今天介绍一篇前段时间由意大利国际农业发展基金研究与影响评估司,英国牛津大学技能,知识与组织绩效中心,英国曼彻斯特大学教育与环境与发展学院等多学科机构联合开展的一项关于使用机器学习方法替换传统基于卡路里的食品安全指标的应用进展。
1 介绍
尽管在过去的三十年中全球获得粮食的机会有所增加,但低收入国家中仍有很大一部分人口继续遭受饥饿和营养不良的困扰(粮农组织,2014年)。在孟加拉国这样的发展中国家尤其如此,尽管该国的稻米产量翻了三倍,但仍有数百万家庭因粮食价格上涨,自然灾害和其他不利事件而易受粮食不安全的影响。因此,解决粮食不安全,贫困或脆弱性的社会安全网计划的有效性,关键取决于确定目标家庭的明确框架。即使在围绕贫困测度达成共识的情况下(例如,明确定义的国家贫困线),贫困的普遍程度和粮食不安全状况也不会总是重叠。因此,针对穷人的粮食分配计划可能会对粮食不安全的家庭造成惩罚。根据粮食安全状况对家庭进行准确分类还可以使弱势群体得到更好的定位,并改善对公共政策干预措施的评估。
在食品安全性分析中,卡路里摄入被认为是“黄金标准”措施。但是,使用食物召回模块或食物日记来测量卡路里摄入量既费时,又有报告偏差的困扰,并且管理成本很高。在时间和成本是重要考虑因素的情况下,使用卡路里摄入量识别粮食不安全的家庭可能不是正确的方法。因此,重要的是要评估是否存在其他指标,这些指标收集起来相对便宜,但在预测粮食不安全时可以充分替代卡路里的摄入。此外,应使用尽可能最佳的预测方法评估替代指标的绩效。特别是,机器学习(ML)的最新发展可能会胜过传统的估计方法,从而减少程序目标中的排除和包含错误。
在这项研究中,作者测试了不同变量组合在使用ML方法预测基于卡路里的食品安全措施中的能力。作者首先使用基准预测变量集来预测基于卡路里的指标,该基准预测变量集包括在数据收集方面花费很少精力的家庭级别变量,例如,户主的特征,基础设施访问权和资产持有量(以下称为基准变量集)。然后,作者通过向模型中添加两个不同的预测变量集(一次并组合一个)来估计预测准确性的边际收益。第一组是“主观”预测变量集,其中包括三个自我报告的粮食短缺指标。第二组是基于饮食多样性(即食用的食物类别数量),其中包括妇女的饮食多样性得分(WDDS)或成年女性,其他成员两岁以上饮食多样性得分(ODDS)所消费的食物类别数量)或成年女性以外的成员所消费的食物类别数量,家庭饮食多样性评分(HDDS)和食物消费评分(FCS),即根据营养价值对食物进行加权的饮食多样性版本。作者将此集称为DDS集。最后,作者估计将主观和DDS集添加到基准集的边际收益。除了评估不同的指标集外,作者还测试了ML和非ML方法在预测基于卡路里的食品安全性方面的相对性能。作者的机器学习方法是随机森林(RF)和极端梯度提升(XGBoost)算法,而作者的非机器学习方法则将普通最小二乘(OLS)或逻辑回归与样本外预测算法(非机器学习方法)结合使用)。作者在家庭和社区一级进行分析,以便在预测不同聚集水平的粮食安全时比较不同方法的效果。
研究背景是孟加拉国,政府在确保粮食安全方面高度重视,将近2.2%的国内生产总值分配给安全网和社会保护计划。作者的数据包括全国代表性的6,427户农村样本。作为国际食品政策研究所(IFPRI)管理的2015年孟加拉国综合家庭调查(BIHS)的一部分,对这些家庭进行了采访。作者预测了两个基于卡路里的指标:(1)一个家庭的每日卡路里摄入量是否低于每个成年男性当量(AME)(以下称低热量)所要求的卡路里摄入水平,以及(2)人均卡路里摄入量(以下简称卡路里摄入量)。作者使用RF和XGBoost来预测家庭低卡路里状态和卡路里摄入水平。为了比较在将其他预测变量添加到基准集中时获得的预测的边际收益,作者估算了卡路里不足的预测的准确性,敏感性和特异性。1个对于卡路里摄入,作者通过比较预测误差平方和的平方根除以目标变量的标准偏差(即归一化均方根误差(NRMSE))来评估预测准确性。作者还使用RF方法的重要性可变功能来识别卡路里指标最重要的预测指标。
将DDS集添加到基准集后,作者发现正确地将家庭分为低卡路里或低卡路里的家庭的总体准确性从63%上升到69%,而相对于卡路里摄入量的NRMSE从0.93略微提高到0.89。将主观指标添加到基准集时获得的预测准确性的边际收益可忽略不计。在预测家庭中的卡路里贫困时,基准设置分别占RF和XGBoost方法总预测准确度的91%和94%。尽管基准集很重要,但根据RF产生的重要性权重,作者发现FCS和HDDS是卡路里指标的五个最重要的预测指标中的两个。相反,没有任何主观指标特别重要。预测模型。在非ML方法的情况下,主观和DDS集都可以提高预测准确性,但基准集再次占预测总准确性的90%。
虽然某些粮食安全干预措施可能覆盖一个国家的所有地区,但在其他情况下,实施者可能被迫限制干预措施的地理范围。因此,任何家庭层面的目标定位的重要初始阶段都是在总体层面(例如,社区或区域层面)进行类似的目标定位。为了更全面地比较作者的预测变量集和方法的性能,作者使用社区级别的可观察特征,DDS和主观粮食安全指标,也从社区级别的数据中预测了社区级别的卡路里摄入量级别数据。作者发现,DDS集和主观集都无法显着提高卡路里指标的预测准确性。
作者的研究对有关粮食安全测量和目标的文献进行了补充和补充,为文献提供了新的证据。作者表明,由易于观察的信息组成的一组预测因素在预测基于卡路里的粮食安全指标方面几乎与难以收集的信息(如主观粮食安全和饮食多样性)一样好。正确将家庭归类为低卡路里或不低卡路里的基准设置的准确性为63%至64%。但是,作者的基准集是否应被视为“金标准”卡路里指标的适当替代,将取决于具体情况。政策制定者将不得不权衡相对较低的收集成本和基准设定速度与基于卡路里的指标的准确性。
其次,虽然有几项研究评估了DDS,自我报告的粮食安全以及其他替代指标是否可以准确预测粮食安全,但很少进行比较分析。重要的是,在许多研究中,比较都是基于相关指数,列联表或OLS回归。其他研究比较了粮食安全的其他指标,却没有考虑基于卡路里的指标的预测准确性。相比之下,当比较复杂的ML和非ML方法时,作者比较了不同预测变量集的性能,并评估了卡路里指标的预测准确性。
最后,作者为有关使用ML方法测量贫困程度的新兴文献做出了贡献。先前的例子包括使用卫星数据预测当地的经济成果和使用当地天气条件预测农作物的产量。一些研究使用大数据来预测各种结果,例如,使用手机数据的个人财富,使用手机和卫星数据的贫困以及大宗收入使用Google街景视图中的图像。在粮食安全文献中,Knippenberg等人。(2018)运用机器学习方法找到马拉维未来粮食不安全的预测因素。他们表明,以前的粮食不安全状况,生活在洪泛区和距饮用水的距离是未来粮食不安全状况的重要预测指标。在作者的研究中,作者使用ML方法来检验作者是否仅使用基本的可观察因素就可以准确地预测食品安全,以及其他食品安全指标在预测卡路里指标方面的边际贡献是什么。
2. 主要结果
2.1 卡路里指标的预测
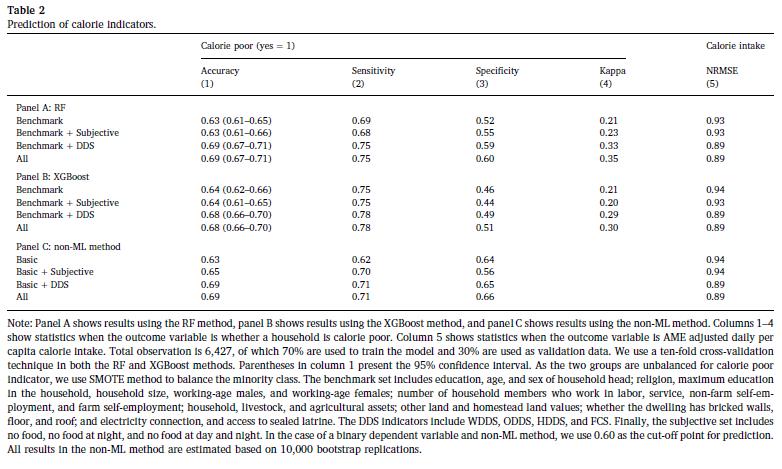
表2 A面板使用RF方法报告预测结果。第1-4列显示了将低卡路里作为目标变量的准确性,敏感性,特异性和Kappa估计量。作者发现,将DDS设置为基准设置后,预测的总体准确性从63%上升至69%。敏感性指标从69%增加到75%,而特异性指标从52%增加到60%。包含主观集合不会严重影响任何这些指标。加上DDS集,Kappa估算值也从21点增加到33点。在面板B中,作者显示了使用XGBoost方法获得的结果与RF相似。总体准确性从64%上升到68%,而灵敏度,特异性和Kappa分别从75%上升到78%,46%上升到49%和0.21到0.29。使用XDSoset时,使用DDS集获得的预测精度的边际增益不如使用RF方法大。但是,无论ML方法如何,DDS集仍然优于主观集。

2.2 哪些个体特征最能预测卡路里摄入?
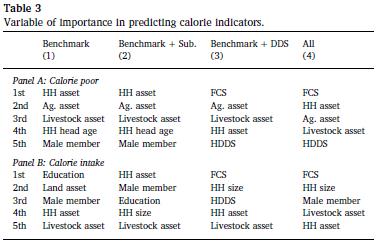
表3中的面板A列出了使用RF重要权重估算的预测家庭卡路里贫乏状况的五个最重要的变量。仅使用基准集时,作者发现最重要的变量是家庭人数,农业和畜牧资产,户主年龄和男性成员的存在。当将主观集添加到基准集时,作者发现没有任何主观指标属于五个最重要的预测变量。然后,作者将DDS集添加到基准集中,发现FCS和HDDS是五个最重要的预测变量中的两个。最后,作者将主观和DDS集都添加到基准集中,发现FCS和HDDS仍然是预测卡路里缺乏状态的重要变量。
在表3的B面板中,作者将卡路里摄入的五个最重要变量列为目标变量。作者发现土地,牲畜和家庭资产,教育水平以及男性成员的存在是最重要的预测指标。像卡路里不足的情况一样,主观指标在预测卡路里摄入量中都不重要。但是,将DDS集添加到基准集后,作者发现FCS和HDDS是五个最重要的变量中的两个,包括家庭规模,家庭资产和牲畜资产。将主观和DDS集都添加到基准集时,作者发现FCS仍然是基准集之外唯一重要的预测变量。本节中的结果与上一节中的结果明显一致。主观设定对预测卡路里指标并不重要。
3. 机器学习(ML)与非ML方法
在本节中,作者测试相对于非ML方法,ML方法在预测卡路里指标方面是否表现更好以及在何种程度上表现更好。作者选择的非ML方法结合了传统的计量经济学样本外预测进行估计。作者根据因变量的性质,在训练样本(占总住户的70%)上应用常规的logistic或OLS回归模型,并估算验证样本(其余30%的住户)的准确性,敏感性和特异性统计数据。作者将整个过程进行10,000次引导,并在目标变量为卡路里不足时估计平均预测的准确性,敏感性和特异性,而在目标变量为卡路里摄入时估计为NRMSE。对于低卡路里的人,作者以0.60为分界点,将家庭分为低卡路里和低卡路里。像ML方法一样,作者从基准集开始,然后依次包含主观和DDS集。
结果列于表2的C栏中。作者发现,非ML方法的总体准确度在64%到71%之间,这与作者在ML方法中观察到的相似。与ML方法一样,作者发现DDS集的包含可以提高预测准确性。此外,通过包含主观和DDS设置,灵敏度会大大提高。与ML方法相反,作者发现预测的特异性随着主观和DDS集的增加而下降。对于卡路里摄入量,作者发现在包含DDS设置的情况下,NRMSE从0.94降至0.89,这再次类似于ML方法。ML与非ML方法的比较产生了两个重要点。首先,这两种方法在预测整体准确性方面的表现非常相似。其次,与ML方法的情况不同,主观集像DDS集一样可以改善预测。
作者使用样本中低卡路里家庭的平均比例作为临界点。显然,较小的分界点会提高预测的敏感性(换句话说,降低排除错误的可能性),但可能会降低预测的特异性(增加包含错误的可能性)。在表A2中,作者表明,当作者将临界点相对于0.60降低到0.50或0.40时,预测的敏感性以特异性为代价而增加。因此,最终的截止点将取决于相应程序的覆盖范围。
4. 社区等级的定位
任何家庭级定位的重要初始阶段都是在总体级(例如,社区或区域级)进行类似定位。由于预算限制,政府或非政府组织首先需要确定大多数粮食不安全的地区或社区,然后再确定每个地区或社区中的大多数粮食不安全的家庭。在本节中,作者使用也在社区级别测量的预测变量集来预测社区级别(即村庄)的卡路里指标。在社区级别的基准设置中,作者包括社区中的总家庭,以女性为户主的家庭比例,平均教育水平和资产水平,基础设施以及获得信贷和卫生设施相关指标的机会。作者通过获取家庭水平观察值的平均值来估计社区一级的DDS和主观集。社区一级分析的目标变量是贫困家庭的卡路里比例和社区中平均卡路里摄入量。请注意,本节中的两个目标变量都是连续变量。因此,作者将仅使用NRMSE来估计通过不同预测变量集进行的卡路里指标预测中的边际收益。像家庭水平分析一样,作者使用RF,XGBoost和非ML方法进行预测。在作者的数据中,作者总共有323个社区。作者使用社区样本的70%作为训练样本,其余30%作为验证样本。
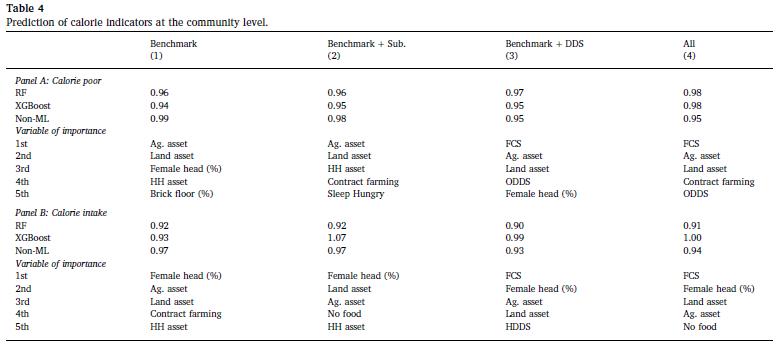
表4中的面板A显示了结果,其中目标变量是社区中卡路里贫困家庭的比例。在RF方法的情况下,作者发现仅使用基准集时NRMSE为0.96,但是在包含主观和DDS集的情况下,NRMSE升至0.98。对于XGBoost方法,作者再次发现仅使用基准集时NRMSE最低,而将主观和DDS集都添加到基准集时NRMSE最高。但是,作者发现当将DDS集包含到非ML方法的基准集中时,NRMSE下降。
表4中的B板显示了结果,其中目标变量是社区中卡路里摄入的平均水平。当将基准集与RF方法结合使用时,作者发现NRMSE为0.92。当作者将主观DDS以及这两个集合与基准集合一起包括在内时,NRMSE分别为0.92、0.90和0.91。另一方面,XGBoost方法表明,当作者仅使用基准集作为卡路里摄入量的预测指标时,NRMSE最低。非ML方法沿用了NRMSE的RF方法,其中包括将DDS设置为基准设置。
从使用RF方法的重要变量列表中,作者发现家庭,农业和畜牧资产,女户主家庭的百分比以及家庭基础设施是最重要的变量。当作者将主观和DDS集都包含到基准集中时,FCS和ODDS仍然是两个重要变量。当目标变量是社区中卡路里摄入量的平均水平时,作者会发现一组类似的重要变量。作者发现,当将主观和DDS集合都包含到基准集合中时,FCS和无食物(主观指标之一)仍然是两个重要变量。
在图A3,图A4,图A5,图A6中,作者从基准集开始显示了不同预测变量集的原始和预测的卡路里贫困家庭比例的分布以及社区中卡路里摄入的平均水平包含所有预测变量的集合。在图A7中,图A8,作者通过RF和XGBoost方法显示了对卡路里贫困家庭的社区水平比例的不正确预测的百分比。从社区级别的分析来看,作者没有发现包含主观和DDS集的预测准确性有明显提高。但是,正如作者在家庭层面的分析中一样,作者发现DDS设置仍比基准设置有一些正的边际收益。
上述插图请参见原文,篇幅有限,只放图A7。
5. 结论
在本文中,作者重新探讨衡量粮食安全的问题。具体来说,作者测试替代预测变量集的性能,这些预测变量集作为基于卡路里的指标的代理收集起来相对便宜。作者使用来自孟加拉国的具有全国代表性的数据集,并比较了三个备选预测变量集。基准集包括易于收集和量化的家庭水平变量。然后,作者依次将一个主观集和一个DDS集添加到基准集,并测试卡路里指标预测的改进程度。
研究发现,将主观和DDS集添加到基准集后,相对于低卡路里状态的总体预测准确性从63%上升到69%。作者还发现,与主观指标相比,DDS指标在预测家庭的卡路里状况方面相对更为重要。总体而言,作者的结果表明,添加DDS和主观集所带来的边际收益很小。作者还表明,通过适当的样本和正确的方法,非ML方法在总体准确性方面与ML方法相似,但会产生较大的排除误差。从社区级别的分析,作者显示,当仅包含基准集时,NRMSE保持最低。
本研究重要发现之一是,基准设置约占家庭卡路里指标总预测准确性的90%。因此,一个重要的问题是,为什么基准集如此强大?在什么情况下,我们希望主观和DDS集会增加预测能力?一种可能的解释是,主观和DDS集都与基准集中的预测变量相关,因此,主观和DDS集的边际贡献很小。一些较早的研究表明DDS(或主观)与家庭水平特征之间存在显着相关性。例如,DDS与社会经济特征和资产所有权有关。其他研究发现,CSI是主观食品安全指标的一种变体,与家庭资产密切相关。换句话说,相同的资产和家庭特征使一个家庭有可能负担足够的卡路里,这也使得该家庭更有可能购买多样化的饮食并避免食物不安全感。从这种角度来看,毫无疑问的是,使用基准集顶部的主观和DDS集可以使预测准确性的边际收益很小。但是,主观评估集具有捕获粮食安全的心理和季节性方面的优势(Coates等人,2007年),而DDS设置与家庭营养状况密切相关(Hatløy等人,2000年;Arimond and Ruel,2004年)。未来的工作可以评估主观评估和DDS评估的能力,不仅可以预测以卡路里为基础的粮食安全指标,而且可以预测微量营养素的摄入量以及粮食安全的详细心理指标。
这项工作发现,对于选择的ML和非ML方法,总体预测准确性介于60%到70%之间。根据所使用的方法,预测的敏感性(预测的卡路里差至真正的低卡路里家庭)的范围为70%–80%,而预测的特异性(预测的卡路里低至真卡路里的非贫困家庭)为50%–70%,具体取决于所使用的方法。分析中获得的准确性水平是否可以接受将取决于研究背景。通过收集详细的食物消耗数据获得的准确性的额外收益必须与相关的时间和金钱成本进行权衡。无论如何,鉴于在各种估算方法中对DDS和主观集都具有相似的预测性能,因此作者认为结果可以作为确定用于评估粮食安全的数据的宝贵指导。
此外,还发现ML和非ML方法在预测整体准确性方面的表现非常相似,其中非ML方法由OLS或逻辑回归组成结合样本外预测。乍一看,非机器学习方法与机器学习方法相当,似乎令人惊讶。OLS和逻辑回归作为预测工具的成功取决于条件线性函数对条件均值(对于连续结果)或优势比(对于二元分类问题)的接近程度。预测变量集只有很少量的协变量可供选择,并且几个预测变量都是二元变量,从而限制了模型复杂性的范围,并使简单的线性模型更有可能产生足够的近似值。有了更多的预测变量,我们可能会发现RF和XGBoost开始优于作者的非ML方法。
参考文献:
- Hossain M, Mullally C, Asadullah M N. Alternatives to calorie-based indicators of food security: An application of machine learning methods[J]. Food policy, 2019, 84: 77-91.
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/calorie.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
凉茶中农药及其转化产物的分析
今天介绍一篇来自国家环境保护新型污染物环境健康影响评价重点实验室卢大胜和汪国权等人于2022年2月发表在Food Chemistry(IF=7.514)上的文章。通过研究定位了来自中国两个主要产区的两种凉茶(菊花和冬青)中的农药和农药转化产品(PTPs), 揭示了凉茶中农药的概况,并为发现潜在的环境污染和食品污染物提供了新的视角。
-
机器学习技术协助矿物元素分析对中国不同地区的猪肉进行产地判别
今天介绍一篇由中国肉类食品综合研究中心的Jing Qi等人发表于Food Chemistry的一篇研究型文章。作者对中国七个地区的猪肉样品进行矿物元素分析,并引入机器学习方法,得到了一个高性能的产地可追溯性模型(前馈神经网络,95.71%的整体准确率和曲线下面积接近1),证明了通过矿物元素指纹分析可追溯一个国家内不同猪肉产地的可行性。
-
机器学习方法表征致肥胖城市的暴露组
今天分享一篇近期由荷兰阿姆斯特丹公共卫生研究所流行病学和数据科学系的Haykanush Ohanyan等人发表在Environment International上的文章。
-
基于牛奶营养分子数据集的婴幼儿配方奶粉人性化全息分析方法的建立与评价
今天介绍一篇来自东北农业大学食品科学系张英华,王玉堂课题组于2022年4月发表在Food Chemistry(IF=7.514)上的文章。文中通过研究编制的牛奶营养分子数据集,结合机器学习提出了一种识别婴儿配方奶粉人性化程度的新方法。
-
基于质谱-机器学习技术的番茄分类:一个食品安全增强平台
今天介绍一篇由Arthur Noin de Oliveira等人于2022年8月发表在Food Chemistry(IF=9.231)上的文章。该研究旨在开发一个使用机器学习算法的平台,分析质谱数据,对番茄进行有机和非有机的分类。决策树算法被定制用于数据分析,该模型在确定每种水果属于哪个组时达到了92%的准确度、94%的灵敏度和90%的精确度。
-
基于偏最小二乘和人工神经网络分析的采后苹果品质变化及保质期预测模型
今天介绍一篇由渤海大学食品科学与技术学院励建荣教授的研究组等人于2022年6月在线发表在Food Chemistry上的文章。本文构建了偏最小二乘法(PLS)和人工神经网络(ANN)模型来预测苹果的保质期。本工作旨在丰富苹果保鲜理论,为采后苹果货架期的快速评价提供参考。
-
基于比色条形码组合和深度卷积神经网络的便携式食品新鲜度预测平台
今天介绍一篇来自江南大学,于2020年底发表在Advanced Materials上的一篇论文。该研究将可交叉反应的比色条形码组合和深度卷积神经网络(DCNN)结合在一起,形成了一个用于监控肉类新鲜度的系统,总体准确性为98.5%。
-
使用可解释人工智能(XAI)技术解开送餐服务评论的深度学习模型
今天介绍一篇由悉尼科技大学土木与环境工程学院工程与信息技术学院高级建模和地理空间信息系统中心(CAMGIS)的Anirban Adak等人今年七月发表于Foods(IF: 5.561)的一篇文章。该研究通过比较食品配送服务(FDS)领域中的简单和混合深度学习(DL)技术(LSTM、Bi-LSTM、Bi-GRU-LSTM CNN)进行了情绪分析,并使用SHapley Additive exPlanations(SHAP)和Local Interpretable Model-Agnostic Explanations(LIME)解释了预测。DL模型在从ProductReview网站提取的客户评论数据集上进行了训练和测试。结果表明,LSTM、Bi-LSTM和Bi-GRU-LSTM-CNN模型的准确率分别为96.07%、95.85%和96.33%。LSTM模型相比其他两个DL模型实现了更低的假阴性率。可解释人工智能(XAI)技术,如SHAP和LIME,揭示了用于验证模型的单词对积极和消极情绪的特征贡献。
-
机器学习技术对食品销售预测的最新进展
本文回顾了用于预测食品销售的现有机器学习方法。讨论了从事食品销售预测的数据分析师的重要设计决策,例如销售数据的时间粒度,用于预测销售的输入变量以及销售输出变量的表示形式。同时回顾了已应用于食品销售预测的机器学习算法以及评估其准确性的适当措施。
-
HyperFoods:基于机器学习智能绘制食物中抗癌分子的图谱
今天给大家介绍一篇由Kirill Veselkov、Guadalupe Gonzalez等人合作,于前段时间发表在Scientific report的一篇文章。文章中作者介绍了一个独特的基于网络的机器学习平台HyperFoods,以识别推定的基于食物的抗癌分子。