今天介绍一篇最近由斯科普里大学计算机科学与工程学院Riste Stojanov等人发表在医学互联网研究杂志上的文章。文章研究了最近发布的基于Transformer的双向编码表示(BERT)模型,该模型在信息提取方面提供了最先进的结果,可以对食品信息提取进行微调。
摘要
今天介绍一篇最近由斯科普里大学计算机科学与工程学院Riste Stojanov等人发表在医学互联网研究杂志上的文章。文章研究了最近发布的基于Transformer的双向编码表示(BERT)模型,该模型在信息提取方面提供了最先进的结果,可以对食品信息提取进行微调。
1. 介绍
食物是影响人类健康的最重要的环境因素之一。综合各方面考虑,我们需要进行全面的饮食评估,以了解食物是如何影响人们的健康。相应食品实体的自动化检测对于食品相关的食品药物相互作用和健康问题等应用也非常重要。
计算机科学可以为这一研究课题做出巨大贡献,特别是在机器学习、自然语言处理(NLP)和数据分析领域。在研究中从各方来源收集的数据包含了重要的信息,对这些数据通过使用命名实体识别(NER)方法进行信息提取,该方法自动检测和识别代表领域实体的文本中的短语。
与生物医学领域相比,食品领域的资源相对不足。有一些语义模型(即本体),每一个都是为非常特定的应用程序开发的。Hanisch等人提出了一个基于规则的NER,称为drNER,用于从基于证据的饮食建议中提取信息。食品实体是被提取的感兴趣的领域实体之一。然而,drNER将几种食物实体作为一个整体进行提取。通过开发基于规则的NER食品信息提取,该规则将计算语言学信息与Hansard语料库的食品语义注释结合在一起。但上述NER依赖于其他外部资源,如分类法、本体或以前开发的注释器,如果某些资源变得不可访问,这就会成为一个问题。
2019年底,一个被称为FoodBase的带注释的食品语料库发布了。ground truth语料库由1000个食谱组成,对于每个食谱,首先提取其中提到的食物实体,然后使用层次式Hansard食品语义标签 (如,AG.01 [食物], AG.01.h.02 [蔬菜],AG.01.h.02.i [药草],AG.01.n.15[糕点] ,AE.10 [鱼])进行注释。FoodBase语料库的可用性使得第一个基于食品语料库的NER得以发展,即食品命名实体识别(BuTTER)。
由于2019年底发布的几种食物资源的可用性,我们引入了一个可用于食物信息提取的微调BERT模型,称为FoodNER。它是使用预定义的BERT模型开发的,该模型可以是原始BERT或BioBERT的某些变体。使用它们,对FoodBase语料库进行微调,以解决几个不同的任务:食品或非食品实体和4种可区分的食品实体,取决于获取语义标签的语义资源。FoodNER的流程图如图1所示。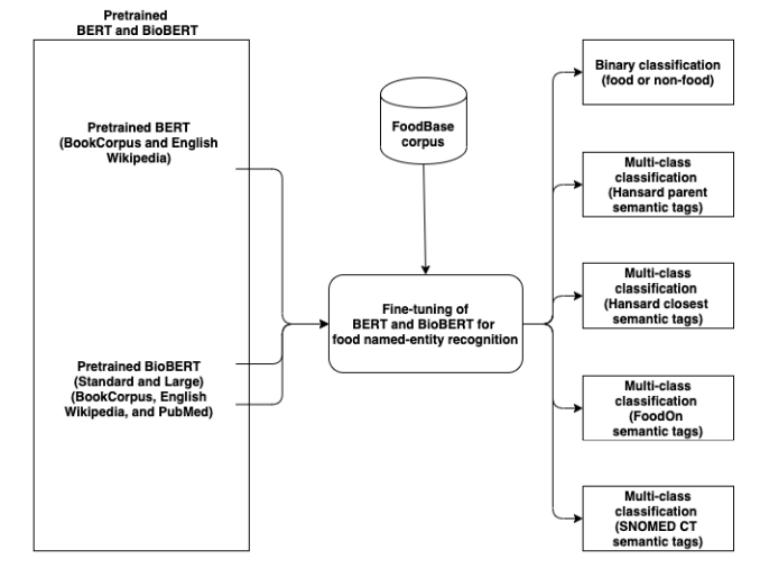

Figure 1. 食品命名实体识别流程图。
在本研究中,我们使用FoodBase ground truth语料库建立和评估FoodNER模型,用于区分食品与非食品实体,以及区分与Hansard语义标签相关的食品实体。
2.方法
FoodBase语料库的数据
FoodBase数据语料库是一个最近发布的语料库,包含食品标注。它包括两个版本:策划和非策划。这是第一个有注释食品实体的语料库。
食物语义资源
①Hansard语料库是SAMUELS(用于增强词汇搜索的语义注释和标记)项目的一部分。
②FoodOn是一个关于食品的从农场到餐桌的本体论,支持食品可追溯。它包括关于食品的信息、来源、保存过程和包装等信息。
②SNOMED CT是最全面的多语种临床医疗术语。它是一个机器可读的医学术语集合,其中每个代码都有同义词和临床定义。
④FoodOntoMap是一个最近发布的资源,它是使用FoodBase语料库开发的。它根据不同的语义资源提供食品实体的数据规范化。
⑤BERT是一个词表示模型,在许多NLP(自然语言处理)任务中实现了最先进的结果。BERT的主要思想是对变压器进行双向训练,BERT使用掩码模型,它预测按随机顺序掩码的单词,它用于双向表示学习。
⑥预先训练的BETR,BioBERT被用于改进包含大量生物医学领域专有名词和术语的任务模型。
⑦为了执行食物NER,我们对原始BERT和BioBERT模型的两个版本进行了微调。在所有情况下,对于每个类,我们都使用IOB(内部、外部和开始)标记预测,在这个过程中,我们使用FoodBase语料库作为ground truth。
⑧比较基线BuTTER,比较结果双向长期短期记忆(LSTM)模型与CRF层序列标签(BiLSTM-CRF)被用作基线,已达到先进的结果显示在几个NLP任务,如词性标注,分块,NER任务。
3. 结果
实验
我们进行了2个实验:(1)比较了BERT模型和基于语料库的BuTTER模型,该模型在之前的研究中提出了食物和非食物实体任务;(2)给出BERT模型的结果,可以区分不同的食品语义标签。
实验设计
实验采用Colab平台进行。在微调训练期间,使用AdamW优化器的weight_decay_rate为0.01。对模型进行训练,直到其验证损失在连续5个周期内没有改善为止,最大值为100个周期,并在整个周期内使用调度程序线性降低学习率。图2显示了Hansard父数据集上大BioBERT模型每次微调时期的训练和验证损失。
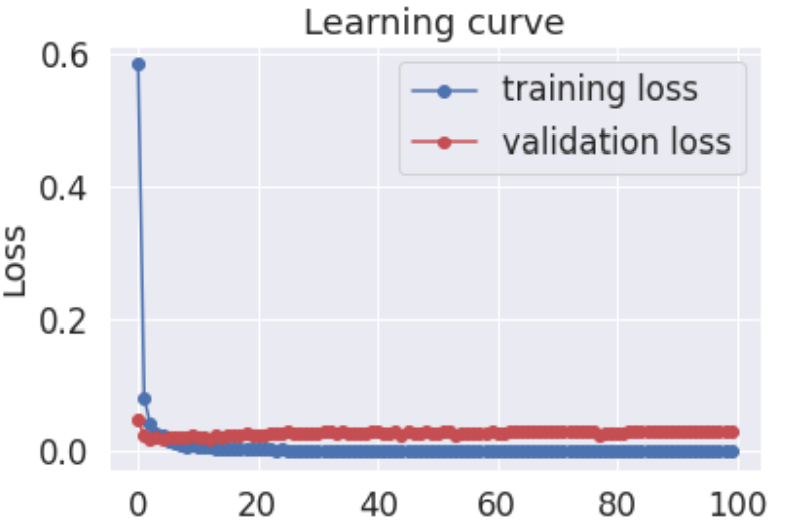
Figure 2.Hansard父数据集上的大BERT模型在每个微调时期的训练和验证损失
用于培训和测试的数据集来自FoodBase的策划版本,转换为IOB标签格式。列车部分包含81,347个令牌,而我们用剩余的25,828个令牌报告结果,即: 大约75%的数据用于训练,其余的用于模型测试。表1显示了不同数据集中关于令牌数量及其类的统计信息,该表中的“不同的内部、外部和开始注释的数量”行描述了我们的模型试图预测的类。采用分层五倍交叉验证对提出的模型进行评价。
Table 1. 数据集的统计数据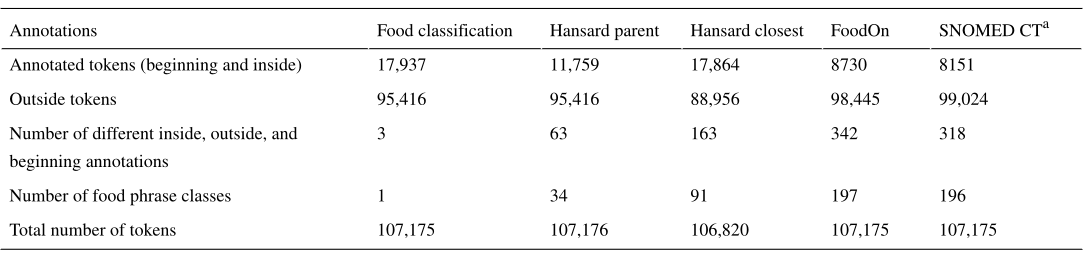
实验结果
图3展示了通过在Methods中描述的食品与非食品任务中使用原始预训练BERT模型和2个BioBERT模型来评估微调BERT(即FoodNER)所获得的结果,并将它们与相同任务中获得的BuTTER结果进行比较,所有FoodNER模型通过使用分层5倍交叉验证有更好的宏观F1分数。为了探索模型的稳健性,图4展示了通过分别评估每个模型的每个折叠得到的宏观F1分数分布的箱线图。由此可见,FoodNER模型(经过微调的BERT、BioBERT标准和大型BioBERT模型)提供了非常可靠的结果,这些结果也表明,使用BERT技术可以获得食品分类的最新结果。
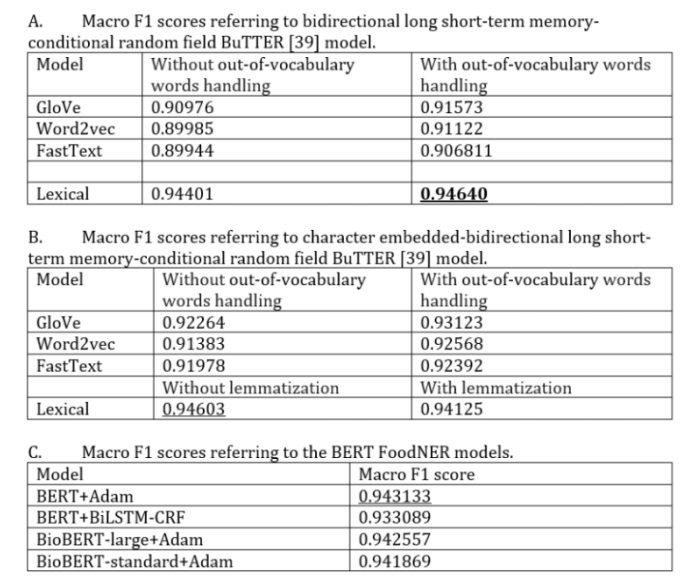
Figure 3.宏观F1得分为所有考虑的模型的食品与非食品实体任务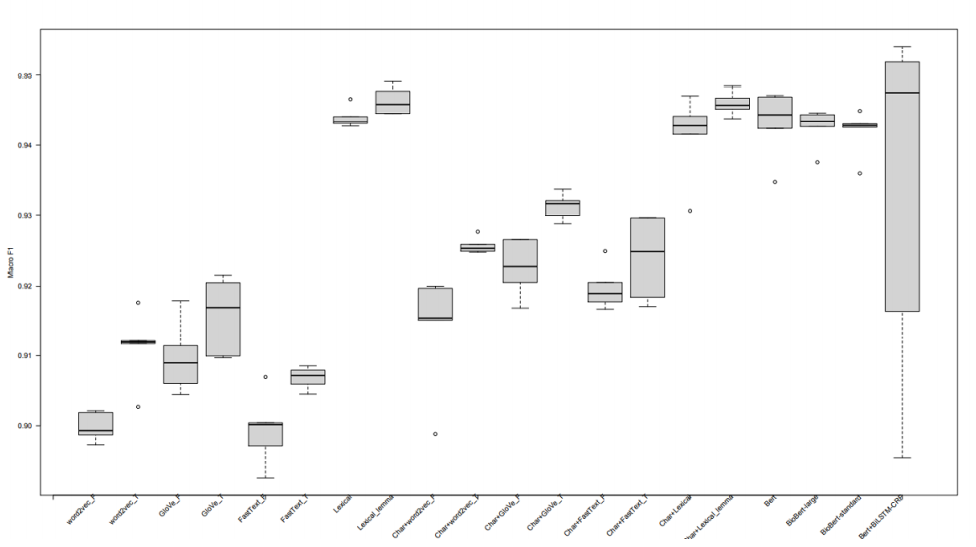
Figure 4. 对二元食物分类任务的所有考虑模型使用分层五重交叉验证获得宏观F1分数的箱形图
4. 结论
文中提出了一种基于语料库的食品信息提取方法FoodNER。在未来,FoodNER方法可能应用于该领域的任何其他注释语料库。它是通过使用3个先前发布的预定义BERT来表示语言模型(即原始BERT和2个BioBERTs; standard and large)。该模型提供了非常有前景的结果,在食品与非食品实体任务中,宏观F1得分约为93.30%-94.31%,在识别更多语义标签的任务中,宏观F1得分约为73.39%-78.96%。拥有像FoodNER这样强大的、最先进的食品信息提取方法,将允许进一步研究食品-药物和食品-疾病的相互作用,从而提供一个开始构建食品知识图的机会,包括与健康相关实体的关系。
参考文献
- Stojanov Riste, et al.”A Fine-Tuned Bidirectional Encoder Representations From Transformers Model for Food Named-Entity Recognition: Algorithm Development and Validation..” Journal of medical Internet research 23.8(2021): doi:10.2196/28229.
原创文章,作者:ifyoung,如若转载,请注明出处:https://www.drugfoodai.com/bert1.html
注意:本站原创指的是原创编译,并不主张对所介绍的工作的版权,如有侵权,请联系删除!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 相关推荐
-
ACS Omega:当机器学习和深度学习成为食品化学中的大数据
撰文:梁瑞 编辑:肖冉 今天给大家介绍一篇由Tseng等人,于2023年4月发表在ACS Omega上的(JCR分区:4.132/Q2)一篇综述性文章。该综述重点介绍了一些著名的食…
-
基于质谱-机器学习技术的番茄分类:一个食品安全增强平台
今天介绍一篇由Arthur Noin de Oliveira等人于2022年8月发表在Food Chemistry(IF=9.231)上的文章。该研究旨在开发一个使用机器学习算法的平台,分析质谱数据,对番茄进行有机和非有机的分类。决策树算法被定制用于数据分析,该模型在确定每种水果属于哪个组时达到了92%的准确度、94%的灵敏度和90%的精确度。
-
Food Chemistry|深度学习在基于图像的中国市场食品营养估计中的应用
该研究在视觉识别任务中利用了深度学习技术,并提出了一套大数据驱动的深度学习模型,从食物图像回归到营养估计,最大限度地发挥了深度学习模型的潜力,同时为未来将人工智能引入食品领域提供了基础。
-
FOOD CHEM|海南大学云永欢课题组:高光谱成像技术结合数据融合的罗非鱼鱼片新鲜度快速检测研究
该文研究了两种波段范围的高光谱成像系统(可见-近红外光谱(Vis-NIR)和近红外光谱(NIR))在冷藏期间测定罗非鱼鱼片中挥发性盐基氮(TVB-N)含量的潜力。利用Vis-NIR和NIR数据,建立了高光谱图像中罗非鱼鱼片平均光谱与其TVB-N含量之间的校正模型,并采用数据融合和多种变量选择方法对模型进行优化。最后,采用优化的模型来实现罗非鱼鱼片中TVB-N含量的可视化分布。结果表明,高光谱成像技术结合数据融合和变量选择等化学计量学方法在罗非鱼鱼片新鲜度无损评价分析中具有可行性。
-
智能食品加工:从人工神经网络到深度学习的旅程
人工神经网络在食品加工中的应用方面取得了巨大成功,如食品加工过程中分级、安全和质量检查等。今天给大家介绍一篇来自印度的一篇发表在Computer Science Review上的题为《智能食品加工:从人工神经网络到深度学习的旅程》一篇综述,该文分三个单元介绍给大家:(一)智能食品加工中的各类人工神经网络、(二)基于人工神经网络(ANN)的智能食品加工、(三)基于深度学习(DL)的智能食品加工。本文介绍综述中的第一个单元:(一)智能食品加工中的各类人工神经网络。
-
JCIM: 填补化学生物学空白:生物活性食品化合物靶点空间的系统分析和预测
今天介绍一篇由Andrés Sánchez-Ruiz和Gonzalo Colmenarejo于2022年8月在线发表在Journal of Chemical Information and Modeling上的文章。文章使用化学信息学统计模型 [相似性集成方法 (SEA),结合最大 Tanimoto 系数 (TC),标记为”SEA + TC”]预测与人类靶点的相互作用,并根据靶点类别和化合物类别、有利与不利的组合、丰富的支架以及与已发表的数据进行比较来分析结果。
-
食品安全中的人工智能技术: 基于行为数据的方法
今天介绍一篇由加拿大圭尔夫大学Arrell食品研究所Katya Kudashkina等人于2022年5月发表于 Trends in Food Science & Technology (IF:12.56)的一篇文章。文中所述,食品安全管理系统(FSMSs)提供了一个包括程序、培训和监控的综合策略,以防止食品安全危害,并将风险和召回降至最低。FSMSs的有效性和效率通过对滞后指标和领先指标的加强而提高。本篇文章展示了AI如何利用行为数据来开发食品安全的领先指标。
-
FRONT NUTR:通过化学信息学方法从蓝莓中计算筛选抗阿尔茨海默病的新神经保护成分
今天介绍一篇由中南林业科技大学张琳教授团队发表的一篇研究性论文,由肖冉等人于2022年12月发表在国际营养学TOP期刊Frontiers in Nutrition上(JCR:Q1 IF:6.59)。本文尝试设计一种基于化学信息学方法这种有效的智能筛选模式,从蓝莓中寻找抗阿尔茨海默病(AD)的新型有效成分,并通过实验验证了预期成分的生物活性。该方法集成了先进的人工智能和化学信息学方法,实现了对所有成分的逐步分析和过滤。最后,获得了预期的新化合物氯化锦葵色素-3-O-半乳糖苷(Ma-3-gal-Cl)。这篇文章采用的创新性方法为。这项工作采用的筛选策略能够为研究者从天然产物和食物中筛选活性成分提供新的参考。
-
利用机器学习算法基于天气和水管理信息构建黑皮诺香气特征模型
今天给大家介绍一篇由Sigfredo Fuentes等人合作,发表在Foods上的一篇有意思的文章,文章中作者介绍了一种基于天气和水管理信息的人工神经网络(ANN)模型预测黑皮诺(Pinot Noir)的香气特征。
-
中国农业大学周欣团队基于宏基因组学和机器学习的蜂蜜产品溯源
今天介绍一篇来自中国农业大学昆虫学系周欣教授课题组于2022年3月发表在Food Chemistry上的文章。该文为了查询蜂蜜的地理来源,收集蜂蜜样本产生的宏基因组数据,应用机器学习方法来推断蜂蜜的地理来源。