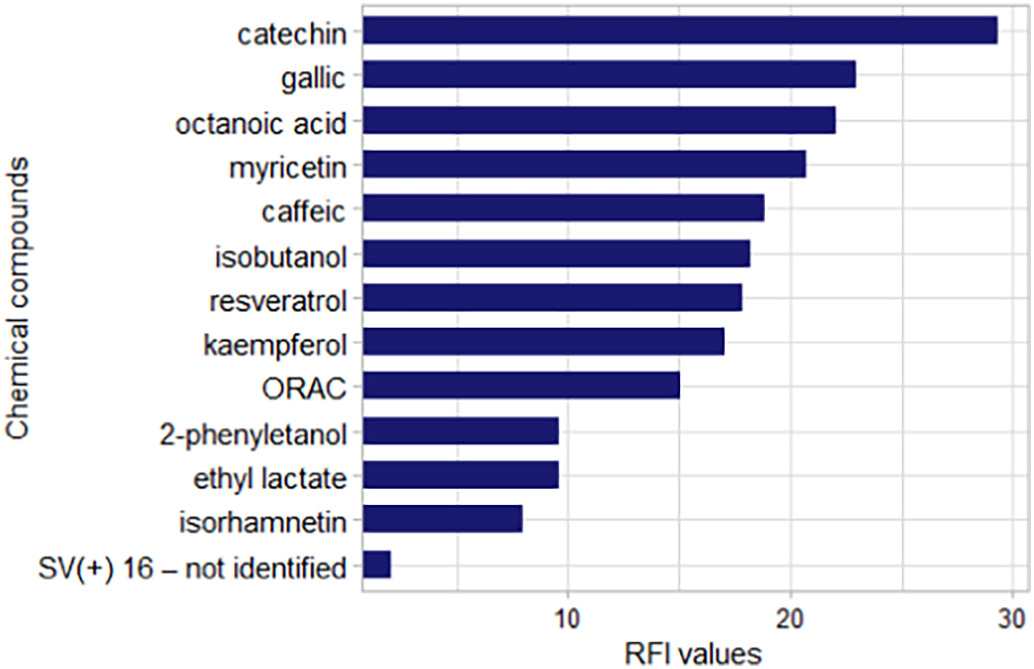
Fig. 4 CFS 根据 RFI 选择的化合物的重要性排名。
3.3. 分类结果
根据RFI,执行了13个分类模型,按重要度顺序递减添加变量,第十三个分类模型使用CFS选择的十三个变量。Table 1显示了从这13个分类模型中获得的结果。较高的结果是#09分类模型,准确率为93.97%。由表可见,当添加变量时,这些值会增加。准确度的峰值出现在#09分类模型中。当添加更多变量时,该值会减小并在一个值范围内稳定。
Table 1 使用与特征选择相关联的 SVM 进行分类的结果。
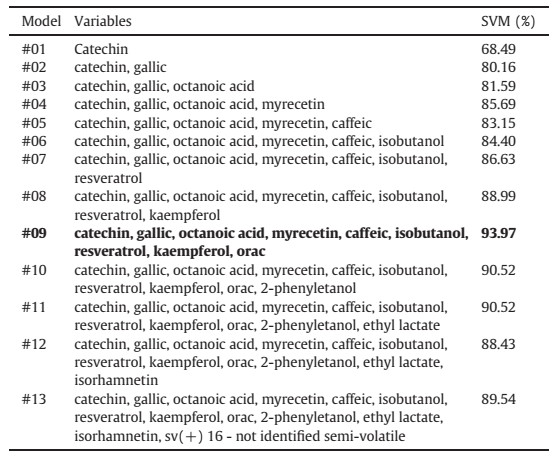
Table 2显示了分类模型#09的混淆矩阵。CC类的所有样本均正确分类。一个BM类样本、两个AM类样本和两个UT类样本被错误分类。这些结果表明,CC类是其中最纯净的,其中子集#09的九种化学成分能够正确分类所有样本。其他数据类有少数被错误分类的样本,这表明其他商业类别之间有一些相似之处。然而,该分类模型取得了93.97%的分类率。
Table 2 分类模型#09的混淆矩阵。

4. 结论
这项工作展示了使用支持向量机和两种特征选择方法对南美红葡萄酒的四个商业类别进行分类(“Argentinean Malbec (AM)”、“Brazilian Merlot (BM)”、“Uruguayan Tannat (UT)”和“Chilean Carménère (CC)”)。在190个描述挥发物、半挥发物、抗氧化活性和酚类化合物的变量中,CFS选择了13个。根据该变量子集,RFI识别了九种化学品,其分类能力大于13个变量集。支持向量机能够根据样本的类别对样本进行分类,准确率为93.97%。所选化合物为儿茶素、没食子酸、辛酸、杨梅素、咖啡酸、异丁醇、白藜芦醇、山奈酚和ORAC。特征子集的选择对南美葡萄酒的商业分类起着重要作用。使用特征选择技术来识别能够对来自多个来源的数据进行分类的化合物子集,此方法可以应用于其他产品和葡萄酒,以确定最重要的化学物质,这些化学物质具有类别特征,减少数据维数,并提高分类率。
虽然变量选择器的使用提高了分类模型的性能并降低了实验成本,但在葡萄酒分类领域,很少有使用这些技术的研究。食品认证的未来取决于将不同分析技术的信息与能够处理非线性数据和复杂问题的建模算法相结合,如人工神经网络、支持向量机、决策树和随机森林,与传统方法相比,这显示出巨大的潜力和更多的优势。
参考文献
- Nattane Luíza da Costa, Leonardo A. Valentin, Inar Alves Castro, Rommel Melgaço Barbosa, 2021. Predictive modeling for wine authenticity using a machine learning approach. Artificial Intelligence in Agriculture 5, 157-162.

扫码关注我们
微信号|FoodAI
合作/投稿|biomed@csu.edu.cn
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/red-wine-ml.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
机器学习揭示食品-药品和辅料-药品相互作用
今天介绍一篇由麻省理工David H. Koch整合癌症研究所、MIT-IBM Watson AI实验室、机械工程学院和哈佛医学院附属布莱根妇女医院数据,于2020年3月发表在Cell Reports上的一篇实验型文章。文章应用了机器学习的方法对GRAS和IIG化合物的未知生物活性进行了研究。研究发现维生素A棕榈酸酯和松香酸分别是P-糖蛋白和UGT2B7的抑制剂,并通过一系列的实验进行了验证确认。他们的模型可以预测常见食用化学物质的生物学效应,并对食品-药品和辅料-药品相互作用以及功能性药物制剂的开发产生了新的影响。
-
FOOD CONTROL|长江大学谷惠文/尹小丽: 基于二维指纹图谱和化学计量学的茶叶产地识别及标志物筛选
该研究首次提出运用高效液相色谱-二极管阵列检测器采集样本的二维指纹图谱(2D HPLC-DAD)用于中国绿茶的原产地识别。通过多元曲线分辨-交替最小二乘算法(MCR-ALS)盲分辨提取了绿茶样本的62种化学成分,并对其进行不同尺度化(UV和Par)下的主成分分析(PCA)和正交偏最小二乘-判别分析(OPLS-DA)。结果表明,浙江、山东两产地茶叶样本具有明显的聚类趋势。最终筛选出17个特征成分可作为区分浙江茶和山东茶的化学标志物,识别准确率达92.86%。
-
基于二维相关光谱与卷积神经网络的食用油产地溯源与掺假分析
今向大家介绍一篇来自武汉轻工大学的刘言等人在SPECTROCHIM ACTA A上发表的一篇论文。该研究基于食用油的二维相关光谱并设计卷积神经网络(CNN)对食用油的同步相关谱和异步相关谱进行分析。用一组不同产地的芝麻油和另一组掺有其他植物油的橄榄油对该方法进行了评价。两个数据集的预测准确率分别为97.3%和88.5%。
-
农业-食品系统中的人工智能:新冠肺炎情景下可持续商业模式的重新思考
今天给大家介绍一篇由Assunta Di Vaio等人近期发表在sustainability上的一篇综述型文章。文章目的是研究人工智能(AI)在农业食品行业中的作用,以及利益相关者在其供应链中的作用,特别是在考虑到COVID-19大流行等充满不确定性的经济场景下,他们间不同的作用。
-
基于机器学习的模式识别技术鉴别掺假油和食用油混合物
今天给大家介绍一篇由Kevin Lim等人近期发表在Nature Communications上的一篇研究型文章。文章提出了一种机器学习方法来发现脂肪酸的特定组成,以区分十种不同的植物油类型及其内部的变化。作者还描述了一种有监督的端到端学习方法,该方法可以推广到任何给定混合物的油组成。
-
中国科学院蒋长龙团队:基于集成纸基传感器的便携式智能手机的无酶和快速视觉定量检测农药残留
今天介绍一篇由Qianru Zhang、蒋长龙等于2022年6月发表在Journal of Hazardous Materials上的一篇论文。该研究构建了一个简单、快速、可视化的无酶辅助的草甘膦(Gly)荧光定量检测平台。并且在设计的智能手机平台的辅助下制备了荧光试纸条,显示出作为便携式光学分析终端的潜力,用于定量跟踪真实样品中的Gly。该传感平台为Gly的定量检测提供了可靠的方法,可推广到分析科学领域的其他分析物或污染物筛选。
-
利用PredRet中的数据准确预测保留时间并应用于食品生物活性成分分析
今天介绍一篇法国克莱蒙费朗大学前段时间发表在food chemistry上的一篇文章。该研究在24个色谱系统分析的467种化合物种测试了PredRet预测植物食品生物活性成分在色谱柱中保留时间的表现。
-
肠道菌群分析和机器学习算法揭示精准营养在干预代谢综合征中的作用
2021年7月30日,介绍一篇由中国科学院上海营养与健康研究所陈雁研究组和林旭研究组在国际学术期刊Molecular Nutrition & Food Research发表的研究论文。该文揭示了肠道菌群在指导精准营养干预改善代谢综合征中的重要作用。
-
湖南大学吴海龙课题组:高效液相色谱指纹图谱结合化学计量学的白术有效成分分析及产地鉴别研究
该研究提出运用高效液相色谱-二极管阵列检测器(HPLC-DAD)结合化学计量学方法快速分析不同地区白术中12种活性成分含量并进行产地判别。首先,使用HPLC-DAD结合二阶校正算法(ATLD)对来自不同地区的白术中12种活性成分同时进行定性定量分析。利用“二阶优势”,12种化合物不仅在12.5 min内快速洗脱,而且还在色谱峰高度重叠的情况下实现了准确定性定量(平均回收率为80.8–109.9%),一系列品质因子参数均反映出所提方法的可行性。基于ATLD解析所得的12种活性成分和31种未校正成分的相对浓度值,使用偏最小二乘-判别分析法(PLS-DA)对不同地理来源的白术样本进行判别分析,三个地区的白术都有明显的聚类趋势,测试集的正确分类率可达90%。变量重要性投影(VIP)分析结果表明,紫丁香酚苷、白术内酯Ⅲ、白术内酯Ⅰ和苍术酮可作为白术产地判别的主要标志成分。一系列结果均证明了所建立模型的可靠性。该方法的建立有助于白术的临床使用和市场监管。
-
中国人民公安大学侦查学院姜红课题组:基于拉曼光谱和机器学习算法的沙门氏菌快速鉴定
本研究针对三种最具致病性的沙门氏菌血清型,使用拉曼光谱获取其光谱数据,选择适合解决多分类问题的卷积神经网络(CNN)对拉曼光谱数据进行深入挖掘和分析。比较了五种光谱预处理方法,Savitzky-Golay平滑(SG),多元散射校正(MSC),标准正态变量(SNV)和希尔伯特变换(HT)对CNN模型预测能力的影响。采用准确度(ACC)、精度、召回率和F1得分 4种机器学习评价指标来评估不同预处理方法下的模型性能。